Fernsehtechnik - Vom Studiosignal zum DVB-Sendesignal
Die Fernsehtechnik umfasst den Weg vom Studiosignal bis hin zum DVB-Sendesignal. Dieser Artikel bietet einen Überblick über die Entwicklung und Anwendung verschiedener Techniken in diesem Bereich. Beginnend mit der Geschichte der Fernsehtechnik wird das Prinzip der Bildübertragung untersucht. Es werden Themen wie die trägerfrequente Übertragung von analogem Bild- und Tonsignal, die Datenreduktion beim digitalen Videosignal und Audiosignal sowie die Video- und Audio-Codierung nach dem MPEG-Standard behandelt. Zudem werden Aspekte wie die Übertragung des MPEG-2-Transportstroms, die digitale Trägermodulation und die Übertragung des DVB-Signals im Satelliten-, Kabel- und terrestrischen Funkkanal beleuchtet.

Inhaltsverzeichnis:
„Schon digital - oder noch analog” werden heute Fernsehprogramme übertragen. Die vorangehende 3. Auflage des Buches „Fernsehtechnik” war eigentlich im wesentlichen auf die zukünftige Technik der digitalen Fernsehsignalverteilung orientiert. Manche Leser aber waren enttäuscht, dass dabei die Übertragungsverfahren für das analoge PAL-Signal nur kurz oder überhaupt nicht mehr behandelt wurden.
Der Abschnitt über das analoge Video-Quellensignal wurde deshalb, wie in vorangehenden Auflagen, durch Erläuterungen über den PAL-Coder und -Decoder sowie über das PALplus-System ergänzt. Im Weiteren wird die trägerfrequente Übertragung des analogen Bild- und Tonsignals im terrestrischen Funk- und Kabelkanal sowie im Satellitenkanal beschrieben. Derzeit ist davon auszugehen, dass die endgültige Abschaltung der noch analogen terrestrischen Fernsehsender in Deutschland spätestens im Jahr 2010 erfolgen wird. In den Kabelnetzen und über einige Satelliten-Transponder werden darüber hinaus sicher noch analoge Fernsehprogramme übertragen. Damit sei es gerechtfertigt, dass in dieser Auflage nochmals die analoge Fernsehsignalverteilung erscheint.
Die bevorstehenden technologischen Neuerungen bei der Fernsehprogrammverteilung werden mit der Einführung von hochauflösendem Fernsehen, HDTV, verbunden sein. Treibende Kraft ist dabei das immer breitere Angebot an großflächigen Flachbildschirmen mit LCD- oder Plasma-Display-Technik. Obwohl in Europa noch keine endgültigen Standards festgelegt sind, so kann doch, basierend auf „De facto”-Standards, von dem 1920 x 1080-HD-Format (1080 aktive Zeilen) mit Zeilensprung-Abtastung, aber wahrscheinlich auch von einem 1280 x 720-Format (720 aktive Zeilen) mit progressiver Abtastung ausgegangen werden. Dem hochauflösenden Fernsehen wurde deshalb beim digitalen Studiosignal mehr Bedeutung zugeordnet.
Die rasche Entwicklung der Digitaltechnik in Verbindung mit immer schnelleren Schaltkreisen blieb nicht ohne Einfluss auf die Fernsehtechnik. Sowohl im Studiobereich, bei der Bearbeitung von Programmsignalen, als auch bei der Signalverarbeitung im Fernsehempfänger kamen im Laufe der letzten Jahrzehnte zunächst inselweise, sukzessive aber immer mehr digitale Schaltungen und Systeme zum Einsatz. Diese erforderten in einem analogen Umfeld als Interface stets eine Analog-Digital- bzw. Digital-Analog-Wandlung.
Es war deshalb naheliegend, dass ein digitaler Standard für das Video-Studiosig- nal erarbeitet wurde, der im Jahr 1981 durch das CCIR (Commite Consultatif International des Radiocommunications) als Empfehlung 601 verabschiedet worden ist. Die hohen Anforderungen im Studio bedingten bald einen Übergang von der ursprünglich festgelegten 8-bit-Codierung auf eine 10-bit-Codierung, womit sich nun eine Datenrate von 270 Mbit/s für das aus den Komponenten zusammengesetzte digitale Multiplexsignal nach CCIR-Empfehlung 656 ergab.
Für den Programmaustausch und auf den Zubringer-Leitungen waren dazu breitbandige Übertragungssysteme notwendig, jedoch mit einer Datenrate, die von der bei den üblichen SDH- und ATM-Plierarchien abweicht. Es wurden Datenreduktionsverfahren für das Bild- und Tonsignal entwickelt, die ohne wahrnehmbaren oder wesentlichen Qualitätsverlust zu einer Datenrate führen, mit der es wiederum möglich ist, installierte SDH- oder ATM-Breitbandsysteme auf den Contributions-Strecken zu benutzen.
Mit einer weiteren Reduktion der Datenrate, die zunächst nur für Multimediazwecke gedacht und gemäß den Vorschlägen der Moving Pictures Expert Group in dem so genannten MPEG-1-Standard niedergeschrieben war, und mit der nachfolgenden Anpassung auf die Parameter und Vorgaben des Rundfunk-Fernsehsignals im MPEG-2-Standard eröffnete sich die Möglichkeit, digitale Video- und Audiosignale auch über herkömmliche Fernsehkanäle zu verteilen. Damit wurde das Startsignal für das „digitale Fernsehen“ bis zum Teilnehmer hin gegeben.
Als Verfasser schätze ich mich glücklich, dass ich mit der Entwicklung der Fernsehtechnik aufwachsen durfte. Durch meine langjährige Tätigkeit in der Lehre an der Hochschule und mit Industrieseminaren sowie engen Kontakten zu Entwicklungsstellen bei Industrie und beim Institut für Rundfunktechnik hat sich ein umfangreiches Wissen angesammelt. Dieses soll nun in der 3. Auflage der „Fernsehtechnik“ mit dem Untertitel „Vom Studiosignal zum DVB-Sendesig- nal“ niedergeschrieben und dem interessierten Leser nahe gebracht werden.
Der an Technikgeschichte interessierte Leser findet in einer kurzen Zusammenfassung die Entwicklung der Fernsehtechnik von den Anfängen bis zur nahezu zwangsläufigen Einführung des digitalen Fernsehens in den vergangenen Jahren. Die noch nicht oder nicht mehr mit den Grundlagen des analogen Fernsehens vertraut sind, werden in einem einführenden Abschnitt die wesentlichen Abläufe und Parameter des analogen Video-Quellensignals erläutert.
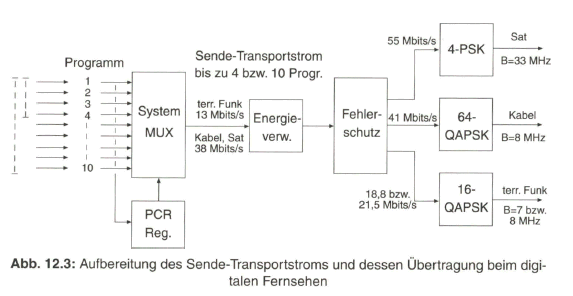
Der Schwerpunkt dieses Buches liegt aber beim „digitalen Fernsehen“. Nach der Aufbereitung des digitalen Studiosignals mit der schon eingangs angesprochenen Datenrate von 270 Mbit/s werden Verfahren zur wirksamen Datenreduktion beim Videosignal behandelt, die auf einer Redundanz- und Irrelevanzreduktion beim Quellensignal basieren. Dazu wird es erforderlich, das zeilengebundene Video- Quellensignal neu zu unterteilen, wobei bereits auf die von MPEG-2 vorgegebene Hierarchie im Datenstrom Bezug genommen wird. Die vom MPEG-2-Video- und auch -Audio-Coder gelieferten Daten werden in Paketen gebündelt und in die Syntax des MPEG-2-Systems eingebracht. Durch Multiplexen von Datenpaketen mit Video- und Audioanteilen entsteht der MPEG-2-Transportstrom. Dieser wird nach Einbringen von Fehlerschutzdaten dem Übertragungskanal zugeführt.
Nach einer Beschreibung der wichtigsten digitalen Modulationsverfahren wird im letzten Abschnitt auf die Übertragung des digitalen Fernsehsignals nach den DVB-Spezifikationen im Satellitenkanal (DVB-S), im Kabelverteilkanal (DVB-C) und im terrestrischen Funkkanal (DVB-T) eingegangen
1. Geschichte der Fernsehtechnik
„Fernsehen“ als ein Medium zur Verbreitung von Information und Unterhaltung an einen weiten Teilnehmerkreis gibt es weltweit seit etwa 50 Jahren. Die ersten Anfänge reichen in Deutschland sogar bis 1936 zurück, als anlässlich der Olympischen Sommerspiele in Berlin bereits Sportübertragungen im öffentlichen Fernsehen mit einer Auflösung des Bildes in 441 Zeilen stattfanden.
Deutschland, 1936: 441 Zeilen, 50 Halbbilder pro Sekunde
Kriegsbedingt stagnierte die Entwicklung in Europa, aber in den USA wurde schon 1940 von der CBS ein Farbfernsehsystem vorgestellt, bei dem die Farbzerlegung und Wiedergabe noch unter Zuhilfenahme von rotierenden Farbfilterscheiben für die mechanisch-optische Umschaltung der drei Farbkomponenten erfolgte. In Europa wurde 1950 von einem Expertengremium unter der Leitung des Schweizer Fernsehexperten WALTER GERBER eine Fernsehnorm mit 625 Zeilen und 50 Halbbildern pro Sekunde erarbeitet und 1952 vom CCIR (Comite Consultant International des Radiocommunications) als Standard offiziell angenommen.
Europa, 1952: 625 Zeilen, 50 Halbbilder pro Sekunde
Über einige Zeit konkurrierten damit noch der englische 405-Zeilen und der französische 819-Zeilen-Standard. All diesen Fernseh Standards, wie auch bereits beim ursprünglichen 441-Zeilen-Standard, ist das Zeilensprungverfahren gemeinsam. Die Rundfunkanstalten in der Bundesrepublik Deutschland starteten im Jahr 1952 mit der regulären Ausstrahlung von Schwarzweiß-Fernsehprogrammen nach der 625-Zeilen-Norm [1],
Nachdem in den USA Farbbildröhren verfügbar waren und das Farbfernsehsystem NTSC (National Television System Committee) zur Einführung kam, wurden auch in Deutschland Versuche mit der Übertragung von Farbfernsehsignalen unternommen, wobei neben dem NTSC-Verfahren auch das von WALTER BRUCH entwickelte PAL-Verfahren als ein verbessertes, weil gegen Phasenfehler unempfindliches, NTSC-ähnliches System, und das von HENRI DE FRANCE vorgestellte SECAM-Verfahren getestet wurden. Objektive Vergleiche wiesen aber dem PAL-Verfahren die besten Eigenschaften zu.
So kam es in der Bundesrepublik Deutschland am 25. August 1967 zur offiziellen Einführung des Farbfernsehens mit dem PAL-Verfahren. Viele Länder der Erde, mit 625-Zeilen-Standard, entschieden sich im Folgenden für die Einführung des PAL-Farbfernsehsystems.
Deutschland (und weltweit), 1967: PAL-Farbfernsehsystem
Geringe Abweichungen einzelner Parameter oder auch unterschiedliche HF- Kanalbandbreiten (7 bzw. 8 MHz) beim 625-Zeilen-Standard sowie das in Nordamerika und Japan eingeführte NTSC-System mit 525-Zeilen-Standard und das SECAM-System wurden in den CCIR-Standard 624 aufgenommen.
Im Laufe der Zeit offenbarten sich dem kritischen Beobachter des nach dem PAL-Verfahren übertragenen Farbfernsehbildes auch hier wieder gewisse Schwächen des Systems, insbesondere durch Übersprecheffekte, bedingt durch das Frequenzmultiplex-Prinzip mit den verkämmten Spektren von Luminanz und Chrominanzsignal. Eine Abhilfe konnte durch so genannte Mehrzeilen-Laufzeit-Decoder beim PAL-Empfänger geschaffen werden, die aber wiederum andere Mängel mit sich brachten. Eine andere Möglichkeit bot sich in dem Übergang auf das Zeit-multiplex-Prinzip. Mit diesem ist eine Zeitkompression der zu übertragenden Signale, sinnvoller Weise nur mit digitaler Technik realisierbar, verbunden.
Anfang der 1980er-Jahre kam es zur Entwicklung eines analogen Zeitmultiplex systems mit dem Namen MAC (Multiplexed Analogue Components), das aber bereits bei der Aufbereitung des Studioausgangssignals und bei der empfängerseitigen Verarbeitung mit digitaler Schaltungstechnik verknüpft war. Gefordert wurde eine volle Kompatibilität in den verfügbaren HF-Übertragungskanälen, was weitgehend erfüllt werden konnte. Darüber hinaus konnte kompatibel auf das 16:9-Breitbildformat umgeschaltet werden und ein abwärtskompatibler HDTV-Fernseh-Standard HD-MAC war, zumindest bedingt, möglich.
Europa, 1983: beabsichtigte und in Probephase bereits realisierte Einführung des MAC-Verfahrens
Die Investitionen auf der Studioseite und insbesondere beim Fernsehteilnehmer, mit der Notwendigkeit von zunächst einem Zusatzgerät oder später einem auf das neue Verfahren ausgelegten Fernsehempfänger, waren jedoch zu hoch, so dass das MAC-bzw. HD-MAC-Verfahren vom Fernsehteilnehmer nicht angenommen wurde und damit, trotz deutsch-französischer Regierungsvereinbarung, nicht zur tatsächlichen Einführung kam.
Indirekt profitiert hat von dieser Entwicklung eine verbesserte Variante des PAL-Verfahrens mit Unterdrückung der Cross-Störungen und damit voller Ausnutzbarkeit der 5-MHz-Videobandbreite, das mit PAL kompatible Color-Plus-Verfahren. In Verbindung mit der kompatiblen 16:9-Breitbildübertragung ist dieses im PALplus- System integriert. Das PAL-plus-System kommt in Deutschland bei den öffentlich rechtlichen Rundfunkanstalten weitestgehend zum Einsatz und wird neben dem Standard-PAL-System bis zum Auslaufen der PAL-Ära eingeführt bleiben.
Deutschland, 1991: Einführung des PAL-plus-Systems
Im Studiobereich vollzog sich bereits ab Mitte der 1980er-Jahre eine allmähliche Umstellung auf die digitale Komponententechnik. Voraussetzung war die Definition eines digitalen Studio-Standards, der im Jahr 1981 vom CCIR mit der Rec. 601 und Rec. 656 festgelegt wurde und nun weltweite Gültigkeit durch Anpassung an das 525-Zeilen-System mit 60 Hz und an das 625-Zeilen-System mit 50 Hz erlangte. Das frühere CCIR (Comite Consultatif International des Radio communications) ist seit Dezember 1992 durch Neuorganisation in die Internationale Fernmeldeunion ITU (International Telecommunication Union), Section Radio (ITU-R) übergegangen.
Weltweit, 1981: Digitaler Studio-Standard
Ursprünglich war 8-bit-Codierung mit einer Brutto-Datenrate von 216 Mbit/s vorgesehen. Aus den Erfahrungen im Studiobereich ergab sich die Notwendigkeit, auf eine 10-bit-Codierung mit der Brutto-Datenrate von 270 Mbit/s überzugehen. Sowohl schon bei der „Contribution“ auf den Verbindungs- und Zubringerleitungen zwischen den TV-Studios und den Senderstandorten als auch bei der „Distribution“ zum Fernsehteilnehmer hin, war eine Reduktion der zu übertragenden Datenrate erforderlich, natürlich mit der Vorgabe, dass damit keine wahrnehmbare Qualitätsverminderung verbunden ist.
Auch zur Speicherung von digitalen Fernsehsignalen im Studio bis hin zum Consumer-Bereich war eine Datenreduktion notwendig. Angestrebt wurde nun wieder ein weltweiter Standard für datenreduzierte Video- und Audiosignale. Dazu wurde eine Expertengruppe beauftragt, die bereits vorangehend eine Empfehlung für die Codierung bei der Festbildübertragung erarbeitet hat, bekannt unter dem Namen JPEG (Joint Pictures Expert Group). Die Ausweitung auf Bewegtbilder und Begleitton führte zu dem Ergebnis des MPEG-1-Standards (Moving Pictures Expert Group) für Multimedia-Anwendungen und Speicherung auf einer Compact Disc (CD) mit einer Datenrate von maximal 1,5 Mbit/s.
Weltweit, 1993: MPEG-1 -Standard für Multimedia
Basierend auf reduzierter Rasterauflösung mit 352 x 288 Pixel für Luminanz und einer geringeren Farbauflösung, mit progressiver Abtastung und einer Bildwiederholfrequenz bis 30 Hz war dieser Standard jedoch nicht für eine Anwendung beim Fernsehen geeignet, obwohl mit modifizierten Versionen 1994 die ersten Satellitenübertragungen mit dem DSS-Standard in den USA abgewickelt wurden.
Weltweit, 1994: MPEG-2-Standard für Rundfunk-Fernsehen
Erst mit dem MPEG-2-Standard kam der Durchbruch zum digitalen Rundfunk- Fernsehen. Volle Bildauflösung übernommen vom digitalen Studio-Standard mit 720 x 576 Pixel für Luminanz und 360 x 576 Pixel für Chrominanz sowie die Möglichkeit, neben der progressiven Abtastung auch mit dem Zeilensprungverfahren zu arbeiten, wurden als Vorgaben erfüllt. Abhängig von der Zeilenzahl und Chrominanzauflösung, bei MPEG-2 nun ausgedrückt durch die „Levels“ und „Profiles“, wurden Obergrenzen für die Datenrate des komprimierten Videosignals zwischen 4 Mbit/s für reduzierte Auflösung, über 20 Mbit/s für Standard-TV bis zu 100 Mbit/s bei hochauflösendem Fernsehen HDTV, festgelegt. Mit effektiven Datenkompressionsverfahren wird praktisch nur etwa ein Viertel dieser Werte oder weniger benötigt. Damit waren die Voraussetzungen geschaffen, um digitale Fernsehsignale mit geeigneten Modulationsverfahren über die gegebenen TV-Verteilkanäle dem Fernsehteilnehmer zuzuführen.
Ein gewisser Wettlauf entstand zwischen den USA, wo man sich schon früher als in Europa für die Entwicklung eines digitalen Fernsehsystems sogar mit der Vorgabe von HDTV entschieden hatte, und der Entwicklung in Europa, wo nach Expertengesprächen innerhalb der European Launching Group im September 1993 das europäische DVB-Projekt gestartet wurde. Die vom Technical Module des DVB-Projektes als erstes verabschiedete Systemspezifikation für den Satellitenkanal wurde im November 1994 vom europäischen Normungsinstitut ETSI zum European Telecommunication Standard ETS 300 421 (DVB-S) erklärt. Es folgte die Spezifikation für DVB-Kabelübertragung (DVB-C) und später für Digitales Terrestrisches Fernsehen (DVB-T) mit Ausstrahlung in Gleichwellennetzen.
Europa, 1995: DVB-Standard für Satelliten-, Kabel- und terrestrischen Funkkanal
In Europa startete 1996 das digitale Fernsehen über Satellitenkanäle. Neu ist, dass nun über einen Transponderkanal gleichzeitig bis zu zehn Standard-TV-Programme übertragen werden, im Gegensatz zu nur einem durch Frequenzmodulation übertragenen Programmsignal bei analogem Fernsehen. Ein solches „Bouquet“ aus mehreren Programmen kann im Allgemeinen auch über einen Kabel-TV-Kanal dem Fernsehteilnehmer zugeführt werden. Das Digitale Terrestrische Fernsehen wurde in Europa bereits 1998 in England flächendeckend eingeführt. In Deutschland erfolgte nach einer Testphase in Berlin-Potsdam in den Jahren 2002 und 2003 mit simultaner Ausstrahlung ab der zweiten Jahreshälfte 2003 die abrupte Umstellung von analogem auf digitales terrestrisches Fernsehen unter dem Slogan
„DVB-T: Das ÜberallFernsehen“
inselweise in Ballungsräumen, mit Start in Berlin und Potsdam und bis Ende 2005 über das Bundesgebiet verstreut, mit weit reichenden Abdeckungen des Versorgungsgebiets.
Laut Beschluss der deutschen Bundesregierung vom 24. August 1998 soll bis zum Jahr 2010 in Deutschland der Hör- und Fernseh-Rundfunk von der analogen auf digitale Technik umgestellt werden. Analoge TV-Übertragungen über terrestrische Sendernetze werden dann eingestellt. Zur Jahresmitte 2000 waren in Deutschland nur etwa 5 % der Haushalte zum Empfang von digitalem Fernsehen, über Satellit oder Kabel, eingerichtet [3]. Zwischenzeitlich dürfte dieser Wert aber durch die weitgehende Einführung des digitalen terrestrischen Fernsehens in den Ballungsgebieten bei über 20 % liegen.
Die weitere Entwicklung wird geprägt sein durch das hochauflösende Fernsehen HDTV. Während in den USA und Japan sowie in Australien bereits seit einigen Jahren in verschiedenen Kanälen HDTV-Programme ausgestrahlt werden, verläuft die HDTV-Einführung in Europa noch etwas zurückhaltend, was mit dem geringen Interesse seitens der Fernsehzuschauer verbunden ist. Durch das immer breitere Angebot an Flachbild-Displays mit Bildschirmdiagonalen bis zu 120 cm und mehr zeichnet sich jedoch die Notwendigkeit einer höheren Zeilenauflösung, mindestens 720 oder 1080 aktive Zeilen, und ein Übergang auf progressive Bildabtastung ab. Die dadurch bedingten höheren Quellen-Datenraten sollen durch verbesserte Codierungsverfahren (MPEG-4 mit H.264-Codierung) und durch effektivere Übertragungsverfahren (DVB-S 2 im Satellitenkanal) beherrscht werden.
HDTV-Programm-Angebot über ASTRA-Satelliten-Transponder
Seit Mitte des Jahres 2006 gibt es über Satellitenkanäle die Möglichkeit HDTV-Programme frei oder in bestimmten Themengruppen (Film, Sport o.a.) über Extragebühren von einigen Anbietern zu empfangen. Premiere HD Film und HD Sport werden künftig auch im Kabelnetz von Kabel Deutschland (KDG) verteilt. Ein nächster Schritt in der Verbreitung von Fernsehprogrammen geht zum Mobilen Empfang von Fernsehen über „Handheld Terminals“.
Es handelt sich dabei um batteriebetriebene Geräte mit kleinem Bildschirm oder entsprechend eingerichtete Mobilfunkgeräte. Damit verbunden sind auch die Übertragungsstandards, die einerseits an die rundfunkmäßige Verteilung der Programme gekoppelt sind und mit dem System DVB-H über das terrestrische digitale Fernsehen oder mit dem System DMB über Digital Audio Broadcasting (DAB) beim digitalen Hörfunk oder andererseits die UMTS-Mobilfunknetze benutzen. Davon abhängig ist auch das Programmangebot, das aus dem herkömmlichen Fernsehangebot entnommen sein kann oder spezielle, eigens aufbereitete Informationen beinhaltet.
2. Prinzip der Bildübertragung
„Fernsehen“ als ein Übertragungsverfahren der elektrischen Nachrichtentechnik beruht auf der Umwandlung der Helligkeits- und Farbverteilung einer Bildvorlage in ein entsprechendes elektrisches Signal, das leitungsgebunden oder auf dem Funkweg dem Empfangssystem zugeführt und dort wieder in ein äquivalentes optisches Bild umgewandelt wird. Sowohl von der Historie als auch von der Technik her baut das Fernsehen auf der Übertragung und Wiedergabe von Schwarzweißbildern, also der Helligkeitsverteilung der Bildvorlage, auf.
Über ein optisch-elektrisches Wandlersystem wird dazu von den einzelnen Bildelementen, den Bildpunkten oder Pixeln, nacheinander in bestimmter Reihenfolge ein elektrisches Signal erzeugt. Aus der zweidimensionalen, geometrischen Zuordnung der Bildpunkte leitet sich so durch den Vorgang der Bildabtastung ein zeitabhängiges elektrisches Signal ab, dessen Momentanwert der Helligkeit des gerade abgetasteten Bildpunktes proportional ist. Empfangsseitig wird, nach entsprechender Aufbereitung, das elektrische Signal einem elektrisch-optischen Wandler, der Fernsehbildröhre, zugeführt und als ein Abbild der Helligkeitsverteilung der Bildvorlage wiedergegeben (Bild 2.1).
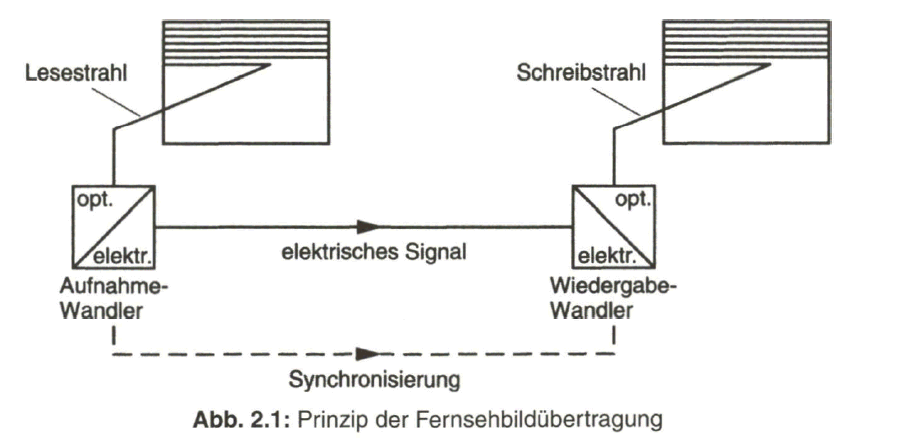
In der prinzipiellen Darstellung nach Bild 2.1 wird der Einfachheit halber noch von einem „Lesestrahl“ und von einem „Schreibstrahl“ gesprochen. Tatsächlich werden schon lange für die Bildaufnahme vakuumlose Halbleiter-Zeilen- (bei der Filmabtastung) oder -Flächen-Sensoren (bei Fernsehkameras) verwendet. Die Zuordnung des „Lesestrahls“ erfolgt nun über die sequentielle Abtastung der Bildpunkte, deren Helligkeitsverteilung als Ladungsbild in eine CCD-Speicheranord- nung übertragen wird. Die Ladungsverteilung wiederum wird zeilenweise ausgelesen. Die Bildwiedergabe geschieht noch weitgehend mit Fernsehbildröhren mit einem Elektronenstrahl im Hochvakuum. Aber zunehmend mehr an Bedeutung gewinnen Flachbild-LCD- oder -Plasma-Displays, bei denen die Bildwiedergabe zeilenweise über adressierbare Bildpunkte erfolgt.
2.1.1 Bildabtastung
Die Abtastung der Bildvorlage durch den Lesestrahl läuft zeilenweise ab, wobei der Lesestrahl gleichzeitig horizontal von links nach rechts und vertikal von oben nach unten abgelenkt wird. Der Vorgang lässt sich mit der Bewegung des Gesichtsfeldes beim Lesen eines Textes von links nach rechts längs der Textzeilen und mit dem raschem Zurückspringen auf den Beginn der nächstfolgenden Zeile vergleichen. Vom Ende der letzten Zeile am unteren Bildrand wird der Abtaststrahl zum Ausgangspunkt am linken oberen Bildrand zurückgeführt und das Zeilenraster wiederholt durchlaufen. Die Ablenkung des Lese- bzw. Schreibstrahles in der horizontalen und vertikalen Richtung und die sich damit ergebende Rasterstruktur zeigt Bild 2.2.
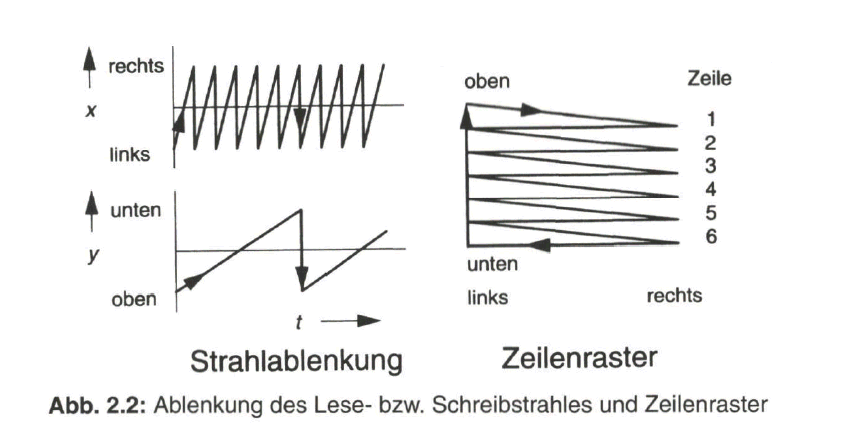
Tatsächlich werden als optisch-elektrische Aufnahmewandler heute nur noch Halbleiter-Sensoren mit CCD-Technik (CCD: Charge Coupled Device) verwendet, bei denen die Abtastung in den Zeilen diskret in den einzelnen Bildpunkten erfolgt. Auch beim elektrisch-optischen Wiedergabewandler findet man bereits Flachbildschirme mit punktweiser Bildrekonstruktion. In beiden Fällen werden die Bildpunkte von adressierbaren Steuersignalen angesprochen. Damit sich der Lesestrahl und der Schreibstrahl gleichzeitig in richtiger Zuordnung über die Bildfläche bewegen bzw. damit bei der bildpunktweisen Aufnahme und Wiedergabe jeweils gleiche Bildpunkte zugeordnet werden, müssen geeignete Synchronisierzeichen übertragen werden.
2.1.2 Zeilenzahl
Die Qualität der Bildübertragung wird durch die Auflösung des Bildes, d. h. durch die Anzahl der Zeilen und Bildpunkte in der Zeile, bestimmt. Die Auflösung und damit die Bildschärfe ist umso besser, je höher die Anzahl der Bildpunkte pro Zeile (horizontale Auflösung) und je höher die Zeilenzahl (vertikale Auflösung) ist. Mit zunehmender Anzahl von Bildpunkten und Zeilen wachsen aber auch die Anforderungen an die Bandbreite des Übertragungssystems, so dass es gilt, einen vernünftigen Kompromiss zu finden.
Eine Mindestzahl von Zeilen ist notwendig, damit die Rasterstruktur des wiedergegebenen Bildes nicht störend in Erscheinung tritt. Diese kann jedoch nur im Zusammenhang mit den Abmessungen des Fernsehbildes und dem Betrachtungsabstand sowie dem Auflösungsvermögen des menschlichen Auges gefunden werden. Nach einer Näherungsformel erhält man für die mindestens notwendige Anzahl Zaktiv der auf dem Bildschirm sichtbaren Zeilen

wobei der Betrachtungsabstand und die Höhe des sichtbaren Bildes sind. Mit einem vernünftigen Wert von E/H = 5 ergibt sich eine mindestens notwendige Anzahl von aktiv = 500 sichtbaren Zeilen. Diesen Wert findet man annähernd auch in den eingeführten Standard-Fernsehsystemen.
Europäisches 625-Zeilen-System: 575 (analog) bzw. 576 (digital) aktive, d.h. sichtbare Zeilen
Amerikanisches 525-Zeilen-System: 485 (analog) bzw. 480 (digital) aktive, d.h. sichtbare Zeilen
2.1.3 Bild-Seitenverhältnis
Das Verhältnis von Bildbreite ßzur Bildhöhe H wurde vom ursprünglichen Kino- Bildformat mit
B/H = 4 : 3
übernommen. Beim Kinofilm gibt es aber mittlerweile fast 20 verschiedene Breitbildformate. Für das „kinoähnliche“ Fernsehbild, ursprünglich nur auf das hochauflösende Fernsehen HDTV bezogen, wurde in Europa ein Breitbildformat von
B/H =16 : 9
festgelegt, was einem Verhältnis von (4 : 3)- 4/3 bzw. 5,33 : 3 entspricht. Dieses „Breitbildformat“ wurde mittlerweile auch bei Standard-TV (SDTV), z.B. bei dem PALplus-System, eingeführt. Das Bild-Seitenverhältnis ist praktisch durch das Format der Bildwiedergaberöhre bestimmt. Bei Breitbildröhren kann durch eine geringere Horizontalablenkung auch ein 4 : 3-Bild wiedergegeben werden.
2.1.4 Bildwechselfrequenz
Die Übertragung einer Bewegtbildvorlage erfolgt ähnlich wie beim Kinofilm über eine Folge von einzelnen Teilbildern. Bei der Festlegung der Bildwechselfrequenz sind die physiologischen Eigenschaften des menschlichen Sehorgans zu berücksichtigen. Zunächst muss davon ausgegangen werden, dass zur Wiedergabe eines kontinuierlichen, schnellen Bewegungsvorgangs eine bestimmte Mindest- Teilbildfrequenz erforderlich ist, damit keine störenden Diskontinuitäten im Bild entstehen. Ein Wert von 16 Teilbildern pro Sekunde stellt hier die untere Grenze dar. Beim Kinofilm arbeitet man mit 24 Teilbildern pro Sekunde. Dieser Wert könnte auch beim Fernsehen übernommen werden, doch es wurde hier mit Rücksicht auf eine mögliche Verkopplung mit der Netzfrequenz (u. a. auch wegen der Beleuchtungstechnik mit Gasentladungslampen) eine Bildwechselfrequenz von

beziehungsweise von
![]()
gewählt. In den USA wurde der Wert bei der Einführung des Farbfernsehens geringfügig geändert von 30 Hz auf 29,97 Hz.
Eine Bildwechselfrequenz von 25 Hz oder 30 Hz reicht jedoch für eine flimmerfreie Bildwiedergabe nicht aus. Die subjektiv empfundene Flimmerstörung eines in der Helligkeit periodisch schwankenden Bildfeldes hängt von verschiedenen Faktoren ab. Dazu zählen die Frequenz der Helligkeitsschwankung und das Verhältnis Hell- zu Dunkelzeit. Die Flimmergrenzfrequenz, oberhalb der unter normalen Bedingungen kein Flimmern mehr wahrgenommen wird, liegt etwa zwischen 50 Hz und 60 Hz.
Dieses Problem lag auch schon bei der Einführung des Kinofilms vor und wurde durch eine Verdoppelung der Teilbildfrequenz gelöst. Über eine so genannte Flimmerblende wird die Projektion jedes Teilbildes einmal unterbrochen, wodurch der Eindruck der doppelten Bildwechselfrequenz entsteht. Bei der Einführung des Fernsehens konnte man noch nicht auf die heute mögliche Speicherung von Fernsehteilbildern zurückgreifen. Es musste eine andere Möglichkeit zur Erhöhung der Teilbildfrequenz gefunden werden.
2.1.5 Zeilensprungverfahren
Die Bildwechselfrequenz auf den doppelten Wert zu erhöhen wäre zwar eine Möglichkeit, um das Flimmern (weitestgehend) zu vermeiden. Es hätte aber gleichzeitig eine Erhöhung der notwendigen Übertragungsbandbreite um den Faktor zwei zur Folge. Schon sehr früh angestellte Versuche ergaben jedoch, dass die Bildwechselfrequenz auf kleine Bildbereiche bezogen relativ niedrig sein kann, wenn nur das Zeilenraster genügend oft geschrieben wird.
Gegenüber der so genannten progressiven Abtastung, wo gemäß der bisherigen Annahme die Zeilen aufeinanderfolgend abgetastet und geschrieben werden (Bild 2.3, links), erfolgt beim Zeilensprungverfahren (auch Zwischenzeilenverfahren genannt, engl, interlaced scanning) eine Aufteilung des gesamten Rasters in zwei Halbraster mit jeweils halber Zeilenzahl, die ineinander verschachtelt sind und die zeitlich nacheinander übertragen und geschrieben werden (Bild 2.3, rechts). In der Darstellung nach Bild 2.3 wird vereinfacht davon ausgegangen, dass das horizontale Zurücksetzen auf den Anfang der nächsten zu übertragenden Zeile sowie das vertikale Zurücksetzen auf den Anfang des nächsten zu übertragenden Vollbildes oder Halbbildes in vernachlässigbar kurzer Zeit geschieht.
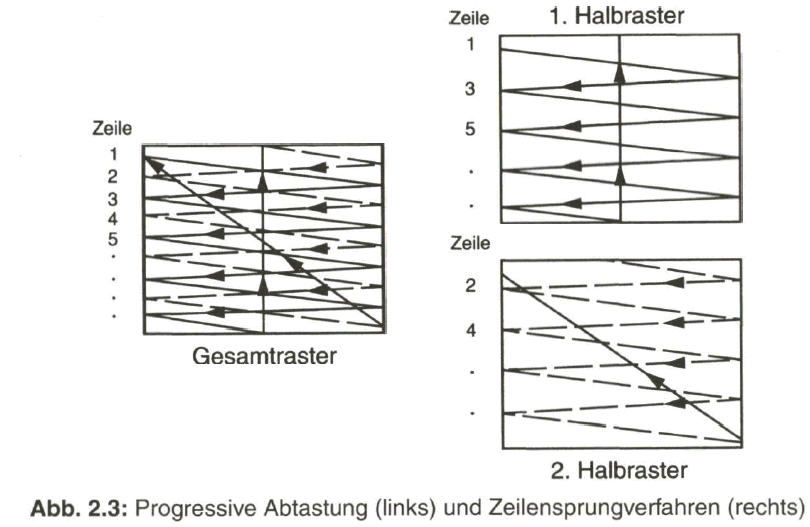
Der Wechsel vom ersten zum zweiten Halbraster erfolgt bei ungerader Zeilenzahl, zum Beispiel mit Z= 625, am Ende des ersten Halbrasters nach Durchlaufen einer halben Zeile, womit das zweite Halbraster mit der verbleibenden halben Zeile beginnt. Damit erübrigt sich ein besonderes Hilfssignal zum periodischen Versatz der beiden Halbraster und es ist stets die Voraussetzung geschaffen, dass die Zeilen des zweiten Halbrasters mittig in den Zwischenräumen des ersten Halbrasters liegen und somit ein gleichmäßig verteiltes Gesamtraster entsteht.
An Stelle von
25 Vollbildern pro Sekunde, engl. frames,
mit je 625 Zeilen bei dem europäischen Fernsehsystem und der
Bildwechselfrequenz fw = 25 Hz,
werden also
50 Halbbilder pro Sekunde, engl. fields,
mit je 312 1/2 Zeilen übertragen. Es ergibt sich somit eine
Halbbildwechselfrequenz,
auch als Rasterwechselfrequenz oder Vertikalfrequenz bezeichnet, mit
![]()
Die Periodendauer des Halbbildwechsels beziehungsweise die Periodendauer der Vertikalablenkung, engl. field duration beträgt
![]()
Ein heute neu zu definierendes Fernsehsystem würde, wie auch beim Computer- Monitor, mit progressiver Abtastung arbeiten. Mit Rücksicht auf die eingeführten und installierten Geräte und Systeme kann jedoch keine abrupte Umstellung von Zeilensprung-Abtastung auf progressive Abtastung erfolgen. Wie später angeführt wird, bietet aber das digitale Fernsehen die Möglichkeit, auch auf progressive Abtastung überzugehen, was z.B. bei den digitalen Standards in den USA schon ausgenützt wird.
2.1.6 Zeilenfrequenz
Die Zeilenwechselfrequenz oder Zeilenfrequenz, auch Horizontalwechselfrequenz ![]() genannt, engl. line frequency, leitet sich nach der Beziehung
genannt, engl. line frequency, leitet sich nach der Beziehung
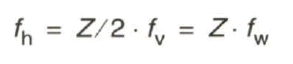
ab. Beim europäischen 625-Zeilen-System sind dies
![]() = 312 1/2 • 50 Hz = 625 • 25 Hz = 15 625 Hz.
= 312 1/2 • 50 Hz = 625 • 25 Hz = 15 625 Hz.
Der Zeilenfrequenz von ![]() = 15 625 Hz
= 15 625 Hz
entspricht eine Zeilenperiodendauer oder Zeilendauer ![]()
die üblicherweise mit dem Buchstaben H ausgedrückt wird. Beim europäischen 625-Zeilen-Fernsehsystem entspricht somit H- 64 die üblicherweise mit dem Buchstaben H ausgedrückt wird. Beim europäischen 625-Zeilen-Fernsehsystem entspricht somit H- 64![]()
2.2 BAS-Signal
Unter dem BAS-Signal versteht man das (für Schwarzweiß-Bildübertragung) komplette Videosignal, das sich aus dem eigentlichen Bildsignal (B), dem Austastsignal (A) und dem Synchronsignal (S) zusammensetzt. Das Bildsignal enthält die bildpunktweise in den einzelnen Zeilen gewonnene Information über die Helligkeitsverteilung der zu übertragenden Bildvorlage. Im Englischen wird das BAS-Signal als Composite Video Sync Signal (CVSS) bezeichnet.
2.2.1 Bildsignal mit Gamma-Korrektur
Wie eingangs erwähnt, dient zur Bildwiedergabe beim Fernsehen auch heute noch in den allermeisten Fällen die Fernsehbildröhre, eine Hochvakuum-Elektronenstrahlröhre. Die Übertragungskennlinie der Fernsehbildröhre, also die Umsetzung einer Steuerspannung ![]() in den abgestrahlten Wiedergabe-Lichtstrom
in den abgestrahlten Wiedergabe-Lichtstrom ![]() ist nicht linear und folgt der Beziehung
ist nicht linear und folgt der Beziehung
![]()
Der Exponent ![]() hat einen Wert von etwa 2,2.
hat einen Wert von etwa 2,2.
Bei einer üblicherweise linearen Übertragungskennlinie des Aufnahmewandlers hätte dies über das gesamte Aufnahme-Wiedergabe-System eine Gradationsverzerrung zur Folge, d.h. helle Bildanteile wären gegenüber den dunklen zu stark hervorgehoben. Um dem zu begegnen, wird das Bildsignal nach dem Aufnahmewandler, bezogen auf den Aufnahme-Lichtstrom ![]() durch eine zur Bildröhren- Kennlinie inverse Übertragungsfunktion korrigiert, gemäß der Beziehung
durch eine zur Bildröhren- Kennlinie inverse Übertragungsfunktion korrigiert, gemäß der Beziehung
![]()
womit im System insgesamt wieder eine lineare Beziehung
![]()
gilt. Siehe dazu Bild 2.4.
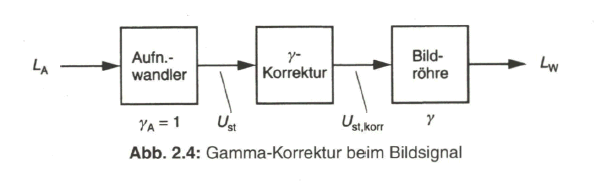
Der Exponent ![]() üblicherweise den Wert 0,45. Die Gamma-Korrektur erfolgt nach dem Aufnahmewandler im Kameravorverstärker.
üblicherweise den Wert 0,45. Die Gamma-Korrektur erfolgt nach dem Aufnahmewandler im Kameravorverstärker.
Das gammakorrigierte Bildsignal wird, insbesondere später beim Farbfernsehen in der Zusammensetzung mit den Farbwertsignalen aus dem Rot(R)-, Grün(G)- und Blau(ß)-Kanal, durch einen hochgestellten Strich gekennzeichnet: R\ G\ B'.
2.2.2 Bandbreite des Bildsignals
Das vom Videosignal belegte Frequenzband wird durch die Bildpunktauflösung in horizontaler Richtung und durch die Zeilenzahl bestimmt. Die Auflösung in vertikaler Richtung ist wegen der Zeilenstruktur diskontinuierlich und quantisiert. In horizontaler Richtung ergibt sich, bei angenommener Elektronenstrahlabtastung durch die kontinuierliche Bewegung des Abtaststrahles, eine Verschleifung von Hell-Dunkel-Kanten. Dies geschieht auch im Fall der bildpunktweisen „Abtastung" bei den CCD-Wandlern, weil wegen des Abtastvorganges eine Tiefpass-Filterung notwendig wird. Siehe dazu Bild 2.5.
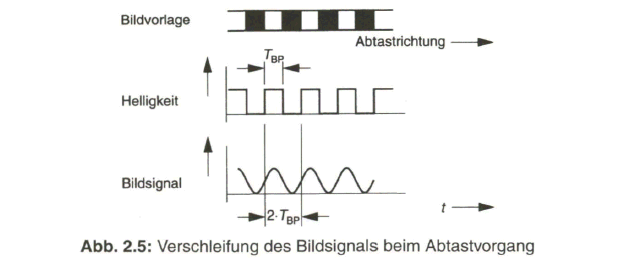
Zur Berechnung der höchsten im Bildsignal vorkommenden Frequenzkomponente, der maximalen Bildfrequenz, wird der Einfachheit halber von gleicher Auflösung des Bildes in horizontaler und vertikaler Richtung ausgegangen, das heißt die Bildpunktbreite b wird gleich dem Zeilenabstand oder der Zeilenbreite a angenommen (Bild 2.6, links).
Der Abtaststrahl muss nach Durchlaufen jeder Zeile und jedes Teilbildes wieder zurückgeführt werden. Während des Strahlrücklaufes werden sowohl der Lesestrahl im Aufnahmewandler als auch der Schreibstrahl in der Bildröhre dunkel gesteuert. Innerhalb der Periodendauer ![]() der Horizontalablenkung beziehungsweise
der Horizontalablenkung beziehungsweise ![]() der Vertikalablenkung werden Austastzeiten
der Vertikalablenkung werden Austastzeiten ![]() und
und ![]() festgelegt.
festgelegt.
Beim 625-Zeilen-System nach dem ITU-R-Standard 624, System B bzw. G, beträgt die Zeitdauer der Horizontalaustastung
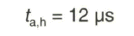
entsprechend 18,75 % von der Periodendauer ![]() und die Zeitdauer der Vertikalaustastung
und die Zeitdauer der Vertikalaustastung
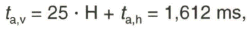
entsprechend 8 % von der Periodendauer ![]() plus
plus ![]()
Von der gesamten Zeilenperiodendauer ![]() steht somit zur Übertragung des Bildinhaltes einer Zeile nur die Zeit
steht somit zur Übertragung des Bildinhaltes einer Zeile nur die Zeit
![]()
und von der gesamten, der Periodendauer 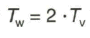 zugeordneten Zeilenzahl Z nur der Anteil
zugeordneten Zeilenzahl Z nur der Anteil
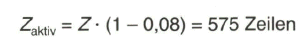
für die Bildübertragung zur Verfügung (Bild 2.6, rechts).
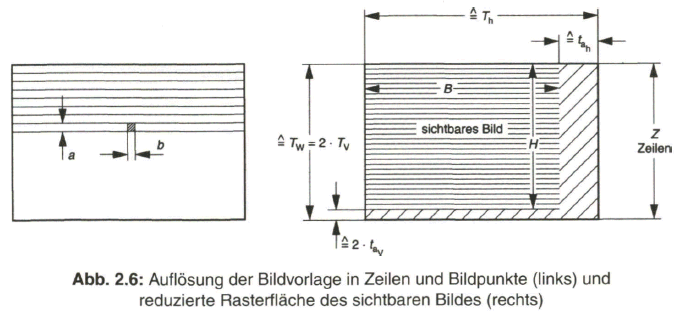
Für das sichtbare Bild ist ein Bild-Seitenverhältnis von B/H = 4/3 festgelegt. Bei gleicher Auflösung in horizontaler und vertikaler Richtung berechnet sich hieraus eine Anzahl von
4/3 • 625 • (1 - 0,08) = 767 Bildpunkte je aktive Zeile
und mit 625 • (1 - 0,08) aktiven Zeilen ein Wert von
4/3 • 625 • (1 - 0,08) ■ 625 • (1 - 0,08) = 440 833 Bildpunkte je Bild.
Diese Anzahl von Bildpunkten wird in einer Zeit von
64 ps • (1 - 0,1875) • 625 • (1 - 0,08) = 29,9 ms übertragen.
Für die Zeit zum Durchlaufen eines Bildpunktes ergibt sich dann
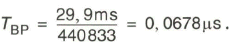
Die höchste Bildpunktfrequenz, die auch als Schachbrettfrequenz bezeichnet wird, tritt auf, wenn helle und dunkle Bildpunkte aufeinander folgen (siehe Bild 2.5). Das Bildsignal weist in diesem Fall eine Periodendauer ![]() von
von
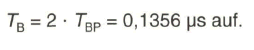
Wegen des endlichen Durchmessers des angenommenen Abtaststrahles und der damit verbundenen Verschleifung des Hell-Dunkel-Überganges genügt es, die Grundschwingung des rechteckförmigen, idealisierten Signalverlaufes zu übertragen. Dies führt zu einer höchsten vorkommenden Bildfrequenz von
![]()
Die Grenze der Auflösung in vertikaler Richtung ist durch die Zeilenstruktur gegeben. Bei voller vertikaler Auflösung und fehlender Vorfilterung würde durch den zeilenweisen Abtastvorgang ein Übersprechen im Spektrum auftreten, das zu Schwebungseffekten im wiedergegebenen Bild führen könnte. Es wird deshalb bei dem angenommenen Abtaststrahl durch eine „optische Unschärfe“ die Auflösung in vertikaler, aber gleichzeitig auch in horizontaler Richtung reduziert. Die maximale Bildfrequenz verringert sich daher etwa um den Faktor 2/3. Dieser Faktor wird als KELL-Faktor bezeichnet, unter Bezugnahme auf R. D. KELL, der sich eingehend mit dem Problem der Fernsehbildzerlegung beschäftigt hat.
Man kommt so letztendlich beim 625-Zeilen-Fernsehsystem auf eine durch den Standard festgelegte Bandbreite des Videosignals von
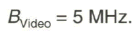
Mit der daraus berechneten Periodendauer ![]() einer Schwarz-Weiss- Bildpunktfolge von 0,2
einer Schwarz-Weiss- Bildpunktfolge von 0,2 ![]() im aktiven Teil der Zeile mit 52
im aktiven Teil der Zeile mit 52 ![]() erhält man eine Auflösung in 520 Bildpunkte pro Zeile. Für den 525-Zeilen-Standard ist eine Video-Bandbreite von 4,2 MHz festgelegt, was einer Auflösung in 442 Bildpunkte pro Zeile entspricht.
erhält man eine Auflösung in 520 Bildpunkte pro Zeile. Für den 525-Zeilen-Standard ist eine Video-Bandbreite von 4,2 MHz festgelegt, was einer Auflösung in 442 Bildpunkte pro Zeile entspricht.
2.2.3 Austastsignal
Während des horizontalen und vertikalen Strahlrücklaufes wird das Bildsignal in seinem zeitlichen Verlauf unterbrochen, es wird „ausgetastet“. Der Signalpegel wird auf dem Schwarzwert festgehalten. Die Austastung des Bildsignals wird durch das Austastsignal vorgenommen, das sich aus den zeilenfrequenten Horizontal-Austastimpulsen mit der Dauer ![]() = 12
= 12 ![]() und den im Rhythmus des Halbbildwechsels erscheinenden Vertikal- Austastimpulsen mit der Dauer
und den im Rhythmus des Halbbildwechsels erscheinenden Vertikal- Austastimpulsen mit der Dauer ![]() = 1,612 ms zusammensetzt. Das so modifizierte Bildsignal wird dadurch zum BA-Signal.
= 1,612 ms zusammensetzt. Das so modifizierte Bildsignal wird dadurch zum BA-Signal.
2.2.4 Synchronsignal
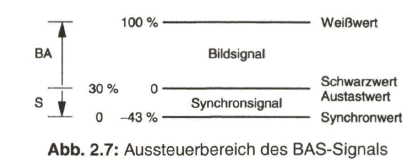
Das empfangsseitig auf der Fernsehbildröhre geschriebene Zeilenraster muss synchron mit dem sendeseitigen Zeilenraster ablaufen. Dazu werden neben dem Bildsignal noch Synchronimpulse erzeugt und übertragen. Sie steuern gleichermaßen die Ablenkeinrichtungen beim Aufnahme- und Wiedergabewandler. Eingebracht werden die Synchronimpulse während der horizontalen und vertikalen Austastzeiten. Pegelmäßig liegt das Synchronsignal unter dem Austastwert (Bild 2.7).
Die Impulse zur Synchronisierung der Horizontal- und Vertikalablenkung müssen eindeutig unterscheidbare Merkmale aufweisen. Innerhalb des wertmäßig zugeordneten Spannungsbereiches für die Synchronimpulse ist dies möglich durch die unterschiedliche Folgefrequenz und Impulsdauer.
Nach den Parametern der 625-Zeilen-Norm, ITU-R 624.BT, System B bzw. G, beginnt der Horizontal-Synchronimpuls 1,5 ![]() nach der Vorderflanke des Horizontal-Austastimpulses. Die Vorderflanke des 4,7
nach der Vorderflanke des Horizontal-Austastimpulses. Die Vorderflanke des 4,7 ![]() breiten Horizontal-Synchronimpulses ist bestimmend für das Einsetzen der Synchronisierung. Die innerhalb der Horizontalaustastung nachfolgende hintere Schwarzschulter dient als Schwarz- Bezugswert. Der Horizontal-Synchronimpuls wird im Bildwiedergabegerät über ein Differenzierglied (RC-Hochpass) aus dem Synchronsignalgemisch ausgesiebt. Damit bleibt das Kriterium der Synchronisation durch die Vorderflanke erhalten.
breiten Horizontal-Synchronimpulses ist bestimmend für das Einsetzen der Synchronisierung. Die innerhalb der Horizontalaustastung nachfolgende hintere Schwarzschulter dient als Schwarz- Bezugswert. Der Horizontal-Synchronimpuls wird im Bildwiedergabegerät über ein Differenzierglied (RC-Hochpass) aus dem Synchronsignalgemisch ausgesiebt. Damit bleibt das Kriterium der Synchronisation durch die Vorderflanke erhalten.
Innerhalb der Vertikal-Austastlücke wird der Vertikal-Synchronimpuls übertragen. Er ist mit einer Dauer von 160 ![]() (2,5 H) wesentlich länger als der Horizontal-Synchronimpuls. Damit während der Zeit von 2,5 mal der Zeilendauer kein Ausfall der Horizontal-Synchronisierung erfolgt, wird der Vertikal-Synchronimpuls jeweils kurz unterbrochen. Wegen des Halbzeilenversatzes der beiden Teilraster geschieht diese Unterbrechung im Abstand von H/2. In Bild 2.8, mit der Darstellung der kompletten Vertikal-Synchronimpulsfolge innerhalb der V-Austastlücke des ersten und zweiten Halbbildes, sind die für die Horizontal-Synchronisierung maßgebenden Impulsflanken markiert.
(2,5 H) wesentlich länger als der Horizontal-Synchronimpuls. Damit während der Zeit von 2,5 mal der Zeilendauer kein Ausfall der Horizontal-Synchronisierung erfolgt, wird der Vertikal-Synchronimpuls jeweils kurz unterbrochen. Wegen des Halbzeilenversatzes der beiden Teilraster geschieht diese Unterbrechung im Abstand von H/2. In Bild 2.8, mit der Darstellung der kompletten Vertikal-Synchronimpulsfolge innerhalb der V-Austastlücke des ersten und zweiten Halbbildes, sind die für die Horizontal-Synchronisierung maßgebenden Impulsflanken markiert.
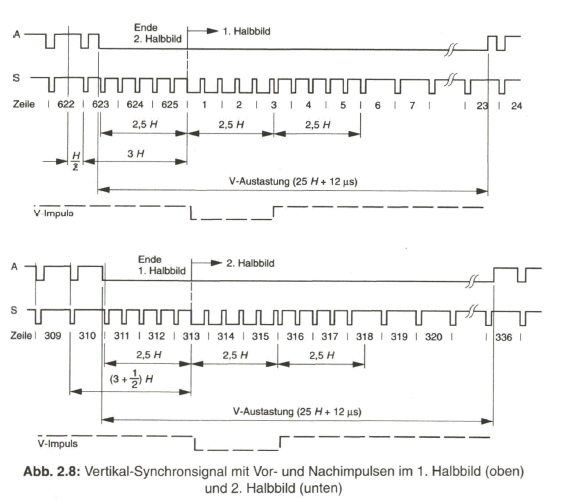
Das Kriterium für die Synchronisierung der Vertikalablenkung gewinnt man durch Integration des vollständigen Synchronsignals, bei der wegen der Tiefpasswirkung des Integriergliedes (RC-Tiefpass) und der längeren Impulsdauer des Vertikal-Synchronimpulses nur dieser den entscheidenden Beitrag für die Spannung am Integrationskondensator liefert.
Die dem Vertikal-Synchronimpuls vorangehenden Horizontal-Synchronimpulse ergäben jedoch wegen des H/2-Versatzes in den beiden Halbbildern unterschiedliche Anfangsbedingungen für den Integrationsvorgang. Dies könnte zu einem falschen Einsetzen der Vertikal-Synchronisierung und damit zu einer Paarigkeit der Rasterzeilen führen. Es werden deshalb dem eigentlichen Vertikal-Synchronimpuls fünf schmale, 2,35![]() breite Ausgleichsimpulse - die Vorimpulse jeweils im Abstand von H/2 vorausgeschickt, damit in jedem Halbbild gleiche Anfangsbedingungen für die Integration herrschen. In ähnlicher Weise sorgen fünf Nachimpulse für eine gleichmäßige Rückflanke der integrierten Vertikal-Teilimpulse.
breite Ausgleichsimpulse - die Vorimpulse jeweils im Abstand von H/2 vorausgeschickt, damit in jedem Halbbild gleiche Anfangsbedingungen für die Integration herrschen. In ähnlicher Weise sorgen fünf Nachimpulse für eine gleichmäßige Rückflanke der integrierten Vertikal-Teilimpulse.
Zur Zählweise der Zeilen in Bild 2.8 ist noch Folgendes zu sagen: In der Fernsehtechnik ist es üblich, entgegen der Aufteilung in ungeradzahlige und geradzahlige Zeilen gemäß Bild 2.3, die aufeinanderfolgend ablaufenden Zeilen durchgehend zu nummerieren. Das erste Halbbild beginnt bei der Vorderflanke des Vertikal-Synchronimpulses mit Zeile 1 und es weist 312 ![]() Zeilen auf. Davon fallen die ersten 22 1/2 Zeilen in die Vertikal-Austastlücke. Das zweite Halbbild beginnt nach 312 1/2 Zeilen in der Mitte der 313. Zeile. Danach wiederholt sich die Zählweise im Rhythmus von zwei Halbbildern.
Zeilen auf. Davon fallen die ersten 22 1/2 Zeilen in die Vertikal-Austastlücke. Das zweite Halbbild beginnt nach 312 1/2 Zeilen in der Mitte der 313. Zeile. Danach wiederholt sich die Zählweise im Rhythmus von zwei Halbbildern.
Das Synchronsignal wird an der Videosignalquelle pegelgerecht dem BA-Signal zugesetzt. Man erhält so das BAS-Signal. Der Normspannungswert für das BAS- Signal beträgt in der Studio- und Fernsehmesstechnik 1 V (Spitze-Spitze-Wert), wobei auf den BA-Anteil 70 % (0,7 V) und auf den S-Anteil 30 % (0,3 V) entfallen. Als Bezugspegel kann der Austastwert gelten (nach ITU-R-Norm) mit dem Weißwert bei 100 % und dem Synchronwert bei -43 % oder der Synchronpegel, wobei dann der Austastwert bei 30 % vom Weißwert liegt (siehe dazu Bild 2.7). Der Bezugswiderstand in der Videotechnik ist 75 Ohm.
2.3 Farbbildsignal
Den bisherigen Ausführungen liegt die Übertragung der Helligkeitsinformation einer bunten Bildvorlage zu Grunde. Beim „Fernsehen“ wird jedoch schon seit langen Jahren dem Zuschauer ein „Farbbild“ übertragen.
2.3.1 Farbbildaufnahme und -Wiedergabe
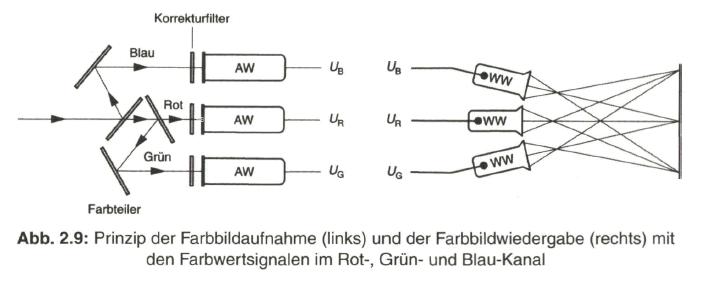
Die Farbbildaufnahme beim Fernsehen basiert auf dem Vorgang der Wahrnehmung eines Farbreizes durch das menschliche Auge, wo auf der Netzhaut neben den auf Helligkeitsunterschiede reagierenden Stäbchen noch weitere Sensoren, die Zäpfchen, auf einfallende Lichtstrahlung im Spektralbereich von Blau (etwa 400 bis 500 nm), Grün (etwa 500 bis 600 nm) und Rot (etwa 600 bis 700 nm) reagieren. Über eine Mischung der drei Teilempfindungen entsteht der Farbeindruck. Daraus ergibt sich auch das Prinzip der Farbbildaufnahme über drei optisch-elektrische Aufnahmewandler (AW). Das über ein optisches Linsensystem einfallende Licht wird in einem Farbteiler, bestehend aus halbdurchlässigen Spiegeln, Umlenkspiegeln und Korrekturfiltern, den drei Aufnahmewandlern für den Rot-, Grün- und Blau-Kanal zugeführt (Bild 2.9, links).
Das Aufnahmesystem ist farbmetrisch auf die Eigenschaften des Farbbildwiedergabesystems abgestimmt. Die Farbbildwiedergabe kann prinzipiell mit drei elektrisch-optischen Wiedergabewandlern (WW) und Projektion über ein Linsensystem auf einen gemeinsamen Bildschirm erfolgen (Bild 2.9, rechts). Diese Anordnung findet sich in Projektionssystemen wieder. Bei dem herkömmlichen Farbfernsehempfänger kommt als Wiedergabewandler noch immer die Fernsehbildröhre, teilweise auch schon der Flachbildschirm mit LCD- oder Gasentladungstechnik zum Einsatz.
2.3.2 Farbwertsignale R, G, B
Das Farbbildaufnahmesystem liefert die Farbwertsignale mit der Spannung UR, UG und UB bzw. korrekterweise mit gammakorrigierten Signalen UR \ UG und UB. Der Einfachheit halber werden die Farbwertsignale nur mit R, G und B bezeichnet.
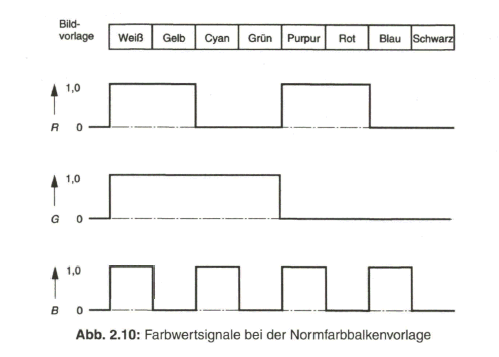
Für Abgleich- und Testzwecke verwendet man eine so genannte Farbbalkenvorlage. Diese setzt sich zusammen aus vertikalen Balken mit den Unbuntstufen Weiß und Schwarz sowie den Grund- oder Primärfarben Rot, Grün und Blau und den Mischfarben Cyan (Blau und Grün), Gelb (Grün und Rot) und Purpur (Rot und Blau). Die Reihenfolge der Farbbalken ist nach sinkender Helligkeit angeordnet. So ergeben sich bei der zeilenweisen Abtastung dieser Bildvorlage die Farbwertsignale R, G und B bezogen auf die (aktive) Zeilendauer gemäß Bild 2.10.
2.3.3 Helligkeits- oder Leuchtdichtesignal
Schon aus der Kompatibilitätsforderung bei Einführung des Farbfernsehens ergab sich, dass weiterhin ein Helligkeitssignal erforderlich ist. Auch unter Bezugnahme auf die Lichtwahrnehmung des menschlichen Auges über ein Helligkeitsempfinden und ein Farbempfinden wird deshalb aus den Farbwertsignalen unter Berücksichtigung des spektral unterschiedlichen Helligkeitsempfindens ein Helligkeitssignal abgeleitet, das jetzt mit dem farbmetrisch korrekten Ausdruck als Leuchtdichtesignal Y bezeichnet wird, und sich gemäß der Beziehung
![]()
zusammensetzt.
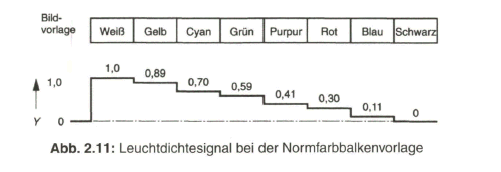
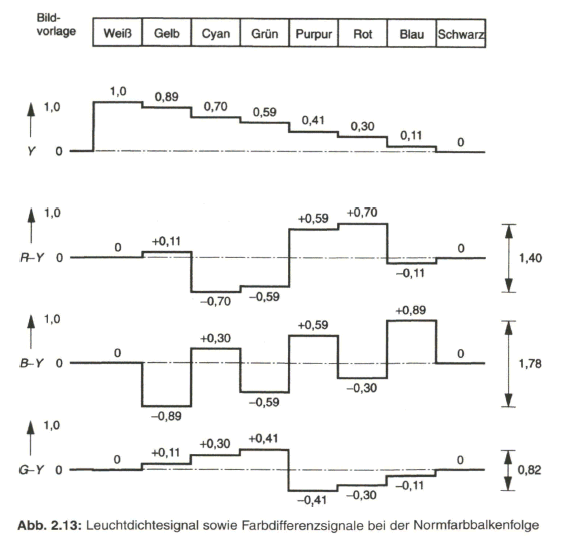
Das Y-Signal wird über eine Matrix-Schaltung, zum Beispiel über ein Widerstandsnetzwerk, aus den R-G-B-Signalen gewonnen. Bild 2.11 zeigt den Verlauf des Y-Signals bei der Normfarbbalkenfolge.
Die Leuchtdichte wird vielfach auch mit Luminanz bezeichnet, vom englischen Begriff luminance übernommen, woraus sich ein Luminanzsignalableitet.
2.3.4 Farbdifferenzsignale
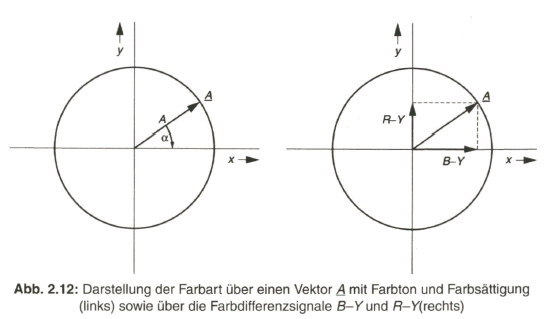
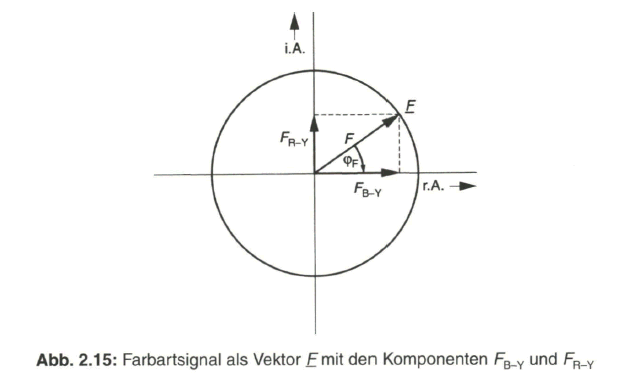
Ein Farbreiz, wird neben der Helligkeit oder Leuchtdichte noch durch die Farbart charakterisiert. Dieser Begriff beinhaltet eine Doppelinformation, nämlich eine Aussage über den Farbton, der über die Wellenlänge der reinen oder dominierenden Spektralkomponente in der Lichtstrahlung angegeben werden kann, und eine Aussage über die Farbsättigung, als ein Maß für die spektrale Reinheit gegenüber dem Gleichenergieweiß, in dem alle Spektralkomponenten der sichtbaren Strahlung mit gleicher Energie vertreten sind. Die Farbart wird auch als Chrominanz bezeichnet, aus dem englischen Ausdruck chrominance, mit dem Farbton, engl, hue oder colour hue und der Farbsättigung, engl. colour Saturation. Entsprechend der Doppelinformation kann die Farbart nur in zweidimensionaler Darstellung angegeben werden. Dies ist möglich in einem Polar-Koordinatensystem als Vektor A, dessen Winkel a zur positiven x-Achse die Wellenlänge und damit den Farbton ausdrückt und dessen Länge A ein Maß für die Farbsättigung angibt (siehe Bild 2.12, links).
Die Farbart kann aber auch über die Achsenabschnitte aus der Projektion des Vektors A auf die X- und Y-Achse angegeben werden. Es sind dies die Farbdifferenzsignale B-Y und R-Y (siehe Bild 2.12, rechts).
Die Farbdifferenzsignale können positiven oder negativen Wert haben. Sie werden zu Null bei Unbunt, d. h. bei Weiß und allen Grauwerten bis Schwarz. Die Übertragung des Farbbildsignals erfolgt entweder über die Farbwertsignale R, G, B, wobei jedes dieser Signale die volle Videobandbreite von z. B. 5 MHz aufweist, oder mittels Leuchtdichtesignal Y und den Farbdifferenzsignalen B-Y und R-Y. In diesem Fall weist nur das Leuchtdichtesignal die volle Videobandbreite auf. Die beiden Farbdifferenzsignale können wegen der geringeren Auflösung des menschlichen Sehorgans für Farbdetails mit einer niedrigeren Bandbreite als für das Leuchtdichtesignal (etwa ein Viertel bis ein Halb der Luminanz-Bandbreite) übertragen werden.
Die Wiedergewinnung der Farbwertsignale R, G und B auf der Empfängerseite erfolgt gemäß den Beziehungen
(R- Y)+Y= R
(B- Y) + Y= B
(G- Y)+Y=G
Das nicht übertragene (G-V)-Signal wird aus
Gl. (2.3) Y=0,30- R +0,59- G + 0,11 •B
und mit Y= 0,30 • Y+ 0,59 • Y+ 0,11 -Y
berechnet zu
(G-Y)--0,51 • (R- V)-0,19 • (B- Y).
Bild 2.13 gibt die bei der Normfarbbalken-Bildvorlage zeilenperiodischen Signale für Y sowie R-Y, B-Y und G-Y wieder. Dabei ist zu ersehen, dass die Farbdifferenzsignale bipolar sind und in ihrem Spitze-Spitze-Wert den auf 1,0 normierten Wert beim Leuchtdichtesignal für den Bereich von Schwarz bis Weiß überschreiten.
2.4 FBAS-Signal
Zur Übertragung der Farbartinformation im analogen Fernsehsignal musste eine Lösung gefunden werden, die es erlaubt, zusätzlich zum BAS-Signal im gleichen Frequenzband des Videosignals ein „Farbartsignal“ ohne gegenseitige Störungen einzufügen.
2.4.1 Spektrum des Leuchtdichte- bzw. BAS-Signals
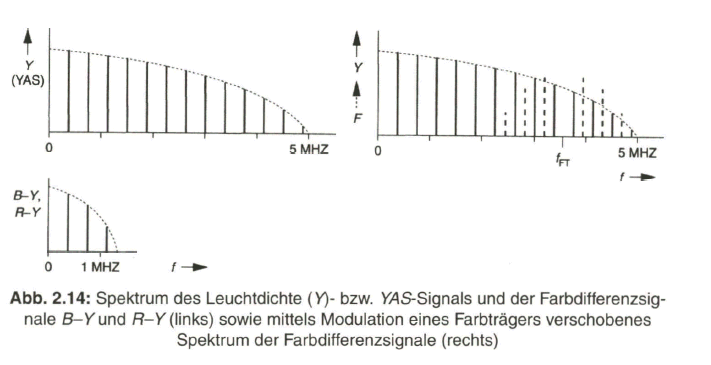
Beim ATSC-Verfahren, nach dem National Television System Committee benannt, und bei der verbesserten Variante, dem PAL-Verfahren, abgeleitet von Phase Alternation Line, nützt man im Spektrum des BAS- bzw. YAS-Signals die Lücken zwischen den einzelnen im Abstand der Horizontalfrequenz fh zueinander auftretenden Spektralkomponenten aus. Nachdem auch die Farbdifferenzsignale mit der Zeilenfrequenz verknüpft sind, treten deren Spektralkomponenten ebenso bei Vielfachen der Zeilenfrequenz auf, mit einer Begrenzung des Spektrums bei etwa einem Viertel der Bandbreite des BAS-Signals. Bild 2.14, links, zeigt dazu schematisch das Spektrum des BAS- bzw. YAS-Signals und der Farbdifferenzsignale B-Y und R-Y.
Es wird nun eine Frequenzverschiebung des Spektrums der Farbdifferenzsignale aus der Bezugsfrequenzlage von Null auf eine höhere Frequenzlage, symmetrisch um die Frequenz des Farbträgers vorgenommen, indem dieser in seiner 0°- Komponente mit dem (B-Y)-Signal und in seiner 90°-Komponente mit dem (P-Y)- Signal amplitudenmoduliert wird. Man erhält so das Farbartsignal F.
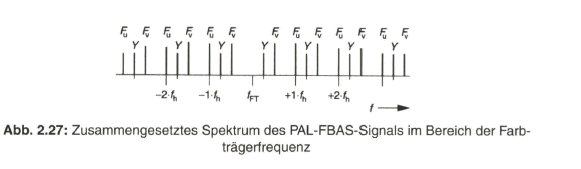
Die Frequenz ![]() des Farbträgers weist gegenüber den Spektralkomponenten des BAS-Signals einen Offset um die halbe Zeilenfrequenz auf (Halbzeilen-Offset). Sie liegt im oberen Bereich des BAS-Spektrums. Bild 2.14, rechts, gibt das verkämmte Spektrum von BAS-Signal und Farbartsignal wieder.
des Farbträgers weist gegenüber den Spektralkomponenten des BAS-Signals einen Offset um die halbe Zeilenfrequenz auf (Halbzeilen-Offset). Sie liegt im oberen Bereich des BAS-Spektrums. Bild 2.14, rechts, gibt das verkämmte Spektrum von BAS-Signal und Farbartsignal wieder.
Die genaue Frequenz des Farbträgers wird bei dem NTSC-Verfahren durch den so genannten Halbzeilen-Offset bestimmt, mit dem Wert
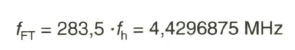
(bezogen auf das europäische 625-Zeilen-System).
Bei dem PAL-Verfahren ist durch die zeilenweise Umpolung der 90°-Komponente der Farbträgerschwingung ein Viertelzeilen-Offset erforderlich, wobei noch ein zusätzlicher 25-Hz-Versatz dazukommt. Somit beträgt die Farbträgerfrequenz nun
![]()
0°-Komponente vom (B-Y)-Signal und in einer 90°-Komponente vom (R-Y)-Signal modulierten Farbträgers. Man spricht in diesem Fall von Quadraturamplitudenmodulation. Technisch realisiert wird die Quadraturamplitudenmodulation über eine Amplitudenmodulation mit unterdrücktem Träger auf einer 0°-Komponente und auf einer 90°-Komponente des Farbträgers mit anschließender vektorieller Addition der Modulationsprodukte.
Die Doppelinformation Farbton und Farbsättigung wird so in die Phase und Amplitude des resultierenden Vektors F übertragen, mit den Komponenten![]() und
und ![]() (Bild2.15).
(Bild2.15).
2.4.2 Farbartsignal beim PAL-Verfahren
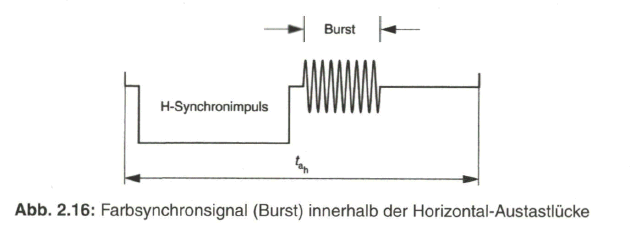
Beim Farbartsignal wird in der Phasenlage der modulierten Farbträgerschwingung gegenüber der Bezugslage 0° der Farbton übertragen. Die Bezugsphase 0° (bzw. 180°) wird während jeder Zeile durch eine Folge von etwa 10 Schwingungen des unmodulierten Farbträgers als Burst nach dem Horizontal-Synchronimpuls auf der hinteren Schwarzschulter der Empfängerseite übermittelt (Bild 2.16).
Eine Veränderung der Phase des Farbartsignals gegenüber der Burstphase auf dem Übertragungsweg führt zu einer Farbtonverfälschung. Um dem zu begegnen, wird beim PAL-Verfahren (Phase Alternation Line) eine Phasenfehlerkompensation durch eine zeilenweise Umpolung der ![]() Komponente (+90° oder -90°) bewirkt, die auf der Empfängerseite wieder rückgängig gemacht wird.
Komponente (+90° oder -90°) bewirkt, die auf der Empfängerseite wieder rückgängig gemacht wird.
Die jeweils übertragene Phasenlage der ![]() Komponente wird durch den synchron dazu mit seiner wechselnden ±90°-Komponente alternierenden Burst dem Empfänger übermittelt (Bild 2.17).
Komponente wird durch den synchron dazu mit seiner wechselnden ±90°-Komponente alternierenden Burst dem Empfänger übermittelt (Bild 2.17).
Die Phasenlage der FV- Komponente und damit auch des alternierenden Burst ist unter Bezug auf ungeradzahlige und geradzahlige Zeilen in aufeinanderfolgenden Halbbildern gemäß dem ITU-R-Standard 624 genau festgelegt. Es ergibt sich eine Wiederholung nach acht Halbbildern (8er-Sequenz). In Verbindung mit der Austastung des Bursts während eines Teils der Vertikal-Austastlücke wird damit gewährleistet, dass alle Halbbilder mit der gleichen Burstphase beginnen.
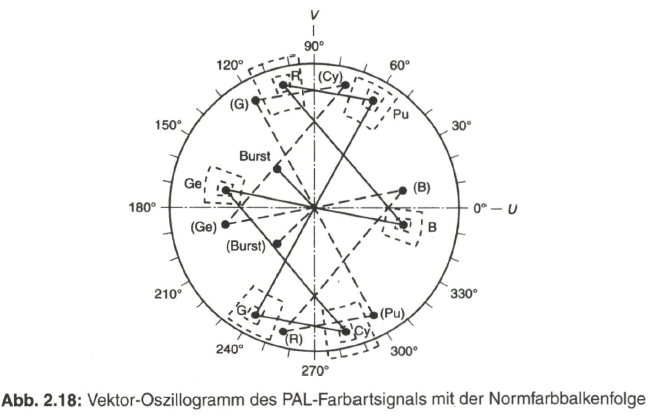
Mit dem Farbartsignal wird die Information über den Farbton, in der Phasenlage bezogen auf die Referenzphase des Burst, und über die Farbsättigung, in der Amplitude der Farbträgerschwingung, bezogen auf den Bildinhalt innerhalb des aktiven Teils einer Zeile übertragen. Am Beispiel der Normfarbbalkenvorlage (Bildvorlage siehe Bild 2.10) gibt Bild 2.18 das Vektor-Oszillogramm des PAL- Farbartsignals für zwei aufeinanderfolgende Zeilen mit der zeilenweise alternierenden ![]() bzw. FV- Komponente (auf der (R-Y)- bzw. V-Achse) und dem zeilenweise alternierenden Burst wieder. Die Endpunkte der Vektoren, die am Bildschirm der Elektronenstrahlröhre des Vektorskops als helle Punkte erscheinen, sollen dabei innerhalb eines engeren oder weiteren Toleranzbereiches liegen. Bei einer unbunten Bildvorlage werden die Farbdifferenzsignale zu Null und damit auch die Komponenten
bzw. FV- Komponente (auf der (R-Y)- bzw. V-Achse) und dem zeilenweise alternierenden Burst wieder. Die Endpunkte der Vektoren, die am Bildschirm der Elektronenstrahlröhre des Vektorskops als helle Punkte erscheinen, sollen dabei innerhalb eines engeren oder weiteren Toleranzbereiches liegen. Bei einer unbunten Bildvorlage werden die Farbdifferenzsignale zu Null und damit auch die Komponenten ![]() und
und ![]() des Farbartsignals. Im Vektor-Oszillogramm bedeutet dies, dass der Vektorendpunkt im Koordinaten-Nullpunkt liegt.
des Farbartsignals. Im Vektor-Oszillogramm bedeutet dies, dass der Vektorendpunkt im Koordinaten-Nullpunkt liegt.
Die Bedeutung der U- und V-Signale bzw. der ![]() und
und ![]() Signalkomponenten des Farbartsignals wird im Folgenden erläutert.
Signalkomponenten des Farbartsignals wird im Folgenden erläutert.
2.4.3 PAL-FBAS-Signal
Das Farbartsignal F wird, zusammen mit dem Burst, dem BA-Signal (YA-Signal) additiv überlagert. Man erhält so das FBAS-Signal. Die resultierende Amplitude ![]() des Farbartsignals ergibt sich aus der vektoriellen Addition der
des Farbartsignals ergibt sich aus der vektoriellen Addition der ![]() und
und ![]() Komponente. Bei der Amplitudenmodulation mit Trägerunterdrückung wird der Momentanwert und damit auch der Maximalwert des modulierenden Signals in den Momentanwert bzw. die Amplitude des Farbartsignals umgesetzt. Man erhält
Komponente. Bei der Amplitudenmodulation mit Trägerunterdrückung wird der Momentanwert und damit auch der Maximalwert des modulierenden Signals in den Momentanwert bzw. die Amplitude des Farbartsignals umgesetzt. Man erhält
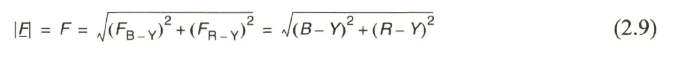
Unter Bezugnahme auf das Testsignal mit der Normfarbbalkenfolge würde die Addition von Leuchtdichtesignal Y und Farbartsignal F zu einer wesentlichen Überschreitung des Aussteuerbereiches vom ursprünglichen BA- bzw. Y-Signal führen. Es wird deshalb eine Reduktion der Amplitude des Farbartsignals über eine Reduzierung der Farbdifferenzsignalwerte B-Y und R-Y vorgenommen und zwar so, dass bei 100 % Farbsättigung eine Überschreitung des Aussteuerbereiches um 33 % zugelassen wird. Die reduzierten Farbdifferenzsignale werden nun mit den neuen Symbolen U und V gekennzeichnet. Es gelten die Beziehungen

und daraus

Tabelle 2.1 listet eine Zusammenstellung der normierten Signalwerte bei der Normfarbbalkenfolge mit 100 % Farbsättigung auf. Signalwerte bei der Normfarbbalkenfolge mit 100 % Farbsättigung

Im praktischen Betrieb werden Farbsättigungswerte gegen 100 % kaum erreicht. Es wird deshalb ein Testsignal (EBU-Testsignal, nach European Broadcasting Union) mit der Normfarbbalkenfolge und 75 % Farbsättigung definiert, das maximal an den Aussteuerungsgrenzwert von BA = 1,00, entsprechend dem Weißwert, herankommt. Die Farbsättigung von 75 % erhält man durch Reduktion der Farbwertsignale R, G und B (nicht beim Weiß-Balken) auf 75 % ihres ursprünglichen Wertes. Selbstverständlich ändern sich damit auch die Werte für das Leuchtdichtesignal Y, außer im Weiß-Balken, entsprechend. In Bild 2.19 ist das Zeilen-Oszillogramm dargestellt.
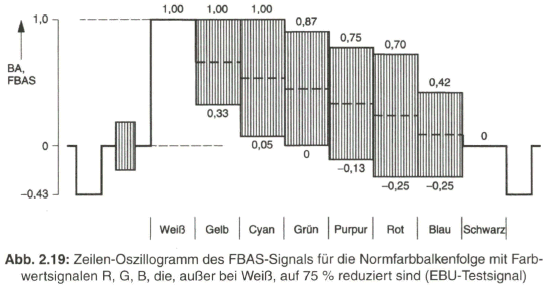
Mit dem PAL-Verfahren kann auf relativ einfache Weise eine Kompensation von Phasenfehlern im Farbartsignal gegenüber der Bezugsphase im Burst erreicht werden. Der Grundgedanke ist folgender: Eine Phasenverschiebung, die das Farbartsignal auf dem Übertragungsweg erfahren hat, kann durch eine entgegengesetzt gerichtete, gleich große Phasendrehung kompensiert werden.
Man erreicht diesen Effekt, indem die Phasenlage einer der beiden Komponenten des Farbartsignals, z. B. der FV- Komponente, zeilenweise um 180° umgepolt wird. Damit tritt der Phasenfehler auf der Empfangsseite abwechselnd in positiver und in negativer Richtung auf. Durch eine Addition der Farbartsignale von zwei aufeinanderfolgenden Zeilen kompensiert sich der Fehler. Bild 2.20 erläutert das Prinzip der Phasenfehlerkompensation beim PAL-Verfahren.
Das Farbartsignal ![]() der Zeile n, zusammengesetzt aus den Komponenten
der Zeile n, zusammengesetzt aus den Komponenten ![]() und
und ![]() , erleidet auf der Übertragungsstrecke einen Phasenfehler a in positiver Richtung gegenüber der Bezugsphase des Burst. Es gelangt empfangsseitig als Signal
, erleidet auf der Übertragungsstrecke einen Phasenfehler a in positiver Richtung gegenüber der Bezugsphase des Burst. Es gelangt empfangsseitig als Signal ![]() über ein Laufzeitglied mit der Verzögerung um die Dauer einer Zeile (64
über ein Laufzeitglied mit der Verzögerung um die Dauer einer Zeile (64![]() ) zu einer Addierstufe. Während der darauffolgend übertragenen Zeile n + 1 wird sendeseitig die fv- Komponente um 180° umgepolt. Das Farbartsignal
) zu einer Addierstufe. Während der darauffolgend übertragenen Zeile n + 1 wird sendeseitig die fv- Komponente um 180° umgepolt. Das Farbartsignal ![]() , gebildet aus den Komponenten
, gebildet aus den Komponenten ![]() und
und ![]() , wird ebenso um den Phasenfehler a in positiver Richtung verfälscht. Die sendeseitige Umpolung der Fv-Komponente muss nun empfangsseitig wieder rückgängig gemacht werden. Damit erhält man aus dem fehlerbehafteten Signal
, wird ebenso um den Phasenfehler a in positiver Richtung verfälscht. Die sendeseitige Umpolung der Fv-Komponente muss nun empfangsseitig wieder rückgängig gemacht werden. Damit erhält man aus dem fehlerbehafteten Signal ![]() nach Umpolung der Fv-Komponente das Farbartsignal
nach Umpolung der Fv-Komponente das Farbartsignal ![]() , das den Phasenfehler a der Übertragungsstrecke mit negativer Richtung aufweist.
, das den Phasenfehler a der Übertragungsstrecke mit negativer Richtung aufweist.
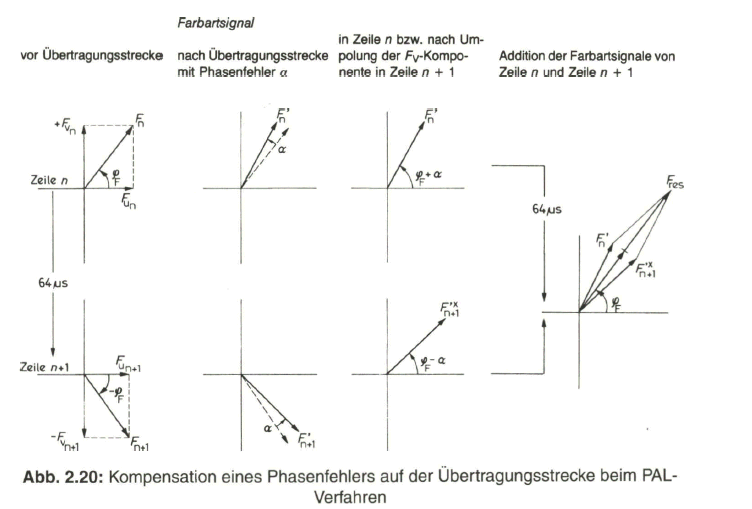
Unter der Voraussetzung, dass die Farbartsignale der Zeilen n und n + 1 gleich sind, erhält man aus der Addition des verzögerten Farbartsignals ![]() und des unverzögerten Farbartsignals
und des unverzögerten Farbartsignals ![]() ein resultierendes Signal
ein resultierendes Signal ![]() , in dem sich der Phasenfehler aufhebt. Der Phasenwinkel
, in dem sich der Phasenfehler aufhebt. Der Phasenwinkel ![]() des Empfangsignals
des Empfangsignals ![]() ist identisch mit dem des gesendeten Farbartsignals, womit der Farbton erhalten bleibt. Das Empfangssignal weist nach einer Reduzierung auf den halben Amplitudenwert lediglich eine geringe Entsättigung gegenüber dem Sendesignal auf.
ist identisch mit dem des gesendeten Farbartsignals, womit der Farbton erhalten bleibt. Das Empfangssignal weist nach einer Reduzierung auf den halben Amplitudenwert lediglich eine geringe Entsättigung gegenüber dem Sendesignal auf.
2.4.4 PAL-Coder und -Decoder
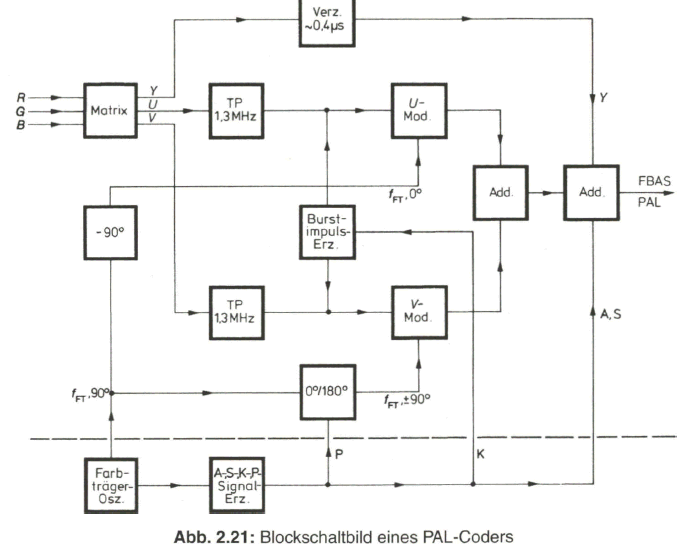
Die Aufbereitung des FBAS-Signals erfolgt im PAL-Coder. Bild 2.21 zeigt dazu das Blockschaltbild eines PAL-Coders. Es werden neben dem Y-Signal mit der vollen Bandbreite von 5 MHz die reduzierten Farbdifferenzsignale U und V mit einer Bandbreite von 1,3 MHz (max. 3 dB Abfall) übertragen. Zum Angleichen der Signallaufzeit im schmalbandigen Chrominanzkanal und im breitbandigen Luminanzkanal wird das Y-Signal um etwa 0,4 ![]() verzögert. Im U- und V- Modulator werden auch der 0°- und der +90°- bzw. -90°-Anteil des alternierenden Burst erzeugt. Die Auftastung während der Dauer des Burst erfolgt über den K-Impuls (Keying-lmpuls). Dem U-Modulator wird der Farbträger mit 0°-Phase und dem V- Modulator mit +90°- bzw. -90°-Phase zugeführt. Die zeilenweise Phasenumpolung des 90°-Trägers wird über den P-Impuls (PAL-Impuls) vorgenommen. Am Ausgang des PAL-Coders werden das Leuchtdichtesignal Y (BA) und das Farbartsignal F mit dem Austast- und dem Synchronsignal zum FSAS-Signal zusammengefasst.
verzögert. Im U- und V- Modulator werden auch der 0°- und der +90°- bzw. -90°-Anteil des alternierenden Burst erzeugt. Die Auftastung während der Dauer des Burst erfolgt über den K-Impuls (Keying-lmpuls). Dem U-Modulator wird der Farbträger mit 0°-Phase und dem V- Modulator mit +90°- bzw. -90°-Phase zugeführt. Die zeilenweise Phasenumpolung des 90°-Trägers wird über den P-Impuls (PAL-Impuls) vorgenommen. Am Ausgang des PAL-Coders werden das Leuchtdichtesignal Y (BA) und das Farbartsignal F mit dem Austast- und dem Synchronsignal zum FSAS-Signal zusammengefasst.
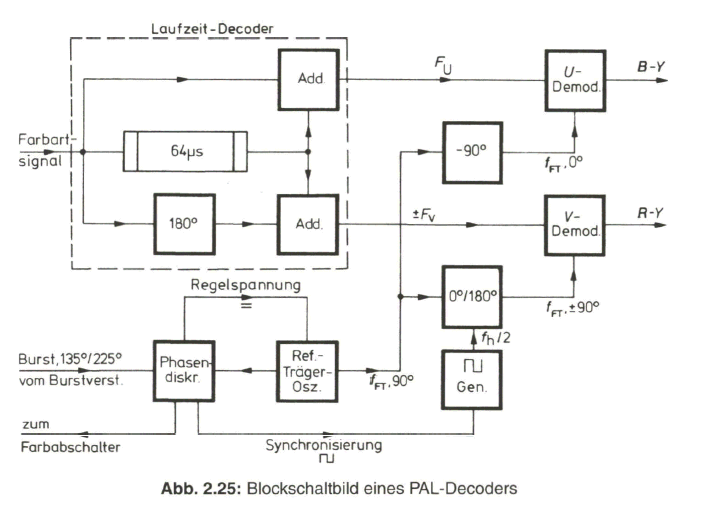
Die technische Realisierung der PAL-Fehlerkompensation auf der Empfängerseite bedarf gegenüber der Prinzipdarstellung in Bild 2.20 einer besonderen Erläuterung. Dazu ist es zweckmäßig, aus dem PAL-Decoder zunächst eine wichtige Funktionsgruppe, den Laufzeit-Decoder herauszunehmen. Im Gegensatz zu einem NTSC-Decoder wird beim PAL-Decoder das Farbartsignal nicht parallel den Synchrondemodulatoren zugeführt, sondern es findet bereits vorher eine Aufspaltung in die FU- und die FV- Komponente statt. Diese Aufgabe übernimmt der Laufzeit-Decoder (Bild 2.22).
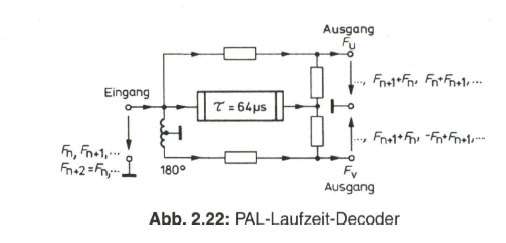
Das ankommende Farbartsignal teilt sich am Eingang des Laufzeit-Decoders in drei Pfade auf. Es gelangt einmal über ein Laufzeitglied mit der Signalverzögerung um eine Zeilendauer ![]() (Gruppenlaufzeit 64
(Gruppenlaufzeit 64 ![]() ) und mit einer Phasenverschiebung von 0°
) und mit einer Phasenverschiebung von 0° ![]() , entsprechend einer Phasenlaufzeit von z. B. 284
, entsprechend einer Phasenlaufzeit von z. B. 284![]() 64,056
64,056 ![]() , und zum anderen auf direktem Weg mit 0° bzw. 180° Phasendrehung an die beiden Ausgänge. Dort findet jeweils die Addition von zwei Signalen statt.
, und zum anderen auf direktem Weg mit 0° bzw. 180° Phasendrehung an die beiden Ausgänge. Dort findet jeweils die Addition von zwei Signalen statt.
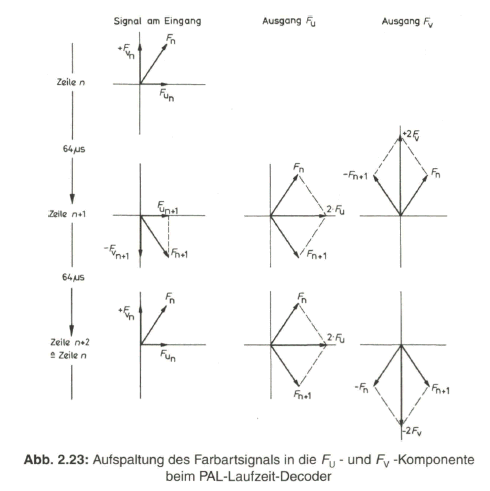
Am „Ausgang FU-" addieren sich das Farbartsignal der vorangehenden Zeile (FN) und das der gerade ablaufenden Zeile (![]() ). Aufeinanderfolgende Zeilen beinhalten die FV- Komponente mit um 180° wechselnder Phasenlage, so dass diese sich über zwei Zeilen hinweg aufhebt. An dem „Ausgang FU- ” kann somit ständig die FU- Komponente des Farbartsignals abgenommen werden. Dem „Ausgang FV ” wird das Eingangssignal um 180° phasenverschoben zugeführt. Durch die Addition mit dem um eine Zeilendauer verzögerten Farbartsignal ergibt sich hier eine Aufhebung der Fu- Komponente. Es erscheint an diesem Ausgang dann nur die FV- Komponente des Farbartsignals, allerdings zeilenweise in der Phasenlage um 180° wechselnd. Die Funktion des Laufzeit-Decoders geht aus dem Zeigerdiagramm in Bild 2.23 deutlich hervor.
). Aufeinanderfolgende Zeilen beinhalten die FV- Komponente mit um 180° wechselnder Phasenlage, so dass diese sich über zwei Zeilen hinweg aufhebt. An dem „Ausgang FU- ” kann somit ständig die FU- Komponente des Farbartsignals abgenommen werden. Dem „Ausgang FV ” wird das Eingangssignal um 180° phasenverschoben zugeführt. Durch die Addition mit dem um eine Zeilendauer verzögerten Farbartsignal ergibt sich hier eine Aufhebung der Fu- Komponente. Es erscheint an diesem Ausgang dann nur die FV- Komponente des Farbartsignals, allerdings zeilenweise in der Phasenlage um 180° wechselnd. Die Funktion des Laufzeit-Decoders geht aus dem Zeigerdiagramm in Bild 2.23 deutlich hervor.
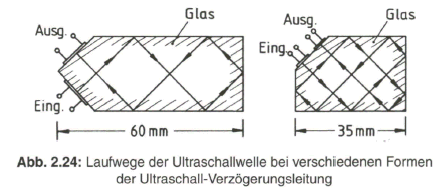
Zur Signalverzögerung im Laufzeit-Decoder verwendet man eine Ultraschall-Verzögerungsleitung. Der Begriff „Leitung” ist hier nur im übertragenen Sinne zu deuten, weil tatsächlich ein Glaskörper Verwendung findet. Das Farbartsignal wird dazu über piezo-elektrische Wandler in eine Ultraschallschwingung mit 4,43 MHz und wieder in ein elektrisches Signal umgewandelt. Die Ultraschallwelle durchläuft diesen Glaskörper. Ihre Fortpflanzungsgeschwindigkeit ist gering (2650 m/s), so dass man für die Laufzeit von 64 ![]() etwa eine Lauflänge von 17 cm benötigt.
etwa eine Lauflänge von 17 cm benötigt.
Die ersten Ultraschall-Verzögerungsleitungen waren zunächst stabförmig, bei einer Länge von etwa 17 cm. Kleinere Abmessungen erreicht man, wenn Mehrfachreflexionen an den Glas-Luft-Übergängen ausgenutzt werden. Bild 2.24 zeigt dazu verschiedene Möglichkeiten.
Die zeilenweise Änderung der Phasenlage der FV- Komponente könnte durch eine entsprechende periodische Umschaltung rückgängig gemacht werden. Einfacher ist jedoch die zeilenweise Umpolung der Phasenlage des Referenzträgers für den Y-Synchrondemodulator im PAL-Decoder. In der Anordnung des kompletten PAL-Decoders (Bild 2.25) übernimmt diese Aufgabe der PAL-Schalter. Die phasenrichtige Synchronisierung des PAL-Schalters erfolgt über die Auswertung des alternierenden Burst.
Die Ausgangssignale des Laufzeit-Decoders, FU und +FV werden den Synchrondemodulatoren zugeführt, wo sie mit dem Referenz-Farbträger in 0°- bzw. ±90°-Phasenlage phasenrichtig demoduliert werden. Der Referenzträgeroszillator stellt sich in dem geschlossenen Regelkreis auf eine Phasenlage von 90° bezogen auf den Mittelwert der Burstphase bei 180° ein. Dazu wird die über ein Integrationsglied geglättete Ausgangsspannung des Burst-Phasendiskriminators zur Nachstimmung des Referenzträgeroszillators herangezogen. Die nur von den Farbträgeranteilen befreite Ausgangsspannung des Phasendiskriminators dient zur phasenrichtigen Synchronisation des PAL-Multivibrators, der den PAL-Schalter zur Umpolung des Referenzträgers für den (R-Y)- bzw. V-Synchrondemodulator steuert.
Ein Phasenfehler a, den das Farbartsignal auf dem Übertragungsweg in Bezug auf den Burst erfährt, erscheint sowohl beim FU- als auch beim +FV Signal in gleicher Richtung (Bild 2.26). Da in den Synchrondemodulatoren aber nur eine Bewertung der mit dem jeweiligen Referenzträger in Phase liegenden Komponente des zugeführten Signals stattfindet, erhält man am Ausgang des U-Demodulators das Signal

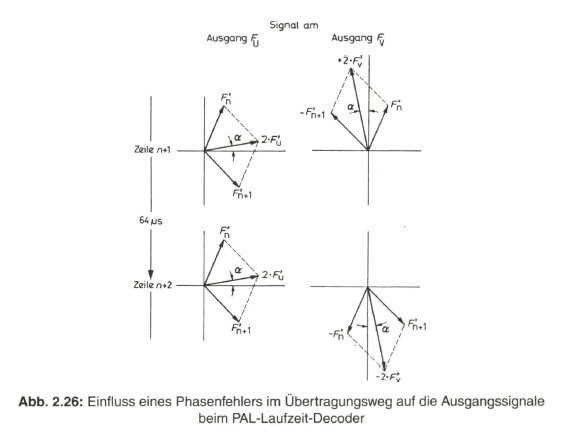
Beide zurückgewonnenen Farbdifferenzsignale, U‘ und V‘, sind durch den Phasenfehler a mit dem selben Faktor cos a behaftet, so dass das Verhältnis V´ / U ‘ gegenüber dem sendeseitigen Wert V / U gleich geblieben ist und damit auch der Farbton, der im Phasenwinkel ![]() enthalten ist, nicht verfälscht wird. Eine gewisse Entsättigung durch die geringere Amplitude der demodulierten Farbdifferenzsignale mit dem Faktor cos a macht sich erst bei größeren Werten des Phasenfehlers bemerkbar.
enthalten ist, nicht verfälscht wird. Eine gewisse Entsättigung durch die geringere Amplitude der demodulierten Farbdifferenzsignale mit dem Faktor cos a macht sich erst bei größeren Werten des Phasenfehlers bemerkbar.
2.4.5 Spektrum des PAL-FBAS-Signals
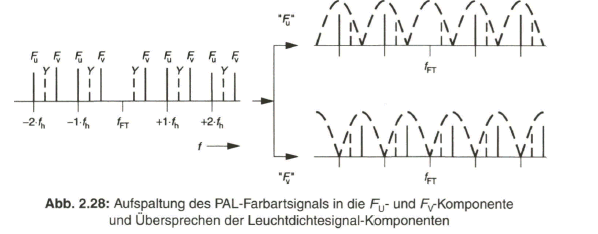
Durch additive Überlagerung des BAS-Signals mit dem Farbartsignal wird das FBAS-Signal gebildet. Die Zeitfunktion des zusammengesetzten Signals zeigt an einem Beispiel mit der Normfarbbalkenfolge Bild 2.19. Im Spektrum des FBAS- Signals treten, bedingt durch den Viertelzeilen-Offset und die zeilenweise Umpolung der FV- Komponente , die Spektralkomponenten des Y- bzw. BAS-Signals und die Spektralkomponenten des bzw. FV- Signals bei verschiedenen Frequenzen auf. Bild 2.27 gibt dies an einem Ausschnitt des Spektrums um die Farbträgerfrequenz wieder. Diese Konstellation erlaubt es, auf der Empfängerseite die Komponenten FU und FV- des Farbartsignals über ein so genanntes Kammfilter von den Komponenten des Y- bzw. BAS-Signals zu trennen. Mit dem üblicherweise technisch realisierten Kammfilter mittels des einfachen PAL-Laufzeit-Decoders gelingt diese Trennung aber nicht vollkommen. Siehe dazu Bild 2.28. Sowohl in dem FU- als auch in dem FV- Signal treten noch Spektralkomponenten des Y- Signals auf, die sich als Übersprechstörung bei Bildvorlagen mit vertikalen Feinstrukturen bemerkbar machen. Man spricht in diesem Fall von „Cross Chrominance“ bzw. „Cross Colour“.
Eine Störung im Leuchtdichtekanal durch den modulierten Farbträger wird als „Cross Luminance“ bezeichnet. Durch die Wahl der Farbträgerfrequenz am oberen Ende des BAS-Spektrums reduziert sich diese Störung schon weitgehend. Zusätzlich wird der Frequenzgang im Leuchtdichtekanal beim PAL- Farbfernsehempfänger meist schon oberhalb von 4 MHz abgesenkt.
Eine nahezu vollkommene Unterdrückung von Cross-Chrominance- und Cross- Luminance-Störungen gelingt mit dem Color-Plus-Verfahren. Es handelt sich hierbei um eine modifizierte Variante des PAL- Verfahrens mit Halbbildspeicherung auf der Encoder- und Decoderseite. Das Color-Plus-Verfahren wird beim PALplus-System eingebracht, bei dem aber als wesentliche Eigenschaft die kompatible Breitbildübertragung im Vordergrund steht.
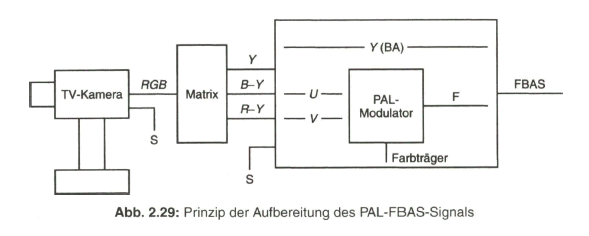
Zusammenfassend zeigt Bild 2.29 nochmals das Prinzip der Aufbereitung des herkömmlichen PAL-FBAS-Signals im Studio. Die technische Erzeugung des PAL-FBAS-Signals erfolgt heute meistens in einem Encoder, der von PAL mit 4:3 Seitenverhältnis auf PALplus mit 16:9-Seitenverhältnis und Color-Plus-Aufbereitung umgeschaltet werden kann. Dieser Encoder basiert vollkommen auf digitaler Signalverarbeitung. Bezogen auf die Prinzipdarstellung in Bild 2.29 bedeutet dies, dass die Signale aus der Matrix, Y, B - Y und R - Y, analog-digital gewandelt werden und das Ausgangssignal des Encoders wieder in ein analoges FBAS-Signal im Frequenzbereich von Null bis fünf MHz übergeführt wird. Als Eingangssignal liegt am Studio-PALplus-Encoder meist das digitale, serielle Komponentensignal (DSC, Digital Serial Components) an. Siehe dazu Näheres im Abschnitt 4, Digitales Video-Studiosignal.
2.5 PALplus-System
Nach verschiedenen Zwischenlösungen zur Qualitätsverbesserung beim PAL- Verfahren und Übergang auf das Breitbildformat wurde auf der Internationalen Funkausstellung 1991 ein neuer Fernseh-Standard unter dem Begriff PALplus der Öffentlichkeit vorgestellt. Als Vorgabe war dabei selbstverständlich die volle Kompatibilität mit dem eingeführten PAL-System zu berücksichtigen, sowohl empfängerseitig als auch weitestgehend auf der Senderseite und bei den hochfrequenten Übertragungskanälen. Die Rundfunkanstalten, insbesondere die öffentlich rechtlichen, übertragen ihre Programmbeiträge zum großen Teil im kompatiblen Breitbildformat.
2.5.1 Merkmale des PALplus-Standards
Gegenüber dem eingeführten Standard-PAL-Verfahren bringt das voll kompatible PALplus-System die Einführung des 16:9-Bildformats und die Unterdrückung der Cross-Colour und Cross-Luminance-Störungen und damit volle Ausnutzung der 5-MHz-Bandbreite für das Leuchtdichtesignal. Die zusätzlich noch vorgesehene digitale Tonsignalübertragung und eine Entzerrung von Echostörungen kamen aus verschiedenen Gründen nicht zum Einsatz. Das Breitbildformat wird auf einem herkömmlichen 4:3-Bildschirm mit den bereits von Breitbildfilmen bekannten schwarzen Streifen am oberen und unteren Bildrand wiedergegeben.
2.5.2 Kompatible Übertragung im 16:9-Bildformat
Nach dem Letterbox-Verfahren wird die 16:9-Bildvorlage so aufbereitet, dass durch Herausnahme von Zeilen aus dem aktiven Raster ein 16:9-Breitbild mit verminderter Bildhöhe auf dem 4:3-Bildschirm wiedergegeben werden kann. Das Bild erscheint damit als in die Breite gezogenes Rechteck, was zu dem Vergleich mit einem „Briefkasteneinwurf” geführt hat. Am oberen und unteren Bildrand treten dabei breite schwarze Streifen auf.
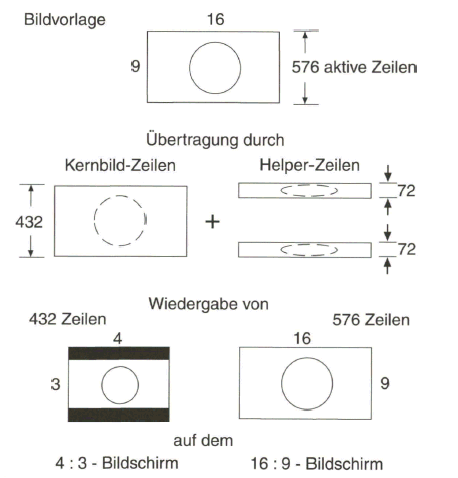
Abb. 2.30: Aufteilung des 16:9-Bildes beim Letterbox-Verfahren in Kernbild- und Helper-Zeilen
Das Prinzip des Letterbox-Verfahrens zeigt Bild 2.30. Die Reduzierung der Bildhöhe erfolgt durch Herausnahme jeder vierten Zeile aus dem aktiven 576-Zeilen- Raster. Durch die Aufbereitung des PALplus-FBAS-Signals mit kompatiblem 16:9- Bildformat und mit dem Color-Plus-Verfahren ist es notwendig, von 575 auf 576 aktive Zeilen im 625-Zeilen-Raster überzugehen, was zudem im digitalen Studiosignal schon vorliegt. Die verbleibenden 432 Zeilen werden entsprechend zusammengeschoben, womit die aktive Bildhöhe sich auf drei Viertel des ursprünglichen Wertes verringert. Dieses so genannte „Kernbild” (oder auch „Letterbox-Bild“) wird in herkömmlicher Weise durch Leuchtdichte- und Farbartsignal übertragen. Die Leuchtdichteinformation der herausgenommenen 144 Zeilen wird am oberen und unteren Bildrand in je 72 „Helper-Zeilen” so übertragen, dass sie für den Stan- dard-PAL-Empfänger unsichtbar bleibt. Der PALplus-Empfänger jedoch verarbeitet die Zusatzinformation in den „Vertikal-Helfern” und rekonstruiert zusammen mit der Information in den 432 Zeilen des Kernbildes das ursprüngliche Farbbild mit 576 sichtbaren Zeilen im 16:9-Breitbildformat.
Die reversible Zeileninterpolation wird nach vereinfachter Darstellung gemäß Bild 2.31 vorgenommen. Die 576 aktiven Zeilen werden dazu in jeweils vier Zeilen, hier mit A, B, C, D bezeichnet, zusammengefasst. Durch eine 4:3-Vertikalfilterung werden daraus drei Zeilen A', B', C' nach der in Bild 2.31 angegebenen Zusammensetzung abgeleitet, deren Information durch Leuchtdichte- und Farbartsignal übertragen wird. Die angegebene Gewichtung in den Zeilen bezieht sich auf den Signalinhalt in übereinanderliegenden Bildpunkten.
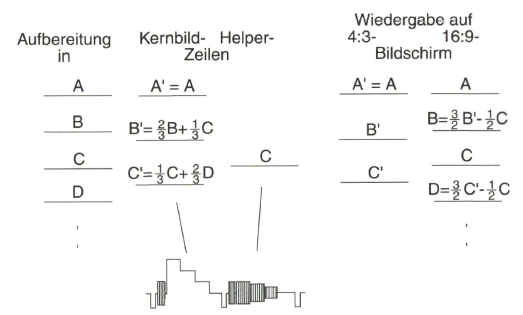
Abb. 2.31: Reversible Zeileninterpolation beim Letterbox-Verfahren in Gruppen von jeweils vier Zeilen
Die jeweils dritte Zeile, C, wird zusätzlich als so genannter „Vertikal-Helfer” so übertragen, dass sie für den Standard-PAL-Empfänger unsichtbar bleibt. Dazu wird das Leuchtdichtesignal dieser Zeile nach einer nichtlinearen Amplituden-Vorverzerrung einem Hilfsträger, für den die Farbträgerschwingung verwendet wird, durch Restseitenband Amplitudenmodulation aufgebracht und mit reduzierter Amplitude um den Schwarzwert herum in den jeweils 72 Zeilen am oberen und unteren Bildrand übertragen. Durch die Trägermodulation wird das resultierende Spektrum der Vertikal-Helfer-Signale von niederfrequenten Anteilen befreit, die sonst bei älteren Fernsehempfängern zu Synchronisationsstörungen führen könnten. Die Amplitude des Vertikal-Helfer-Signals wird auf 300 mV Spitze-Wert symmetrisch um den Schwarzwert, entsprechend der Burst-Amplitude, festgelegt.
2.5.3 Statusbits-Information und Referenzsignale
Die Signalverarbeitung im PALplus-Encoder und Decoder erfolgt abhängig von dem Quellensignal (von der elektronischen Kamera oder vom Filmabtaster), und sie ist auch davon abhängig, ob 4:3 oder 16:9-Bildmaterial vorliegt. Darüber hinaus ist das Einbringen von Untertiteln bei der Letterbox-Übertragung zu berücksichtigen. Hierfür ist es erforderlich, einige Informationen aus dem Studio an den Empfänger zu übertragen. Dazu dient ein Datenwort mit 14 bit, das in vier Funktionsgruppen folgende Information beinhaltet:
- Gruppe 1 Bildformat (3 bit + 1 Paritätsbit) Vollformat 4:3, Letterbox 16:9, Letterbox 14:9, Vollformat 16:9 u. a.
- Gruppe 2 Verbesserte Dienste (4 bit) Kamera-Mode oder Film-Mode, Standard-PAL oder Color-Plus, Helper-Signal ja/nein.
- Gruppe 3 Untertitel (3 bit) Untertitel im Teletext ja/nein, innerhalb oder außerhalb des aktiven Bildes.
- Gruppe 4 (3 bit) ist noch nicht mit Information belegt.
Die Daten werden in der ersten Hälfte der Zeile 23 übertragen. Es wurde der robuste Bi-Phase-Code zur Datenübertragung gewählt mit einer Bitdauer von 1,2 ![]() für jeweils zwei Bi-Phase-Elemente mit je 600 ns, basierend auf einem 5-MHz- Systemtakt. Die Statusbits-Daten beginnen mit einer Run-In-Folge (29 Taktelemente) und einem Start-Code (24 Taktelemente). Die Gesamtdauer des Datenpakets beträgt 27,4
für jeweils zwei Bi-Phase-Elemente mit je 600 ns, basierend auf einem 5-MHz- Systemtakt. Die Statusbits-Daten beginnen mit einer Run-In-Folge (29 Taktelemente) und einem Start-Code (24 Taktelemente). Die Gesamtdauer des Datenpakets beträgt 27,4 ![]() .
.
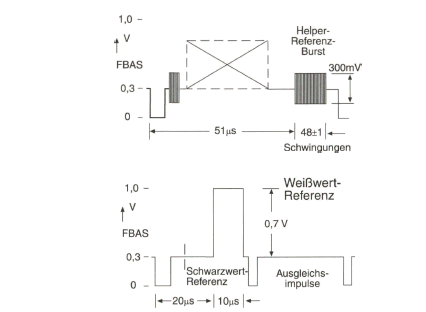
Abb. 2.32: a) Datenpaket und Helper-Referenz-Burst in Zeile 23
b) Weiß-Referenzsignal in Zeile 623
Von den im 270-Mbit/s-Videodatenstrom enthaltenen 576 aktiven Zeilen werden im PALplus-Encoder tatsächlich nur 574 aktive Zeilen in das PALplus-Signal übernommen. Es sind dies die Zeilen 24 bis 310 und 336 bis 622, wobei sich nun die Kernbild- oder Letterbox-Zeilen auf 2 mal 215, d. h. insgesamt 430 verringern.
Die Zeile 23 enthält nach dem Datenpaket einen Helper-Referenz-Burst, in dem eine Folge von 48 Farbträgerschwingungen mit einer Spitze-Spitze-Amplitude von 300 mV (Maximalwert für die Helper-Signale) mit der Phase 180° übertragen wird (Bild 2.32 a). Dieser Amplitudenwert steht in definierter Beziehung zum Weißwert des Leuchtdichtesignals in den Kernbild-Zeilen, der mit einem 10 ![]() breiten Impuls in der von Bildinhalt freigehaltenen ersten Hälfte der Zeile 623 als Referenz eingebracht wird (Bild 2.32 b).
breiten Impuls in der von Bildinhalt freigehaltenen ersten Hälfte der Zeile 623 als Referenz eingebracht wird (Bild 2.32 b).
3. Trägerfrequente Übertragung von analogem Bild- und Tonsignal
Die Übertragung des Bildsignals bzw. genauer des FBAS-Signals sowie eines zum Bild gehörigen Begleittones erfolgt, abgesehen von der Verteilung im Studio und von einer digitalen Signalverteilung, durch Modulation einer hochfrequenten Trägerschwingung. Prinzipiell gilt dies sowohl für drahtgebundene als auch für drahtlose Übertragung. Von den Funk-Verwaltungsorganen wurden bestimmte Frequenzbereiche festgelegt, die ausschließlich oder vorwiegend zur Übertragung von Fernsehsignalen im Bereich des Rundfunk-Fernsehens dienen. Diese liegen im VHF-Bereich (40 bis 300 MHz) und im UHF-Bereich (300 bis 870 MHz). Nähere Angaben dazu in Bild 3.12. Darüber hinaus wird für die Satellitenübertragung zum Fernsehteilnehmer der Frequenzbereich im KV- Band von 10,7 bis 12,75 GHz benutzt. Siehe dazu Bild 3.13.
3.1 Terrestrischer Funkkanal und Kabelkanal
3.1.1 Bildsignalübertragung durch Restseitenband-Amplitudenmodulation
Beim Fernseh-Rundfunk im VHF- und UHF-Bereich sowie in Übertragungssystemen, wo übliche Fernsehempfänger über den Antennenanschluss als Bildwiedergabegeräte verwendet werden, erfolgt die Bildsignalübertragung durch Amplitudenmodulation (AM) der hochfrequenten Trägerschwingung. Der Vorteil der Amplitudenmodulation liegt in der relativ geringen Bandbreite des Modulationsproduktes. Es entstehen bei dieser Modulationsart Seitenschwingungen im Abstand der Frequenz des modulierenden Signals oberhalb und unterhalb der Frequenz der Trägerschwingung. Mit einer Bandbreite des FBAS-Signals von Bvideo = 5 MHz wird damit ein hochfrequentes Übertragungsband mit der Bandbreite Bam = 2 x 5 MHz = 10 MHz beansprucht (Bild 3.1 a).
Abb. 3.1: Hochfrequentes Übertragungsband bei
(a) Amplitudenmodulation (b) Einseitenband-Amplitudenmodulation
(c) Restseitenband-Amplitudenmodulation
Prinzipiell könnte bei der Übertragung ein Seitenband unterdrückt werden, da ja der Signalinhalt in beiden Seitenbändern gleichermaßen enthalten ist. Man käme so mit der Einseitenband-Amplitudenmodulation (ESB-AM, EM) wieder auf eine Übertragungsbandbreite von Bem = 5 MHz (Bild 3.1 b). Wegen des bis zu sehr niedrigen Frequenzen reichenden Modulationssignals und der deshalb notwendigen steilflankigen Filter zur Unterdrückung eines Seitenbandes ergeben sich jedoch enorme Schwierigkeiten durch die Gruppenlaufzeitverzerrung dieser Filter an der Grenze des Durchlassbereiches.
Das Problem wird dadurch umgangen, dass an Stelle der Einseitenband-Amplitudenmodulation die Restseitenband-Amplitudenmodulation (RSB-AM, RM) angewendet wird. Dabei überträgt man ein Seitenband vollständig und das andere Seitenband nur teilweise mit relativ langsam abfallender Amplitude nach höheren Modulationsfrequenzen hin (Bild 3.1 c). Die Einsparung an Frequenzbandbreite beträgt gegenüber der Zweiseitenband-Amplitudenmodulation (AM) immer noch etwa 4 MHz. Für Modulationssignale mit einer Frequenz bis 0,75 MHz liegt Zweiseitenband-Übertragung vor, bei höherfrequenten Signalkomponenten findet ein Übergang auf Einseitenband-Übertragung statt.
Empfängerseitig muss aber dafür gesorgt werden, dass die Signalkomponenten, die auch im Restseitenband enthalten sind, nach der Demodulation nicht mit doppelter Amplitude erscheinen gegenüber den Signalkomponenten, die nur in einem Seitenband übertragen werden. Es wird deshalb die Empfänger-Durchlasskurve so ausgebildet, dass sich um die Frequenz des Bildträgers eine linear ansteigende bzw. abfallende Flanke ergibt, die so genannte NYQUIST-Flanke (Bild 3.2).
Abb. 3.2: Korrektur des Amplitudenfrequenzgangs bei Restseitenbandübertragung durch ein Empfängerfilter mit NYQUIST-Flanke
Den einzelnen Fernsehkanälen sind im VFIF-Bereich (Band I und III) 7 MFIz breite (ITU-R BT.624, System B) und im UHF-Bereich (Band IV und V) 8 MHz breite (System G) Frequenzbänder zugeteilt. Der hochfrequente Bildsender-Amplitudenfrequenzgang innerhalb des 7 bzw. 8 MHz breiten Fernsehkanals ist in Bild 3.3 dargestellt. Die International Telecommunication Union (ITU), mit dem Radiocommunication Sector (RS) hat 1992 die vom Comite Consultant International des Radiocommunications (CCIR) früher festgelegten Standards übernommen.
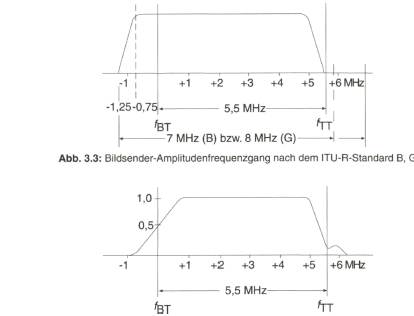
Abb. 3.4: Empfänger-Durchlasskurve mit NYQUIST-Flanke
Bild 3.4 zeigt die Empfänger-Durchlasskurve bezogen auf den Hochfrequenzbereich (HF) mit der NYQUIST-Flanke. Der Übergang vom Durchlass- zum Sperrbereich erfolgt in einem Frequenzbereich von ± 0,75 MHz um die Frequenz des Bildträgers. Bei der Bildträgerfrequenz selbst beträgt der Dämpfungsanstieg gegenüber dem voll übertragenen Seitenband 6 dB, das heißt, die Amplitude des Bildträgers wird auf 50 % ihres eigentlichen Wertes abgesenkt.
Die wesentliche Verstärkung und Selektion wird beim Fernsehempfänger im Zwischenfrequenzbereich (ZF) vorgenommen. Für den Bildträger ist eine Zwischenfrequenz von 38,9 MHz festgelegt. Durch die Frequenzumsetzung mit einer Oszillatorfrequenz oberhalb der Empfangsfrequenz findet eine Umkehrung der Frequenzlage des übertragenen Seitenbandes statt (Bild 3.5). Ebenso erscheint die im Hochfrequenzbereich nach dem ITU-R-Standard B und G um 5,5 MHz oberhalb der Bildträgerfrequenz liegende Tonträgerfrequenz im ZF-Bereich um 5,5 MHz unterhalb des Bildträgers bei 33,4 MHz. Die Empfänger-Durchlasskurve für den ZF-Bereich gibt Bild 3.6 wieder.
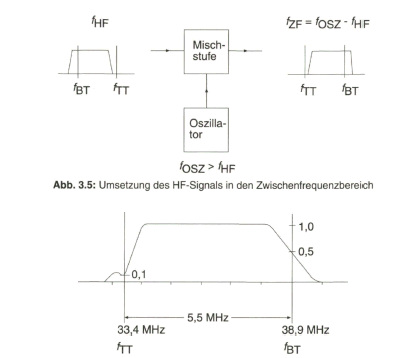
Abb. 3.6: Empfänger-Durchlasskurve im Zwischenfrequenzbereich
Die Modulation des hochfrequenten Bildträgers durch das FBAS-Signal erfolgt als negative Amplitudenmodulation, das heißt, hellen Bildstellen entspricht eine niedrige Trägeramplitude, und der Synchronimpuls ruft eine maximale Trägeramplitude hervor (Bild 3.7). Bezogen auf den Synchronspitzenwert mit 100 % liegt der Austastwert oder Schwarzwert bei 75 % und der Weißwert bei 10 %. Ein Restträger als Weißwert von 10 % ist notwendig wegen der Anwendung des Intercarrier- Tonträger-Verfahrens im Empfänger (siehe Abschnitt 3.1.2). Der Vorteil der Negativmodulation liegt unter anderem in einer günstigen Ausnutzung der Senderleistungsstufe, weil die Maximalleistung nur kurzzeitig während der Synchronimpulse aufgebracht werden muss, sowie in der periodisch während der Synchronimpulse auftretenden Maximalamplitude des Trägers als Bezugswert für die automatische Verstärkungsregelung im Empfänger.
Die durch die Restseitenband-Amplitudenmodulation bedingten Verzerrungen des demodulierten Signals bei Hüllkurvendemodulation werden vermieden durch Anwendung der Synchrondemodulation. Der dazu notwendige Referenzträger wird aus dem übertragenen RSB-AM-Modulationsprodukt durch eine Bandbegrenzung auf etwa ±0,5 MHz um den Bildträger und anschließende Amplitudenbegrenzung gewonnen (Bild 3.8).
3.1.2 Tonsignalübertragung durch Frequenzmodulation
Der Begleitton wird beim Fernseh-Rundfunk in den VHF- und UHF-Fernsehkanälen durch Frequenzmodulation der hochfrequenten Tonträgerschwingung übertragen. Nach dem ITU-Standard, System B und G liegt die Frequenz des Tonträgers um 5,5 MHz oberhalb des zugehörigen Bildträgers in dem 7 bzw. 8 MHz breiten Fernsehkanal. Der Frequenzhub beträgt maximal 50 kHz. Das Tonsignal, das im Frequenzbereich von 40 Hz bis 15 kHz übertragen wird, erfährt eine Preemphase mit der Zeitkonstante von 50 ps, was empfangsseitig zu einer Verbesserung des Signal-zu-Geräusch-Abstandes im demodulierten Signal führt. Das Verhältnis von Tonträgerleistung zu Bildträgerleistung am Senderausgang wurde in Schritten von 1:5 beim Schwarzweiß-Fernsehen auf 1:10, bei Einführung des Farbfernsehens auf heute üblicherweise nur noch 1:20 für den Haupttonträger bei Zwei-Ton-Übertragung reduziert.
Nach dem Intercarrier-Ton-Verfahren wird im ZF-Teil des Empfängers durch Mischung von Bild- und Tonträger im Videodemodulator ein durch das Tonsignal frequenzmodulierter Differenzträger (Intercarrier) mit der Frequenz von 5,5 MHz gewonnen. In einem eigenen 5,5-MHz-Ton-ZF-Kanal wird dieser FM-Träger verstärkt, amplitudenbegrenzt und demoduliert (Bild 3.9). Eine Anwendung dieses Verfahrens setzt allerdings voraus, dass die Amplitude des Bildträgers bei der Überlagerung stets größer ist als die des Tonträgers, um eine Amplitudenmodulation des Differenzträgers durch den Bildinhalt und die Synchronimpulse, insbesondere durch die Vertikal-Synchronimpulse mit 50 Hz Folgefrequenz, zu vermeiden. Man erreicht dies durch ein entsprechendes Bild-zu-Tonträger-Leistungsverhältnis und die Weißwertbegrenzung. Eine unvermeidliche geringe Amplitudenmodulation des Differenzträgers wird im Amplitudenbegrenzer vor dem FM-Demodulator unterdrückt.
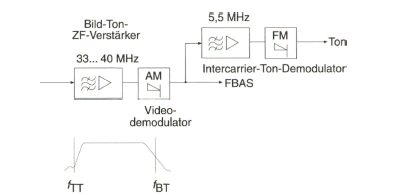
Abb. 3.9: Intercarrier-Ton-Verfahren mit Bildung der Intercarrier-Zwischenfrequenz im Videodemodulator
Heute üblich ist die Anwendung des Quasi-Parallel-Ton-Verfahrens. Im Prinzip liegt das Intercarrier-Ton-Verfahren zugrunde mit der Mischung von Bildträger und Tonträger. Die 5,5-MHz-lntercarrier-Ton-ZF wird jetzt in einer Mischstufe erzeugt, der von einem gemeinsamen Breitband-ZF-Verstärker das Ton-ZF-Signal mit der Frequenz 33,4 MHz und der unmodulierte Bildträger, durch Selektion aus dem Spektrum des AM-Modulationsprodukts hervorgehoben, mit etwa gleicher Amplitude zugeführt werden (Bild 3.10). Der Pegel des 5,5-MHz-Tonträgers ist dadurch um 20 dB angehoben, was selbst bei Übermodulation des Bildsenders bei kritischem Farbbildinhalt (z.B. gelbe Schrifteinblendungen) noch einen Signal-zu-Stör-Abstand von 40 dB gegenüber einem vergleichbaren Wert von 0 dB bei dem einfachen Intercarrier-Ton-Verfahren ergibt. Der durch Selektion und Amplitudenbegrenzung gewonnene Referenzträger wird gleichzeitig zur Synchrondemodulation bei der Rückgewinnung des Bildsignals verwendet.
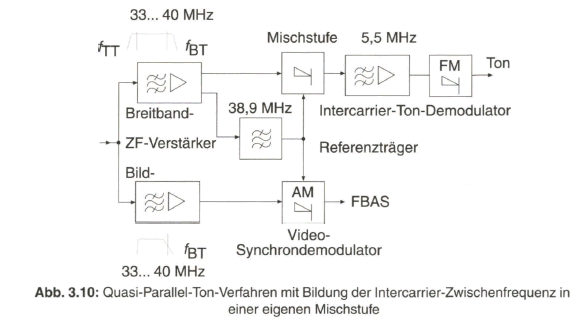
3.1.3 Zwei-Tonträger-Verfahren
Verschiedene Gründe, wie z. B. mehrsprachiger Begleitton zum Fernsehbild, Filmbeiträge mit Originalton und Übersetzung oder auch Stereo-Tonübertragung, führten zu der Einführung des Zwei-Tonträger-Verfahrens in den terrestrischen Funk- und Kabelkanälen. Dabei wird zwischen dem ersten Tonträger (Haupttonträger), 5,5 MHz oberhalb des Bildträgers, und dem oberen Nachbarkanal ein zweiter Tonträger etwa 5,75 MHz oberhalb des Bildträgers eingefügt, der durch ein zweites Tonsignal ebenfalls frequenzmoduliert wird (Bild 3.11). Um Störungen zu vermeiden, wird die Leistung des zweiten Tonträgers auf ein Fünftel der Leistung des ersten Tonträgers abgesenkt. Die Frequenz des zweiten Tonträgers ist nicht genau um 250 kHz gegenüber der des ersten Tonträgers versetzt, da dies ein ganzzahliges Vielfaches der Zeilenfrequenz wäre und zu Störungen führen könnte. Man wählt vielmehr den so genannten Halbzeilen-Offset mit einer Frequenzdifferenz von 15,5 • 15,625 kHz = 242,1875 kHz, was eine Tonträgerfrequenz von 5,742... MHz oberhalb des Bildträgers ergibt.
Die beiden Tonträger liegen somit innerhalb der Fernsehkanäle bei den Frequenzen

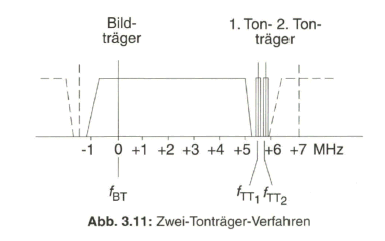
Bei der Zweikanal-Tonübertragung unterscheidet man drei mögliche Betriebsarten:
Mono-, Stereo- und Zweiton-Übertragung.
Bei der Mono-Übertragung werden der 1. Tonträger und der 2. Tonträger mit dem gleichen Signal (Ton 1) moduliert. Zusätzlich überträgt der 2. Tonträger einen Pilotton mit der Frequenz
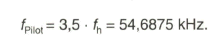
Im Falle der Stereo-Übertragung hat sich gezeigt, dass mit der beim Hörrundfunk üblichen Matrizierung der L- und R-Signale unterschiedliche Störabstandswerte in den beiden empfängerseitigen Stereokanälen auftreten. Die Ursache dafür liegt in einer teilweisen Korrelation der Störsignale, die gerade beim Intercarrier-Tonverfahren entstehen. Durch eine abgeänderte Matrizierung der L- und R-Signale wird dies vermieden.
Dem 1.Tonträger wird nun das Mittensignal M = 1/2 ■ (L + R) aufmoduliert. Der 2.Tonträger überträgt das R-Signal und den Pilotton, der nun mit einer Kennfrequenz von
fh /133 = 117,4812 Hz* 117,5 Hz
amplitudenmoduliert ist.
Bei der Zweiton-Übertragung werden auf dem 1. und 2. Tonträger die unterschiedlichen Tonsignale (Ton 1 und Ton 2) übertragen. Auf dem 2. Tonträger ist in diesem Fall der Pilotton mit einer Kennfrequenz von
fh 157 = 274,1228 Hz = 274,1 Hz
amplitudenmoduliert.
3.1.4 Frequenzbereiche und Fernsehkanäle
Die Verteilung von Fernsehsignalen erfolgt im terrestrischen Funkkanal und Kabelkanal im VHF- und UHF-Bereich bei Frequenzen zwischen 100 und 1000 MHz. Nach internationaler Frequenzplanung sind in Europa Fernsehkanäle mit 7 MHz bzw. 8 MHz Bandbreite festgelegt worden, die verteilt sind auf die Bänder I und III, sowie für Kabelübertragung zusätzlich auf den unteren und oberen Sonderkanalbereich im VHF-Frequenzbereich bis 300 MHz und auf die Bänder IV und V sowie den erweiterten Sonderkanalbereich für Kabelübertragung im UHF-Frequenzbereich. Bild 3.12 zeigt die Zuordnung der Fernsehkanäle als terrestrische Funkkanäle und Kabelkanäle (K) bzw. nur Kabelkanäle (SK).
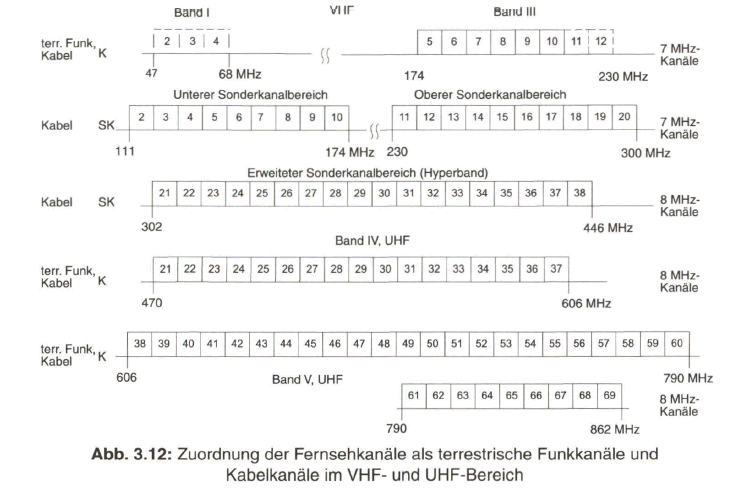
Die Kanäle 1 und 70 sowie der Sonderkanal 1 an den Bandgrenzen wurden als Sicherheitsabstand bzw. wegen einer Überschneidung mit dem UKW-FM-Rundfunkband im Frequenzbereich 87,5 MHz bis 108 MHz nicht als Fernsehkanäle zugeteilt. Die Kanäle 2, 3 und 4 im Band I werden sowohl im terrestrischen Fernsehen als auch insbesondere im Kabelkanal schon jetzt frei gemacht und zukünftig nicht mehr als Fernsehkanäle belegt, weil sie für andere Dienste genutzt werden sollen. So wird zukünftig in den Breitbandkabelnetzen im Frequenzbereich von 10 bis 65 MHz Datenverkehr in Hin- und Rückrichtung (Telefon-, Internetverbindungen u. a.) abgewickelt.
3.2 Satellitenkanal
3.2.1 Bildsignalübertragung durch Frequenzmodulation
Großflächige Versorgungsbereiche (europaweit) werden von „Sendestationen” im geostationären Orbit abgedeckt. Die Fernseh-, Radio- und Datenübertragung erfolgt über so genannte Transponder im Satelliten. Man versteht darunter einen Empfangsteil, der das Mikrowellensignal im „Uplink” von der Bodenstation zum Satelliten aufnimmt, auf eine andere, meist niedrigere Frequenz umsetzt und verstärkt und mit einer Senderleistung von 50 bis 100 W im „Downlink” wieder gebündelt abstrahlt. Derzeit wird für die Abwärtsstrecke der Frequenzbereich von 10,7 bis 12,75 GHz ausgenutzt. Zukünftig sind, insbesondere dann nur für digitale Signale, auch noch höhere Frequenzbänder (bei 21 GHz, 42 GHz und 84 GHz) vorgesehen.
Die so genannten Direktempfangssatelliten für den europäischen Raum werden betrieben von der SES ASTRA mit derzeit (August 2004) den Satelliten (Flugmodellen) ASTRA -1B, -1C, -1E, -1F, -1G, -1H und -2C auf der Orbitposition 19,2° Ost sowie von der EUTELSAT mit den Satelliten HOT BIRD auf der Orbitposition 13° Ost und EUROBIRD auf 25,5° und 28,5° Ost.
Bild 3.13 zeigt die Aufteilung des Frequenzbereiches von 10,7 bis 12,75 GHz im KU- Band auf die einzelnen Teilbänder am Beispiel des ASTRA-Satellitensystems. Für analoge Fernsehsignalübertragung werden, früher ausschließlich und heute noch überwiegend, die Bänder (A), B, C und (D) im Frequenzbereich von 10,7 bis 11,7 GHz benutzt. Die in Klammern angegebenen Bänder stehen für Reservezwecke zur Verfügung. Im Frequenzbereich von 11,7 bis 12,75 GHz werden digitale Fernsehsignale übertragen. Siehe dazu Näheres im Abschnitt 11.

In aufeinanderfolgenden Transponderkanälen wird abwechselnd mit horizontaler (H) und vertikaler (V) Polarisation übertragen.
Die Bandbreite der ASTRA-Transponder für analoge Fernsehsignalübertragung beträgt 26 MHz. Diese ist notwendig, um mit Frequenzmodulation einen Spitze- zu-Spitze-Frequenzhub von 2 • AFT =10 MHz bei der neutralen Frequenz der Preemphase im Videofrequenzband zu gewährleisten. Das FBAS-Signal wird überein Preemphase-Netzwerkdem FM-Modulator zugeführt. Man erreicht damit eine bessere Ausnutzung des Aussteuerbereiches und mit der zugehörigen Deemphase auf der Empfängerseite nach dem FM-Demodulator eine Absenkung der höherfrequenten Rauschanteile im Videosignal.
3.2.2 Tonsignalübertragung mit FM-Unterträger
Die Übertragung des Begleittones im analogen Satellitenkanal erfolgt über frequenzmodulierte Unterträger im Frequenzbereich oberhalb des FBAS-Signals. Das übertragene Basisband wird in diesem Fall bis etwa 8,5 MHz erweitert. Auf einem Unterträger bei 6,5 MHz wird der Hauptton, bei Stereosignalübertragung L+R, auf weiteren Unterträgern bei 7,02 und bei 7,20 MHz werden zusätzlich das Links- und Rechtssignal getrennt übertragen. Empfängerseitig werden nach FM-Demodulation des Basisbandes über einen 5-MHz-Tiefpass das FBAS-Signal und über Bandpässe bei 6,5 MHz sowie bei 7,02 und 7,20 MHz die analog modulierten Unterträger gewonnen und dementsprechenden FM-Demodulatoren zugeführt. Die Bandbreite der analog modulierten Unterträger beträgt 130 kHz.
Über einen ASTRA-Transponder können im Basisband oberhalb des FBAS-Signals bis zu sechs analog modulierte Unterträger oder zwölf digital modulierte Unterträger für Tonsignale oder Datendienste genutzt werden. Meistens werden neben dem analogen Fernsehbegleitton als Hauptton und über getrennte L- und R-Signale noch zusätzlich digitale Hörfunkprogramme nach dem ADR-Verfahren (ASTRA Digital Radio) übertragen. Es kommt die 4-Phasenumtastung zur Anwendung mit einer übertragenen Bitrate von 192 kbit/s auf jedem Unterträger. Bei einer Datenreduktion mit dem MUSICAM-Verfahren (siehe Abschnitt 6) kann damit nahezu CD-Tonqualität übertragen werden. Bild 3.14 zeigt die Belegung des durch Frequenzmodulation im Satellitenkanal übertragenen Basisbandes.

4. Digitales Video-Studiosignal
Die im Abschnitt 2 beschriebene Aufbereitung des FBAS-Signals führt zu dem analogen Video-Studiosignal, das heute nur noch selten direkt in Erscheinung tritt. Abgesehen von dem FBAS-Signal als Endprodukt, welches nach wie vor durch Modulation einer Trägerschwingung in den analogen TV-Kanälen übertragen wird, werden im Studio fast nur noch digitale Signale verarbeitet. Nachdem das Quellensignal zunächst mit den Farbwertsignalen R, G, B und nach einer Matrizierung in die Komponentensignale Y und B-Y, R-Y in analoger Form vorliegt, ist eine Analog-Digital-Wandlung in den drei Signalkanälen notwendig. Die digitalen Komponentensignale werden dann zu einem Zeitmultiplexsignal zusammengefasst, das entweder für die weitere Signalverarbeitung bitparallel auf einer Anzahl von N Leitungen, mit N als der Codewortlänge, und einer zusätzlichen Taktleitung verteilt wird, oder nach Parallel-Seriell-Wandlung in das digitale, serielle Komponentensignal (Digital Serial Components, DSC) mit einer Bitrate von 270 Mbit/s, an digitale Verteilkanäle mit Koaxialleitungen oder Glasfaserverbindungen weitergegeben wird (Bild 4.1).
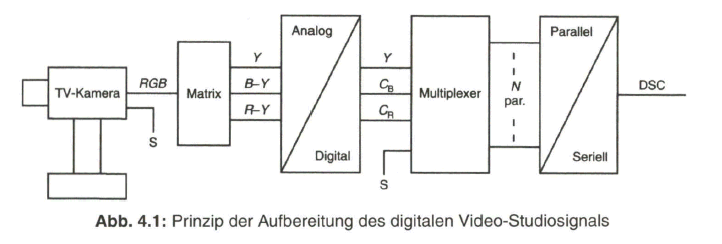
Im Studiobereich kann das digitale Programmsignal nach Demultiplexen und Digital-Analog-Wandlung über eine entsprechende Aufbereitung in einem PAL- oder PALplus-Encoder für das „analoge Fernsehen“ wieder als FBAS-Signal bereitgestellt werden oder, wie später ausführlich beschrieben, über einen MPEG-Encoder für das „digitale Fernsehen“ einen Programmbeitrag zu dem digitalen Sende- Transportstrom liefern.
4.1 Analog-Digital-Wandlung
4.1.1 Pulscodemodulation (PCM)
Grundlage für die digitale Signalaufbereitung bildet das Verfahren der Pulscodemodulation zur Analog-Digital-Wandlung. Das Prinzip der Signalwandlung sei am Beispiel eines einfachen BA-Signals mit kontinuierlich abfallender Helligkeit über eine Zeile demonstriert (Bild 4.2). Das Eingangssignal wird, nach Bandbegrenzung über einen Tiefpass auf die maximale Signalfrequenz, in einem ersten Schritt mit kurzen Impulsen periodisch abgetastet.
Die Folgefrequenz der Impulse, das heißt die Abtastfrequenz ![]() , muss gemäß dem Abtasttheorem von Shannon mindestens den doppelten Wert der maximalen Signalfrequenz aufweisen.
, muss gemäß dem Abtasttheorem von Shannon mindestens den doppelten Wert der maximalen Signalfrequenz aufweisen.
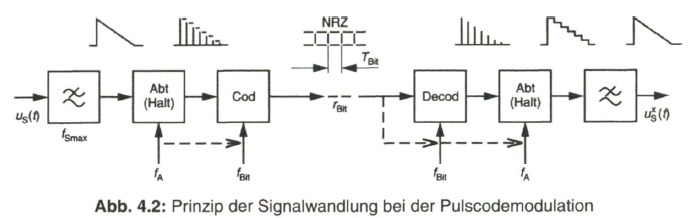
Wegen der nicht idealen Bandbegrenzung durch den vorangehenden Tiefpass wird die Abtastfrequenz praktisch immer bei einem höheren Wert, etwa um den Faktor 1,1 ... 1,3 oder sogar noch höher, liegen.
Bei der Abtastung von Tonsignalen mit kurzen Impulsen wird der jeweilige Abtastwert über die Abtast-Periodendauer ![]() in einer Abtast-Halte-Schaltung (engl, sample and hold) gespeichert, um dem Codierer das Signal über eine längere Zeitdauer zur Verarbeitung anzubieten. Bei der Abtastung von Videosignalen mit längeren Impulsen entfällt diese Haltefunktion. Es folgt dann die eigentliche Analog-Digital-Umsetzung über die Codierung der Abtastwerte, indem diese innerhalb eines Quantisierungsbereiches mit insgesamt s Quantisierungsintervallen in binäre Codeworte mit jeweils
in einer Abtast-Halte-Schaltung (engl, sample and hold) gespeichert, um dem Codierer das Signal über eine längere Zeitdauer zur Verarbeitung anzubieten. Bei der Abtastung von Videosignalen mit längeren Impulsen entfällt diese Haltefunktion. Es folgt dann die eigentliche Analog-Digital-Umsetzung über die Codierung der Abtastwerte, indem diese innerhalb eines Quantisierungsbereiches mit insgesamt s Quantisierungsintervallen in binäre Codeworte mit jeweils ![]() bit umgesetzt werden. Es gilt der Zusammenhang:
bit umgesetzt werden. Es gilt der Zusammenhang:
![]()
Bei Video-A-D-Wandlern kommt das Parallelumsetzverfahren zur Anwendung (siehe 4.1.2), wo zunächst das Codewort mit (n) bit an (n) parallelen Ausgängen des Coders für jeweils die Abtastperiodendauer TA vorliegt. Nach anschließender Parallel-Serien-Wandlung gewinnt man ein serielles binäres Signal im NRZ-Code (Non Return to Zero) mit der Bitdauer Tbit bzw. der Bitrate Rbit .
Es gelten die Beziehungen

Empfangsseitig wird das serielle binäre Codesignal mit dem eigenen Bit-Takt übernommen, der aus dem übertragenen Codesignal zurückgewonnen wird. Nach einer Serien-Parallel-Wandlung präsentiert sich jedes Codewort durch einen analogen Spannungswert, der dem Mittelwert des übertragenen Quantisierungsintervalls entspricht. Die ursprünglich wertkontinuierlichen Abtastwerte erscheinen nun als quantisierte Abtastwerte, wodurch eine Quantisierungsverzerrung auf das übertragene Signal eingebracht wird, das sich als „Quantisierungsrauschen“ bemerkbar macht.
Die Auswirkung der Quantisierungsverzerrung ist dann vernachlässigbar, wenn sie vom menschlichen Sinnesorgan nicht mehr wahrgenommen wird. Das Auge kann maximal etwa 250 verschiedene Helligkeitsstufen zwischen Weiß und Schwarz unterscheiden, so dass bei Videosignalen prinzipiell mit einer 8-bit- Codierung gearbeitet werden kann. Bei monochromen Bildvorlagen zeigte sich jedoch mit der 8-bit-Codierung ein sichtbares Quantisierungsrauschen.
Auch unter Berücksichtigung von Rundungsfehlern bei der digitalen Signalverarbeitung war es deshalb angebracht, bei Videosignalen im Studio auf eine 10-bit-Codierung überzugehen.
Bei Tonsignalen ist unter Berücksichtigung des wesentlich höheren Dynamikbereiches des menschlichen Gehörs eine Codierung mit mindestens 12 bit oder mehr, üblicherweise 16 bit, notwendig. Bei der Übertragung von Tonsignalen wird decoderseitig wieder über eine Abtast-Halte-Schaltung eine „Verlängerung“ der kurzen Impulse vorgenommen, die vom Decoder als quantisierte Abtastwerte ausgegeben werden. Die damit erhaltene Treppenspannung weist einen um den Faktor der Impulsverlängerung höheren Signalwert gegenüber den kurzen Impulsen auf. Bei der Digital-Analog-Wandlung mit Videosignalen entfällt die eigene Abtast-Halte-Schaltung, weil der D-A-Wandler den quantisierten Abtastwert im Abtast-Takt nahezu über die volle Abtastperiodendauer ![]() ausgibt.
ausgibt.
Ein nachfolgendes Tiefpassfilter (Rekonstruktionsfilter) glättet den Treppenspannungsverlauf und unterdrückt Signalanteile aus dem Spektrum der Treppenspannung oberhalb der maximal zu übertragenden Signalfrequenz ![]() . Für das Quantisierungsrauschen verantwortlich sind daher nur dessen Spektralanteile im Bereich bis
. Für das Quantisierungsrauschen verantwortlich sind daher nur dessen Spektralanteile im Bereich bis ![]() .
.
Mit dieser prinzipiellen Darstellung des Vorgangs bei der Pulscodemodulation ist die Markierung der Codeworte durch ein „Startsignal“ nicht berücksichtigt. Diese erfolgt technisch im Zusammenhang mit der Multiplexbildung.
4.1.2 Video-Analog-Digital- und -Digital-Analog-Wandler
Wie schon im Abschnitt 4.1.1 erwähnt, arbeiten Video-A-D-Wandler nach dem Parallelumsetzverfahren, das mit einer sehr kurzen Umwandlungszeit verbunden ist. Im Englischen werden solche A-D-Wandler deshalb auch als „Flash Converter“ bezeichnet. Die prinzipielle Realisierung eines solchen Parallelumsetzers zeigt Bild 4.3.
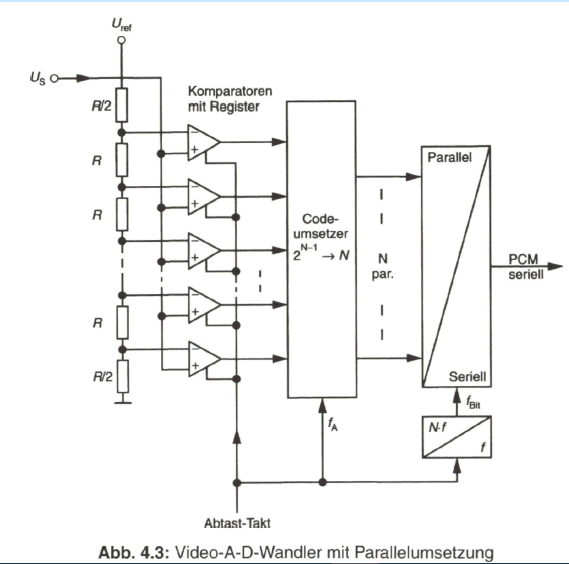
Nach Tiefpass-Bandbegrenzung wird das analoge Eingangssignal gleichzeitig an die nichtinvertierenden Eingänge von 2N-1 Komparatoren angelegt. Die invertierenden Eingänge der Komparatoren liegen an den Abgriffen eines Spannungsteilers, der die Referenzspannung ![]() in
in ![]() Teilspannungen umsetzt und damit die in gleichen Schritten ansteigende Vergleichsspannung an die Komparatoren liefert. Die Komparatoren werden mit dem Abtast-Takt aktiviert. Es findet in diesem Teil des A-D-Wandlers somit die Abtastung des Eingangssignals mit Impulsen der Dauer von nahezu TA und die Quantisierung und Zuordnung der Abtastwerte auf die s =
Teilspannungen umsetzt und damit die in gleichen Schritten ansteigende Vergleichsspannung an die Komparatoren liefert. Die Komparatoren werden mit dem Abtast-Takt aktiviert. Es findet in diesem Teil des A-D-Wandlers somit die Abtastung des Eingangssignals mit Impulsen der Dauer von nahezu TA und die Quantisierung und Zuordnung der Abtastwerte auf die s = ![]() Quantisierungsintervalle statt. Die logischen Ausgangszustände der Komparatoren werden in einem Register „gehalten“ und im nachfolgenden Code-Umsetzer auf die N parallelen Ausgänge gegeben. Der Parallel-Seriell-Umsetzer schließlich liefert dann das serielle binäre Codesignal.
Quantisierungsintervalle statt. Die logischen Ausgangszustände der Komparatoren werden in einem Register „gehalten“ und im nachfolgenden Code-Umsetzer auf die N parallelen Ausgänge gegeben. Der Parallel-Seriell-Umsetzer schließlich liefert dann das serielle binäre Codesignal.
Beim D-A-Wandler wird von den N Bits eines Codewortes jeweils eine Stromquelle aktiviert, die entsprechend der Wertigkeit des Bits einen Anteil zum Summenstrom des Ausgangssignals beiträgt. An einem Arbeitswiderstand bzw. am Ausgang eines als Strom-Spannungswandler arbeitenden Operationsverstärkers liegt die dem Codewort zugeordnete analoge Spannung an.
An Stelle der Stromquellen tritt vielfach ein R-2R-Widerstandsnetzwerk, das von einem Referenzstrom gespeist wird oder an einer Referenzspannung liegt (Bild 4.4). Die Einzelströme sind mit Hilfe dieses Netzwerks nach Zweierpotenzen abgestuft. Über Transistorschalter werden die Anzapfungen des Netzwerks an den analogen Ausgang oder nach Masse gelegt. Das R-2R- Netzwerk gewährleistet eine konstante Belastung der Referenzspannung.
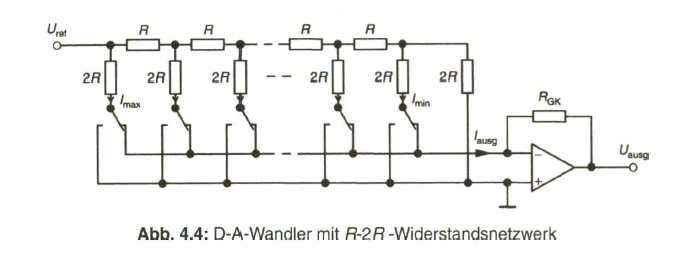
4.1.3 Berechnung des Signal-zu-Quantisierungsgeräusch- Abstandes
Das durch die Quantisierungsverzerrung verursachte Quantisierungsgeräusch kann über den Effektivwert der Quantisierungsfehlerspannung ![]() als Differenz zwischen dem Eingangssignal
als Differenz zwischen dem Eingangssignal ![]() und dem Ausgangssignal
und dem Ausgangssignal ![]() des gesamten Encoder-Decoder-Systems berechnet werden.
des gesamten Encoder-Decoder-Systems berechnet werden.
Für den Effektivwert ![]() als quadratischer Mittelwert erhält man mit s Quantisierungsintervallen im Aussteuerbereich
als quadratischer Mittelwert erhält man mit s Quantisierungsintervallen im Aussteuerbereich ![]() (beim Sinussignal) bzw.
(beim Sinussignal) bzw. ![]() (beim Videosignal, BA-Anteil)
(beim Videosignal, BA-Anteil)

Signal-zu-Quantisierungsgeräusch-Abstand ![]()

Gl. (4.8) und Gl. (4.9) gelten jeweils für volle Ausnutzung des gesamten Quantisierungsbereiches von ![]() [2, 7, 8].
[2, 7, 8].
4.2 Abtastraster im 4:4:4, 4:2:2 und 4:2:0 Format
Bei der Abtastung (engl, sampling) eines Tonsignals mit der periodischen Impulsfolge werden die aufeinander folgenden Abtastwerte einer zeitabhängigen Momentanspannung u(t) entnommen. Im Fall des Videosignals liegt zwar auch eine zeitabhängige Spannung vor, die aber über das zeilenweise Abtasten (engl. scanning) der Bildvorlage einen Bezug auf den geometrischen Ort des Abtastwertes aufweist. Üblicherweise erfolgt die Zuordnung auf Bildpunkte oder Pixel innerhalb des aktiven Zeilenrasters, womit wieder der Begriff „sampling“ zutreffend ist.
Von einer Farbbildvorlage werden entweder die Farbwertsignale R, G, B oder ein Leuchtdichtesignal Y und die Farbdifferenzsignale B-Y und R-Y abgeleitet. Wie noch erläutert wird, erfahren die Farbdifferenzsignale auch bei der Verarbeitung zum digitalen Videosignal eine Reduktion mit bestimmten Faktoren. Zur Kennzeichnung der so reduzierten Farbdifferenzsignale werden neue Bezeichnungen gewählt mit

Man bezeichnet diese Signale, die eigentlich erst im digitalen Bereich Vorkommen, als Chrominanzsignale ![]() und
und ![]()
Die Abtastwerte beziehen sich üblicherweise auf das aktive Bild mit einer Anzahl von ![]() Pixel pro aktive Zeile und
Pixel pro aktive Zeile und ![]() aktiven Zeilen im Bild. Dabei kann progressive Abtastung im Vollbild oder Zeilensprungabtastung mit zwei Halbbildern vorliegen. Das Video- Studiosignal basiert nach heutigem Standard auf der Zeilensprungabtastung, so dass diese auch bei den folgenden Erläuterungen zugrunde gelegt wird.
aktiven Zeilen im Bild. Dabei kann progressive Abtastung im Vollbild oder Zeilensprungabtastung mit zwei Halbbildern vorliegen. Das Video- Studiosignal basiert nach heutigem Standard auf der Zeilensprungabtastung, so dass diese auch bei den folgenden Erläuterungen zugrunde gelegt wird.
Die Begriffe „4:4:4“- und „4:2:2“-Abtastformat beziehen sich auf die Zuordnung der Chrominanz-Abtastwerte ![]() und
und ![]() zu den Luminanz-Abtastwerten Y. Dabei wird mit dem Verhältnis 4:4:4 bzw. 4:2:2 der Faktor der Abtastfrequenz für das Luminanzsignal und für die Chrominanzsignale zum Ausdruck gebracht, mit dem der Basiswert von 3,375 MHz multipliziert wird.
zu den Luminanz-Abtastwerten Y. Dabei wird mit dem Verhältnis 4:4:4 bzw. 4:2:2 der Faktor der Abtastfrequenz für das Luminanzsignal und für die Chrominanzsignale zum Ausdruck gebracht, mit dem der Basiswert von 3,375 MHz multipliziert wird.
Somit ergeben sich die Abtastfrequenzen von
4 • 3,375 MHz = 13,5 MHz und 2 • 3,375 MHz = 6,75 MHz.
Durch die starre Verkopplung mit der Zeilenfrequenz beim 625-Zeilen-System mit 3,375 MHz = 216,0 • 15,625 kHz bzw. beim 525-Zeilen-System mit 3,375 MHz = 214,5 • 15,734 kHz erhält man ein orthogonales Abtastraster, bei dem die Bildpunkte übereinander und in jedem Teilbild an der gleichen Stelle liegen.
In der folgenden Darstellung nach Bild 4.5 wird die Zuordnung der Abtastwerte vom Luminanzsignal Y (+) und vom Chrominanzsignal (O) mit ![]() und
und ![]() auf die Bildpunkte im Zeilenraster im ersten und zweiten Halbbild (HB) beim 4:4:4 Abtastraster (links) und beim 4:2:2-Abtastraster (rechts) gegenüber gestellt.
auf die Bildpunkte im Zeilenraster im ersten und zweiten Halbbild (HB) beim 4:4:4 Abtastraster (links) und beim 4:2:2-Abtastraster (rechts) gegenüber gestellt.
Auf die Bildpunkte bezogen erhält man eine Auflösung beim 4:4:4-Abtastraster im Y Signal, horizontal und vertikal: 100% horizontal: 100% im ![]() und
und ![]() Signal, vertikal: 100% und beim 4:2:2-Abtastraster im Y Signal, horizontal und vertikal: 100% horizontal: 50% im
Signal, vertikal: 100% und beim 4:2:2-Abtastraster im Y Signal, horizontal und vertikal: 100% horizontal: 50% im ![]() und
und ![]() Signal, vertikal: 100%.
Signal, vertikal: 100%.
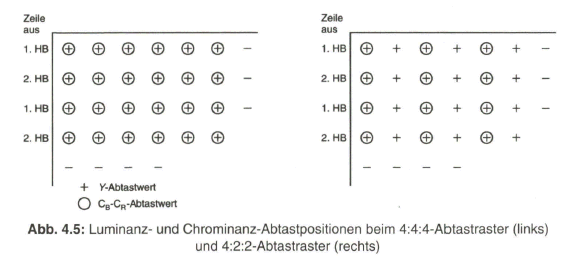
Das 4:4:4-Abtastraster hat in der Fernsehtechnik kaum eine Bedeutung. Eine Anwendung findet man bei Systemen ohne äußeren Übertragungskanal, z. B. bei der Bildverarbeitung in der Medizintechnik oder Radartechnik.
In der Fernsehtechnik wurde unter Bezugnahme auf das geringere Farbauflösungsvermögen des menschlichen Auges schon beim analogen Chrominanzsignal eine Reduzierung der Bandbreite gegenüber dem Luminanzsignal vorgenommen. Eine reduzierte Chrominanzauflösung kann daher auch beim digitalen Signal eingebracht werden. Beim 4:2:2-Abtastraster geschieht dies zunächst nur in horizontaler Richtung. Das digitale Studiosignal basiert auf diesem 4:2:2-Abtastraster. Eine Reduzierung der Vertikalauflösung beim Chrominanzsignal auf die Hälfte hätte zunächst zur Folge, dass das Chrominanzsignal nur aus Bildpunkten des ersten (oder des zweiten) Halbbildes gewonnen wird. Ein sichtbares Chrominanz- Zeilenflimmern wäre das Resultat. Um dies zu vermeiden, wird eine Interpolation vorgenommen. Aus den Abtastwerten von Bildpunkten geometrisch übereinander liegender Zeilen des ersten und zweiten Halbbildes wird jeweils ein Mittelwert berechnet, der dann repräsentativ den vier umgebenden Abtastwerten des Luminanzsignals zugeordnet wird.
Man bezeichnet diese Konstellation als 4:2:0-Abtastraster, wobei hier die Systematik mit den Vielfachen des Basiswerts der Abtastfrequenz nicht mehr gilt. Bild 4.6 gibt das 4:2:0-Abtastraster wieder.
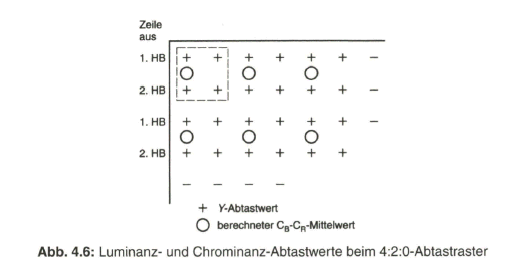
Im Gegensatz zu dem 4:2:2-Studiosignal gibt es keinen 4:2:0- Übertragungsstandard, weil dieser auf fiktive „Zwischenzeilen“ zurückgreifen würde. Wohl aber findet eine Signalverarbeitung zur Berechnung der Chrominanzwerte des 4:2:0-Abtastrasters statt bzw. umgekehrt zur Rekonstruktion der Chrominanzwerte im 4:2:2-Abtastraster aus den gemittelten Werten vom 4:2:0-Abtastraster. Man spricht hier von „Format-Konversion“. Daneben gibt es noch ein 4:1:1- Abtastraster, bei dem die horizontale Chrominanzauflösung auf 25 % reduziert wird. Es findet Anwendung z.B. bei der Magnetbandaufzeichnung von datenreduzierten Videosignalen. Eine weitere Reduktion der spatialen Auflösung auf die halbe Anzahl von Abtastwerten in Verbindung mit einer Reduktion der temporalen Auflösung (25 Hz bzw. 29,97 Hz Bildwechselfrequenz) führt zu dem SIF-Format (Source Intermediate Format) für einfache Multimedia-Anwendungen mit einer Auflösung ausgehend vom 625-Zeilensystem in 360 x 288 Pixel (V) bzw. 180 x 144 Pixel (![]() ,
,![]() ) bzw. vom 525-Zeilen-System in 360 x 240 Pixel (V) bzw. 180 x 120 Pixel (
) bzw. vom 525-Zeilen-System in 360 x 240 Pixel (V) bzw. 180 x 120 Pixel (![]() ,
, ![]() ).
).
4.3 Digitale Studionorm ITU-R BT.601
Im Jahre 1982 verabschiedete das CCIR (Comite Consultatif International des Radiocommunications), die Recommendation 601 als „einstimmige Empfehlung“ für Encoding Parameters of Digital Television for Studios.
Das CCIR, als ein Ausschuss der Internationalen Fernmeldeunion, ist im Dezember 1992 durch die Neuorganisation der UIT (franz.: Union Internationale des Telecommunications) bzw. ITU (engl.: International Telecommunication Union) übergegangen in den Radiocommunication Sector (RS) der UIT bzw. ITU.
Mehrmalige Aktualisierungen im Abstand von vier bzw. zwei Jahren führten zu der Version Rec. ITU-R BT.601-4, die im Jahr 1995 noch ergänzt wurde als Rec. ITU- R BT.601-5, mit der Bezeichnung Studio Encoding Parameters of Digital Television for Standard 4:3 and Wide Screen 16:9 Aspect Ratio.
Nachdem die letzte Version mit erhöhter Abtastfrequenz für das 16:9-Breitbildformat beim digitalen Fernsehen keine wesentliche Bedeutung mehr hat, wird im Folgenden auf die Rec. ITU-R BT.601-4, Encoding Parameters of Digital Television for Studios in Bezug genommen.
Zugrunde liegt dieser Empfehlung eine weitgehende Gemeinsamkeit der Parameter für die 525-Zeilen/60-Hz- bzw. 625-Zeilen/50-Hz-Fernsehsysteme. Außerdem werden darin die Parameter sowohl für den 4:2:2-Abtaststandard mit den Komponentensignalen Y, B-Y und R-Y als auch für den 4:4:4-Abtaststandard angegeben, wobei letzterer neben den Komponentensignalen auch die Farbwertsignale R, G, B zulässt.
Codiert werden die gammakorrigierten Quellensignale ![]() bzw.
bzw.![]() ,
,![]() ,
, ![]() mit der englischsprachigen Schreibweise „E‘ für die Spannung U. Der Spannungsbereich liegt normiert zwischen 0 und 1,0 für das
mit der englischsprachigen Schreibweise „E‘ für die Spannung U. Der Spannungsbereich liegt normiert zwischen 0 und 1,0 für das ![]() - Signal, vom praktischen Spannungswert her zwischen 0 und 700 mV. Damit auch die Farbdifferenzsignale bei der Normfarbbalkenvorlage auf diesen normierten Bereich zwischen -0,5 bis +0,5 bzw. von -350 mV bis +350 mV begrenzt werden, erfolgt eine Reduzierung der Farbdifferenzsignale gemäß der Matrixgleichungen mit vereinfachter Schreibweise zu den Chrominanzsignalen
- Signal, vom praktischen Spannungswert her zwischen 0 und 700 mV. Damit auch die Farbdifferenzsignale bei der Normfarbbalkenvorlage auf diesen normierten Bereich zwischen -0,5 bis +0,5 bzw. von -350 mV bis +350 mV begrenzt werden, erfolgt eine Reduzierung der Farbdifferenzsignale gemäß der Matrixgleichungen mit vereinfachter Schreibweise zu den Chrominanzsignalen
![]()
![]()
Die Wesentlichen Parameter für die Digitale Studionorm mit dem 4:2:2-Abtaststandard werden im Folgenden aufgeführt, wobei eine Unterscheidung zwischen 525-Zeilen- und 625-Zeilen-System nur in einem Parameter, der Anzahl der Abtastwerte über die gesamte Zeilendauer, vorliegt.
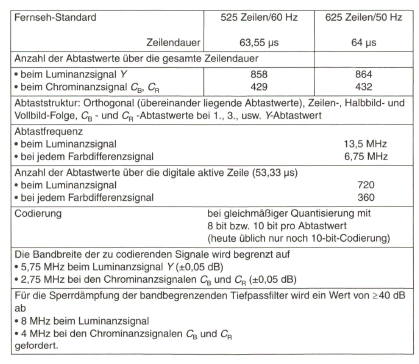
Außerdem müssen die im Standard vorgegebenen Grenzen für die Gruppenlaufzeit-Schwankung im Durchlassbereich der bandbegrenzenden Tiefpassfilter eingehalten werden.
Zuordnung der Quantisierungsintervall-Nummern mit 8-bit-/10-bit-Codierung auf die normierten Spannungswerte 0 ... 1,0 bzw. -0,5 ... 0 ... +0,5 beim Luminanzsignal Y bei den Chrominanzsignalen ![]()
![]()
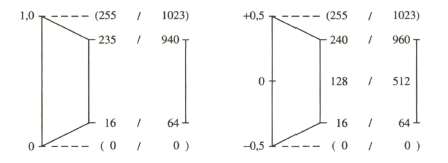
Die Extremwerte 0 und 255 (bei 8-bit-Codierung) bzw. 0 und 1023 (bei10-bit-Codierung) sind für Codeworte beim digitalen Synchronsignal reserviert. Über den regulären Aussteuerbereich hinaus ist nach oben und unten ein Bereich für Überschwinger beim Analogsignal vorgesehen.
4.4 Studio-Multiplexsignal nach ITU-R BT.656
4.4.1 Zeitmultiplex von digitalen Leuchtdichte- und Farbdifferenzsignalen
Aus den analog-digital-gewandelten Komponentensignalen Y, ![]() und
und ![]() wird gemäß den Festlegungen in ITU-R Recommendation 656 Interfaces for Digital Component Video Signals in 525-Line and 625-Line Television Systems unter Hinzufügen einer digitalen Synchronisierinformation ein digitales Zeitmultiplexsignal gebildet, das nun, letztendlich als serielles Multiplexsignal, an die Stelle des FBAS-Signals beim analogen Videosignal tritt. Die Aufbereitung des Zeitmultiplexsignals zeigt Bild 4.7.
wird gemäß den Festlegungen in ITU-R Recommendation 656 Interfaces for Digital Component Video Signals in 525-Line and 625-Line Television Systems unter Hinzufügen einer digitalen Synchronisierinformation ein digitales Zeitmultiplexsignal gebildet, das nun, letztendlich als serielles Multiplexsignal, an die Stelle des FBAS-Signals beim analogen Videosignal tritt. Die Aufbereitung des Zeitmultiplexsignals zeigt Bild 4.7.
Die analog-digital-gewandelten Komponentensignale werden auf V-bit-Ebene parallel vom A-D-Wandler übernommen und über Zwischenspeicher einem N-bit- Multiplexer zugeführt. Gemäß dem 4:2:2-Abtaststandard beim digitalen Studiosignal werden zwei Y-Codeworte mit jeweils einem ![]() - und einem
- und einem ![]() - Codewort zusammengefasst mit der vorgegebenen Folge von
- Codewort zusammengefasst mit der vorgegebenen Folge von ![]() Dazu ist es erforderlich, vier N-bit-Codeworte in ein Zeitintervall von zwei mal der Abtastperiodendauer
Dazu ist es erforderlich, vier N-bit-Codeworte in ein Zeitintervall von zwei mal der Abtastperiodendauer ![]() des Y-Signals, mit
des Y-Signals, mit ![]() , einzuordnen. Der Multiplexer-Takt von
, einzuordnen. Der Multiplexer-Takt von ![]() = 27 MHz liefert dazu die 37,037-ns-Zeitschlitze. Siehe dazu Bild 4.8.
= 27 MHz liefert dazu die 37,037-ns-Zeitschlitze. Siehe dazu Bild 4.8.
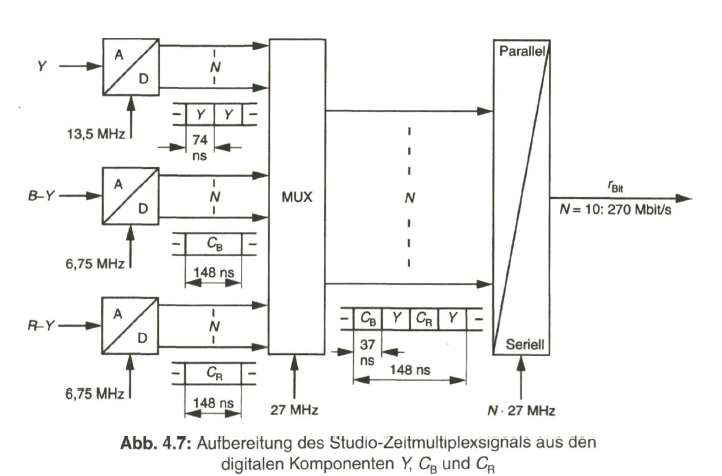
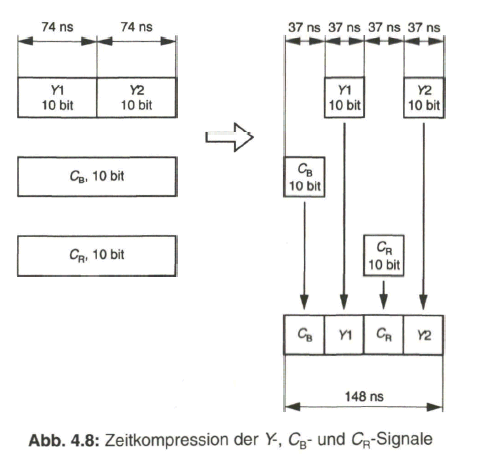
Das Multiplexen der digitalen Komponentensignale erfolgt über die Zeitdauer der aktiven Zeile mit 53,33... ![]() . Diese ergibt sich genau über die Dauer von 1440 Taktperioden des Multiplexer-Takts, zugeordnet den 1440 Abtastwerten aus dem Y-, dem CB- und CR-Signal mit 720 Abtastwerten vom Y-Signal, 360 Abtastwerten vom
. Diese ergibt sich genau über die Dauer von 1440 Taktperioden des Multiplexer-Takts, zugeordnet den 1440 Abtastwerten aus dem Y-, dem CB- und CR-Signal mit 720 Abtastwerten vom Y-Signal, 360 Abtastwerten vom ![]() Signal und 360 Abtastwerten vom
Signal und 360 Abtastwerten vom ![]() (Bild 4.9).
(Bild 4.9).
Die Dauer der aktiven digitalen Zeile berechnet sich so zu 1440 • 1/27 MHz = 1440 • 37,037... ns = 53,33... ![]() .
.
Innerhalb der gesamten Zeilendauer verbleibt dann noch die horizontale Austastlücke (HA) mit 288 Taktperioden (10,66 ![]() ) beim 625-Zeilen-System bzw. 276 Taktperioden (10,22
) beim 625-Zeilen-System bzw. 276 Taktperioden (10,22 ![]() ) beim 525-Zeilen-System. Während der Zeilen in der Vertikalaustastlücke wird zunächst der Schwarzwert (Austastwert) eingebracht. Zur Markierung des Beginns des aktiven Videosignals werden die letzten vier Codeworte im Horizontal-Austastsignal durch ein Zeitreferenzsignal „Start of Active Video (SAV)“ ersetzt und das Ende des aktiven Videosignals mit dem Zeitreferenzsignal „End of Active Video (EAV)“ durch die ersten vier Codeworte im Horizontal-Austastsignal signalisiert. Der Zeitbezug zwischen dem analogen Videosignal und dem digitalen Videosignal ist durch den Abstand zwischen der Vorderflanke (Mitte) des Horizontal-Synchronimpulses und dem Beginn der digitalen Horizontalaustastung festgelegt mit 24 Taktperioden beim 625-Zeilen-System bzw. 32 Taktperioden beim 525-Zeilen-System (Bild 4.10). Diese Zuordnung zwischen den analogen Videosignal-Komponenten und dem digitalen Videosignal ist bereits in ITU-R BT.601 definiert.
) beim 525-Zeilen-System. Während der Zeilen in der Vertikalaustastlücke wird zunächst der Schwarzwert (Austastwert) eingebracht. Zur Markierung des Beginns des aktiven Videosignals werden die letzten vier Codeworte im Horizontal-Austastsignal durch ein Zeitreferenzsignal „Start of Active Video (SAV)“ ersetzt und das Ende des aktiven Videosignals mit dem Zeitreferenzsignal „End of Active Video (EAV)“ durch die ersten vier Codeworte im Horizontal-Austastsignal signalisiert. Der Zeitbezug zwischen dem analogen Videosignal und dem digitalen Videosignal ist durch den Abstand zwischen der Vorderflanke (Mitte) des Horizontal-Synchronimpulses und dem Beginn der digitalen Horizontalaustastung festgelegt mit 24 Taktperioden beim 625-Zeilen-System bzw. 32 Taktperioden beim 525-Zeilen-System (Bild 4.10). Diese Zuordnung zwischen den analogen Videosignal-Komponenten und dem digitalen Videosignal ist bereits in ITU-R BT.601 definiert.
Die digitale, horizontale Austastung läuft auch während der Zeilen in der vertikalen Austastlücke durch. Der digital aktive Videoanteil und die Zeitreferenzsignale SAV und EAV werden zum „video data block“ zusammengefasst. Nähere Erläuterungen zu den Zeitreferenzsignalen siehe 4.4.2.
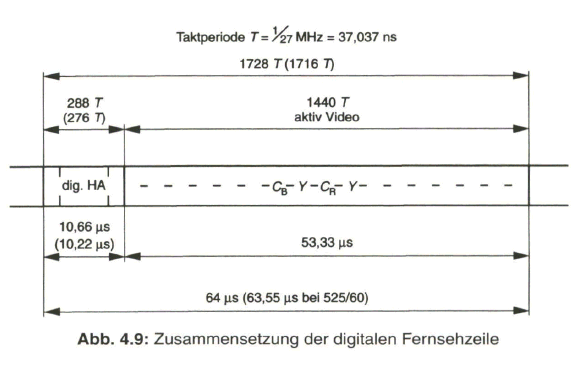
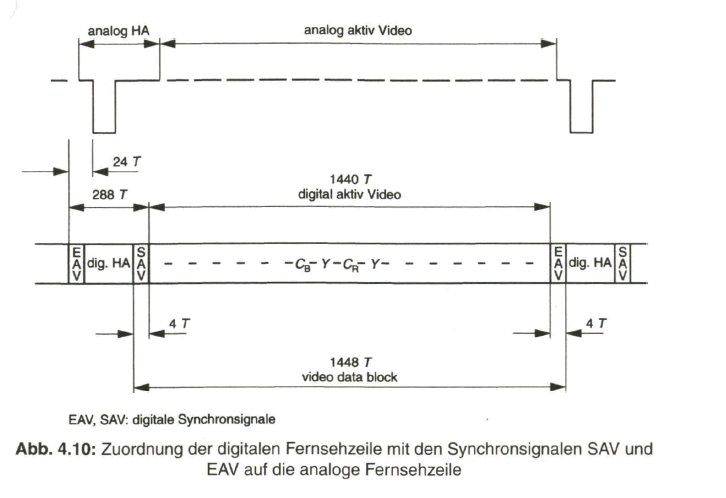
Die digitalen Komponentensignale werden zur weiteren Verarbeitung über die parallele Schnittstelle auf (n) Leitungen, meist als symmetrische Leiterpaare, mit einem zusätzlichen Leiterpaar für den 27-MHz-Takt im ECL-Signalniveau, übertragen. Bei der heute üblichen 10-bit-Codierung sind somit 11 Leiterpaare notwendig. Mit einem so genannten Multicore-Kabel ist eine Distanz bis zu 100 Meter zu überbrücken.
Zur Signalverteilung im Studio über größere Entfernungen und zur Übertragung des digitalen Multiplexsignals über das Studio hinaus, wird über eine Parallel-Seriell-Wandlung das DSC-Signal (Digital Serial Components) gewonnen. Die Taktung erfolgt jetzt mit der Bitfolgefrequenz ![]() , die sich ergibt zu
, die sich ergibt zu

Die Forderungen, dass das Digitalsignal gleichspannungsfrei ist (Gleichspannungsmittelwert gleich Null) und dass aus dem seriellen Signal am Empfangsort der Bit-Takt abgeleitet werden kann, werden durch eine NRZI-Codierung (Non Return to Zero Inverse) und durch Scrambling (Verwürfeln) mit einer Pseudozufallsfolge erreicht. Bei der NRZI-Codierung wird eine logische „0“ als ein Gleichspannungswert (z. B. +400 mV oder -400 mV) und eine logische „1“ als ein Gleichspannungssprung (von +400 mV nach -400 mV oder umgekehrt) codiert.
4.4.2 Digitale Synchronisierinformation
Zur Gewährleistung einer exakten Synchronisation sind nach ITU-R BT.656 Zeitreferenzsignale definiert. Es sind dies die Video timing reference codes SAV und EAV. Wie schon in Bild 4.10 gezeigt steht das Codewort SAV, Start of Active Video, zu Beginn eines jeden Video-Datenblocks und das Codewort EAV, End of Active Video, am Ende eines jeden Video-Datenblocks.
Jedes Zeitreferenzsignal besteht aus vier Codewörtern, wie in Bild 4.11 für 10-bit-Codierung dargestellt. Die Codeworte 1111111111 und 0000000000 wurden bei der A-D-Wandlung des Videosignals als nicht zulässig ausgeklammert und für die Zeitreferenzsignale reserviert. Sie kommen so im aktiven Videosignal nicht vor.

Die Sequenz der ersten drei Codeworte dient zur Synchronisierung des „Empfängers“ auf das zu erwartende eigentliche Synchronisationssignal im vierten Codewort des Zeitreferenzsignals. Dieses beginnt mit einem „1 “-Bit (MSB) und setzt sich dann zusammen aus den charakterisierenden Bits
F: „0“ während dem 1. Halbbild, „1 “ während dem 2. Halbbild
V: „0“ außerhalb und „1 “ während der Vertikal-Austastung
H : „0“ in SAV und „1“ in EAV
sowie einer Folge von vier Schutz-Bits (protection bits) P3, P2, P1, P0
und beim 10-bit-Codewort noch zwei Bits mit log. „0“.
Die Schutzbits dienen zum Erkennen und gegebenenfalls Korrigieren von Übertragungsfehlern. Die Kombination der Schutzbits mit den eigentlichen Informationsbits zeigt Tabelle 4.1.
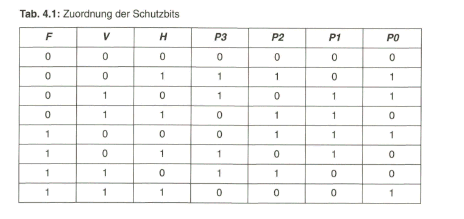
Aus der Berechnung der Quersumme in den Zeilen und Spalten können auf der Empfängerseite 1-bit-Fehler korrigiert und 2-bit-Fehler in dem Synchronisations-Codewort erkannt werden. In letzterem Fall erfolgt die Synchronisation dann mit dem nächsten korrekt empfangenen Synchronisations-Codewort.
4.4.3 Digitale Begleittonsignale
ln der Recommendation ITU-R BT.656 sind Vorkehrungen getroffen zur Übertragung von Zusatzdaten (ancillary data) während der Austastintervalle mit einer Baudrate von 27 MWorte/s. Die Zusatzdaten können während der Horizontalaustastung mit 10-bit-Codeworten übertragen werden und mit 8-bit-Codeworten während der Zeitintervalle des aktiven Videoanteils innerhalb der Vertikalaustastung.
Nach einem SMPTE-Standard (Society of Motion Picture and Television Engineers), der von AES (Audio Engineering Society) und EBU (European Broadcasting Union) übernommen wurde, können digitale Audiosignale innerhalb der für die Zusatzdaten vorgesehenen Zeitintervalle eingefügt werden.
Dies gilt insbesondere für eine Kombination von vier Audiokanälen innerhalb eines Teils der Horizontalaustastung. Bild 4.12 gibt dies vereinfacht wieder. Nach dem EAV-Synchronisationswort folgt ein Data Header (DH) mit Angaben über die folgenden Audiodaten. Die digitalen Audiosignale werden nach dem AES/EBU-Standard in 32-bit-subframes zusammengefasst. Ein 32-bit-subframe wird gebildet aus einem 4-bit-Synchronwort, einer 4-bit-Kennung zur Identifizierung von Audio- oder Hilfsdaten, gefolgt von einem 20-bit-Codewort des Audiosignals und einer 4-bit-Zusatzinformation.
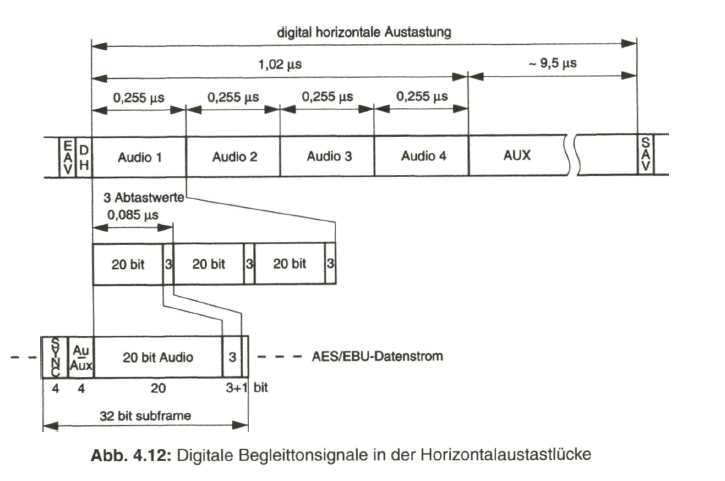
Das analoge Audiosignal wird mit ![]() = 48 kHz abgetastet. Jeder Abtastwert wird mit 20 bit codiert und ergänzt zu einem 32-bit-Codewort. Die Datenrate für einen Audiokanal beträgt somit
= 48 kHz abgetastet. Jeder Abtastwert wird mit 20 bit codiert und ergänzt zu einem 32-bit-Codewort. Die Datenrate für einen Audiokanal beträgt somit

Von einem Audiokanal werden aus dem AES/EBU-Datenstrom pro Zeile drei Abtastwerte übertragen. Mit einer Abtastperiodendauer von ![]() ergibt das eine Zeitdauer von 3 • 20,833
ergibt das eine Zeitdauer von 3 • 20,833 ![]() = 62,5
= 62,5 ![]() und ist damit noch kleiner als Th = 64
und ist damit noch kleiner als Th = 64 ![]() . Übernommen werden die 20 bit Audiodaten und 3 bit aus der Zusatzinformation. Neben den vier Audiokanälen, z. B. Links- und Rechts-Kanal, Kommentar-Ton, Begleitmusik, können noch weitere Tonsignale in den Auxiliary Data (AUX) in entsprechenden Datenpaketen übertragen werden.
. Übernommen werden die 20 bit Audiodaten und 3 bit aus der Zusatzinformation. Neben den vier Audiokanälen, z. B. Links- und Rechts-Kanal, Kommentar-Ton, Begleitmusik, können noch weitere Tonsignale in den Auxiliary Data (AUX) in entsprechenden Datenpaketen übertragen werden.
Von der Brutto-Datenrate mit 270 Mbit/s werden vom aktiven Videosignal etwa 207 Mbit/s (207,36 Mbit/s) beansprucht. Die verbleibenden etwa 63 Mbit/s können neben einem sehr geringen Anteil für die Synchronisierinformation von den vier Audiokanälen mit etwa 6.2 Mbit/s und von Zusatzdaten (auxiliary data) in der Horizontalaustastung (etwa 38 Mbit/s) und im größten Teil der Vertikalaustastung (etwa 15 Mbit/s) belegt werden (Bild 4.13).
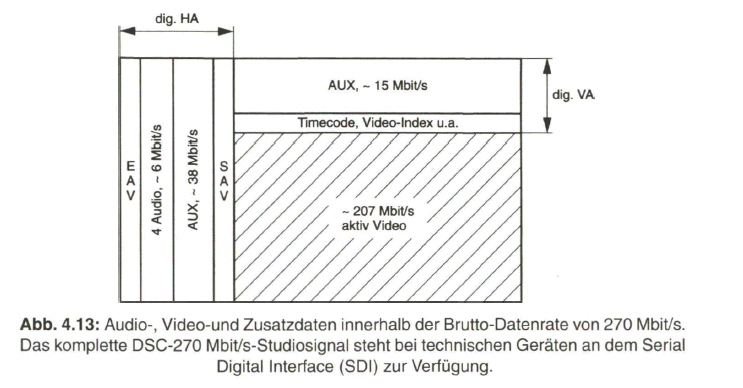
4.4.4 Aktiver Teil des Digitalen Studiosignals
Die Bitrate des seriellen, digitalen Studiosignals beträgt 270 Mbit/s. Wie aufgeführt, werden davon aber nur etwa 207 Mbit/s vom eigentlichen Videosignal beansprucht. Für die weitere Verarbeitung des digitalen Videosignals auf dem Weg zum Fernsehteilnehmer mit den noch ausführlich erläuterten Datenreduktionsverfahren ist nur der aktive Anteil des Studiosignals zu berücksichtigen. Im Folgenden werden, ausgehend vom DSC-270Mbit/s-Signal, die weiteren relevanten Werte für die Bitrate des aktiven Anteils im Videosignal berechnet.
Brutto-Bitrate des Digitalen Video-Studiosignals DSC 270 bei 4:2:2-Abtastformat und 10-bit-Codierung (Abt.: Abtastwerte)

Aktiver Anteil des digitalen Studiosignals
• bei 4:2:2-Abtastformat und 8-bit-Codierung

Ein weiterer Schritt, der bereits im Sinne einer Irrelevanzreduktion einzuordnen wäre, ist der Übergang auf das 4:2:0-Abtastraster mit reduzierter Chrominanzauflösung. Aktiver Teil des digitalen Studiosignals
• bei 4:2:0-Abtastformat und 8-bit-Codierung

Bei der Übertragung eines digitalen, datenreduzierten SDTV-Signals zum Fernsehteilnehmer wird im Allgemeinen von dem 4:2:0-Abtastraster ausgegangen.
4.5 Vergleich verschiedener Abtastraster
4.5.1 SDTV-Abtastraster nach Europa- und US-Standard
Der digitale Studio-Standard nach ITU-R BT.601 definiert für das 525-Zeilen- und das 625-Zeilen-System eine Anzahl von 720 Abtastwerten pro aktive Zeile für das Leuchtdichtesignal Y.
Die Anzahl der aktiven Zeilen im Bild unterscheidet sich aber mit
• 480 aktiven Zeilen beim digitalen 525-Zeilen-Signal und
• 576 aktiven Zeilen beim digitalen 625-Zeilen-Signal.
Das Seitenverhältnis des sichtbaren Bildes beträgt beim Standard-Fernsehen (SDTV) originär 4:3 (B:H). Für den einzelnen Bildpunkt im Raster erhält man ein Seitenverhältnis ![]() beim
beim
• 625-Zeilen-System: ![]() = 4:3/720:576 : 1 - 1,06 : 1
= 4:3/720:576 : 1 - 1,06 : 1
• 525-Zeilen-System: ![]() = 4:3/720:480 : 1 = 0,88 : 1.
= 4:3/720:480 : 1 = 0,88 : 1.
Durch die immer engere Verknüpfung von „Fernsehen“ mit „Multimedia“, sprich Computer-System, kam die Forderung nach einem quadratischen Bildpunktformat beim Fernsehen auf, wie es beim Computer üblich ist. Deshalb hat das ATSC (Advanced Television Systems Committee), ein Fachausschuss in den USA, der sich eigentlich mit der Entwicklung verschiedener HDTV-Standards befasst, für das 525-Zeilen-System in den USA ein mögliches Abtastformat von
• 640 Bildpunkten pro aktive Zeile und 480 aktiven Zeilen definiert, mit dem sich bei dem Bild-Seitenverhältnis von B:H = 4:3 quadratische Bildpunkte mit ![]() = 1:1 ergeben.
= 1:1 ergeben.
Darüber hinaus lässt ATSC auch noch ein Abtastformat mit
• 704 Bildpunkten pro aktive Zeile und 480 aktive Zeilen zu.
Dieses Abtastformat ist mit progressiver Abtastung und 60 Hz (genau 59,94 Hz) Bildwechselfrequenz verbunden [14]. Eine Erweiterung des Standardformats auf das Breitbildformat mit B:H = 16:9 (5,33:3) bei gleicher Anzahl von Bildpunkten pro Aktive Zeile und damit gleicher absoluter Horizontalauflösung bringt aber eine Reduzierung der relativen Horizontalauflösung. Um dem zu begegnen, müsste die Anzahl der Abtastwerte für das Leuchtdichtesignal Y pro aktive Zeile auf 720 • (16:9)/4:3 = 720 ■ 1,33 = 960 über eine um den Faktor 1,33 höhere Abtastfrequenz erhöht werden.
In einer Version ITU-R BT.601-5 war dies mit 18 MHz beim Y-Signal und 9 MHz bei den Chrominanzsignalen vorgesehen, mit einer Brutto-Bitrate von 360 Mbit/s. Dieser Standard hat aber keine weitere Bedeutung mehr erlangt.
4.5.2 HDTV-Abtastraster mit Breitbildformat
Die Festlegung eines im Vergleich zum digitalen SDTV-Studio-Standard eindeutigen und weltweiten HDTV-Studio-Standards ist bisher nicht geschehen. Es gibt jedoch einige De-facto-Standards, mit denen produziert und in nächster Zeit auch in Europa übertragen wird. Die Interessen der Produzenten und Programmanbieter sind unterschiedlich, was die Qualität und die Wirtschaftlichkeit anbelangt. Entscheidend beeinflusst wird die Situation durch das immer größere Angebot an Flachbild-Displays mit hoher Pixel-Auflösung. Die derzeit in Europa noch begrenzten Möglichkeiten des Empfangs und der Verarbeitung von HDTV-Signalen wurden ab 2006 durch ein breites Angebot von Programmen und den notwendigen Empfangsgeräten einen Aufschwung erfahren. Es laufen bereits Testausstrahlungen über digitale Satellitenkanäle. Ein regulärer HDTV-Service war von einigen Rundfunkanstalten für Ende 2005 angekündigt.
In den USA, Japan und Australien kann schon von einem HDTV-Regelbetrieb, zumindest während der Hauptsendezeiten, ausgegangen werden.
Für den internationalen Programmaustausch, insbesondere mit USA und Japan, wird vielfach HDTV als Standard gefordert. Insbesondere bei großen Sportveranstaltungen wie den Olympischen Spielen oder der Fußball-Weltmeisterschaft 2006 wurden HDTV-Kameras eingesetzt, um höheren Qualitätsansprüchen und der Breitbildwahrnehmung nachzukommen. Für die Standard-TV-Versorgung wurde durch Abwärts-Konvertierung ein SDTV-Signal gewonnen.
Vom Abtastraster her war in Europa zunächst eine Anbindung an den SDTV-Standard mit Verdoppelung der Zeilenzahl und Anzahl der Bildpunkte pro Zeile vorgesehen, was bei einem „1250-Zeilen-HDTV-System“ zu 1152 aktiven Zeilen und 1440 Abtastwerten pro aktive Zeile geführt hat. Dieses System ist jedoch nicht zum Tragen gekommen. Hochauflösendes Fernsehen HDTV soll „kinoähnliche“ Bildwahrnehmung bringen. Dazu gehört aber auch das Breitbildformat. Beim Fernsehen wurde ein Breitbildformat mit einem Bild-Seitenverhältnis von B:H = 16:9 festgelegt. Wie schon in 4.5.1 erwähnt, erfordert die Beibehaltung der gegenüber dem Standardformat gleichen relativen Horizontalauflösung eine Erhöhung der Anzahl der Bildpunkte pro aktive Zeile um den Faktor 16:9/4:3 = 4/3, was nun mit 720 x 2 x 4/3 zu 1920 Abtastwerten pro aktive Zeile beim Y-Signal führt. Das Raster basiert selbstverständlich auf quadratischen Bildpunkten. Das Abtastformat für die Chrominanzsignale wird beim Studiosignal 4:2:2 sein, für Kino-Produktionen ist auch 4:4:4 vorgesehen. Die Codierung erfolgt mit 10 bit/ Abtastwert.
Ausgehend von der Definition eines digitalen HDTV-Systems durch die SMPTE (Society of Motion Picture and Television Engineers) in SMPTE 260 M mit 1125 Zeilen und 60 Halbbildern pro Sekunde bei 1035 aktiven Zeilen ergaben sich rechteckförmige Bildpunkte. Durch eine Änderung in SMPTE 274 M auf 1080 aktive Zeilen kam man der Forderung nach quadratischen Bildpunkten bei dem Breitbildseitenverhältnis von 16:9 wieder nach. Das europäische Pendant zu SMPTE 274 M für das 1250 Zeilen-System mit 50 Halbbildern pro Sekunde wird in SMPTE 295 M beschrieben.
Gemäß einer internationalen Übereinkunft wurde ein HDTV-Produktions-Standard als „Common Image Format“ 1920 x 1080 geschaffen mit 1920 Abtastwerten pro aktive Zeile und 1080 aktiven Zeilen. Die Abtastfrequenz für das Y-Signal ist definiert mit Vielfachen von 2,25 MHz. Das ergibt den Wert von 33 • 2,25 MHz = 74,25 MHz bei Zeilensprung-Abtastung. Es ist sowohl Zwischenzeilen-Abtastung, interlaced scan (2:1), als auch progressive Abtastung (1:1), progressive scan, vorgesehen. Tabelle 4.2 gibt die charakteristischen Werte des 1920x1080-HD-Produktionsformats wieder.
Für das 50Hz-System (interlaced scan) ergibt sich mit 1250 Zeilen pro Bild eine Zeilenperiodendauer von 32 ![]() und mit der Abtastfrequenz von 74,25 MHz eine Abtastperiodendauer von 13,46 ns. Das bedeutet eine Anzahl von 2376 Abtastwerten über die gesamte Zeile für das Luminanzsignal. Damit berechnet sich eine Brutto-Datenrate für das 1080i/25-HD-Studiosignal, mit 4:2:2-Abtastraster, zu
und mit der Abtastfrequenz von 74,25 MHz eine Abtastperiodendauer von 13,46 ns. Das bedeutet eine Anzahl von 2376 Abtastwerten über die gesamte Zeile für das Luminanzsignal. Damit berechnet sich eine Brutto-Datenrate für das 1080i/25-HD-Studiosignal, mit 4:2:2-Abtastraster, zu

Tab. 4.2: Charakteristische Werte des 1920x1080-HD-Produktionsformats
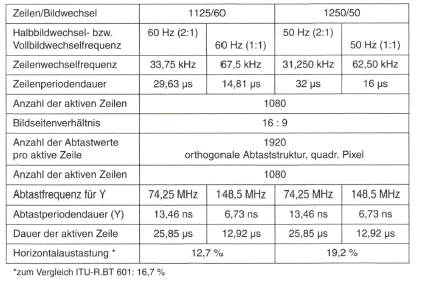
Die Schreibweise für die unterschiedlichen neuen Fernsehformate wurde kürzlich vom Production Technology Committee der European Broadcasting Union (EBU) in folgender Weise festgelegt: Es erfolgt erst die Nennung der vertikalen Auflösung (aktive Zeilen), gefolgt vom Abtastformat (Interlaced oder Progressiv) und der Bildwechselrate (frame Rate). Es wird keine Halbbild-Rate mehr angegeben.
Interessant für eine spätere Datenreduktion wird der tatsächlich in der Brutto- Bitrate von 1485 Mbit/s enthaltene aktive Anteil des Videosignals. Ähnlich wie beim SDTV-Signal (siehe S. 74) berechnet sich nun die Netto-Datenrate für das 1080i/25-HD-Studiosignal zu

Falls für die Übertragung zum Fernsehteilnehmer eine Reduzierung der Codewortlänge von 10 bit auf 8 bit vorgenommen wird, dann reduziert sich der aktive Anteil des digitalen FIDTV-Signals auf 829,44 Mbit/s. Dies entspricht dem fünffachen Wert von 165,88 Mbit/s beim SDTV-Signal.
Das Zeilensprungverfahren wurde in den Anfängen des Fernsehens festgelegt. Die Gründe dafür waren die gegenüber Vollbild-Übertragung nur halbe notwendige Übertragungsbandbreite und die nur aufwendig zu realisierende Strahlablenkung mit der höheren Zeilenfrequenz. Das mit dem Zeilensprungverfahren verbundene Zwischenzeilenflimmern wird vom menschlichen Auge bei genügend Betrachtungsabstand zum Bildschirm nur unwesentlich wahrgenommen. Nachteilig jedoch wirkt sich die halbierte vertikale Auflösung aus, die insbesondere bei Bewegungen im Bild zu störenden Artefakten führt.
Bei progressiver Abtastung und Vollbild-Übertragung werden vertikale Bewegungen in voller vertikaler Auflösung wiedergegeben. Dem Nachteil der höheren Übertragungsbandbreite beziehungsweise der doppelten Datenrate steht ein im Allgemeinen besserer Wirkungsgrad bei der Datenreduktion gegenüber. Dazu kommt, dass unter dem Aspekt der Bildwiedergabe mit Flachbild-Displays ein bei Übertragung mit dem Zeilensprungverfahren notwendiges De-Interlacing beim Empfänger entfällt, nachdem Flachbildschirme jeden Bildpunkt einzeln adressieren und damit als „progressive Displays“ betrachtet werden können.
Das EBU Technical Committee hat deswegen eine Empfehlung herausgegeben, nach der für HDTV die progressive Abtastung zur Anwendung kommen soll [84], Derzeit wäre die optimale Lösung mit dem in USA von ATSC vorgegebenen Standard mit 720 aktiven Zeilen und für Europa mit 50 Vollbildern pro Sekunde. Anzustreben wäre aber auf längere Sicht ein 1080p/50-Standard, damit ist aber auch eine Verdopplung der Brutto-Datenrate auf 2970 Mbit/s bzw. der Netto-Daten rate auf 2073,6 Mbit/s verbunden.
Von den Endgeräten beim Fernsehteilnehmer, Set-Top-Boxen, Displays oder im Fernsehempfänger integrierte Einrichtungen, wird derzeit verlangt, dass sie sowohl das 720p/50- als auch das 1080i/25-Format akzeptieren. Damit bleibt es den Programmanbietern frei gestellt, welches der beiden Formate für die Verteilung gewählt wird, wobei gegebenenfalls sogar von Programm zu Programm gewechselt werden kann [84, 86]. Eine wesentliche Vorgabe bei den HDTV-Abtastrastern ist das quadratische Bildpunktformat. Diese Forderung entspringt eigentlich der Bilddarstellung bei den Computern, wurde aber sinnvoller Weise durch den vermehrten Einsatz von Flachbildschirmen bei Fernsehgeräten übernommen. Bei dem 1080i/25-HD-Studiosignal ergeben sich mit 16:9-Breitbilddarstellung gemäß dem Verhältnis von Anzahl der Bildpunkte pro aktive Zeile zu Anzahl der aktiven Zeilen von 1920 : 1080 = 1,77, identisch mit 16 : 9 = 1,77, quadratische Bildpunkte.
Dies trifft auch zu für das mit progressiver Abtastung verbundene 720p/50-HD-Studiosignal. Den 720 aktiven Zeilen zugeordnet sind 1280 Bildpunkte pro aktive Zeile. Das Gesamtraster weist 750 Zeilen auf, mit jeweils 1980 Abtastwerten pro Zeile für das Luminanzsignal. Es berechnet sich damit eine Brutto-Datenrate für das 720p/50-HD-Studiosignal, mit 4:2:2-Abtastraster, zu

Den aktiven Teil des Videosignals erhält man über die Netto-Datenrate für das 720p/50-HD-Studiosignal zu

Bei der HDTV-Produktion haben sich nach der EBU-Empfehlung Tech. 3299 vier Basisbandformate etabliert, die auch nach SMPTE (296 M und 274 M) definiert sind:
720p/50, mit 1280 Bildpunkten pro aktive Zeile, progressive Abtastung,
1080i/25, mit 1920 Bildpunkten pro aktive Zeile, Zeilensprung-Abtastung,
1080p/25, mit 1920 Bildpunkten pro aktive Zeile, progressive Abtastung,
1080p/50, mit 1920 Bildpunkten pro aktive Zeile, progressive Abtastung.
Der Standard 720p/50 ist bisher nach ITU-R BT.1543 nur in der 60Hz-Version definiert, wohl aber in SMPTE 296 M enthalten. Die ITU-R-Festlegung soll jedoch geändert werden, weil eine EBU-Empfehlung die Industrie auffordert, den Standard 720p/50 in ihre Produkte mit aufzunehmen [86]. Durch die Ankündigung von zunehmendem Programmangebot in HDTV und durch die breite Palette von Fernsehgeräten mit Flachbildschirmen im 16:9-Breitbildformat stellt sich die Frage nach der Wiedergabemöglichkeit von HDTV-Programmsignalen.
Zur Kennzeichnung von Geräten, die hochauflösendes Fernsehen (HDTV) wiedergeben können, ist von der European Information, Communications and Consumer Electronics Industry Technology Association (EICTA) Anfang 2005 ein „Gütesiegel“ geschaffen worden, das HD ready-Logo. Ein Hersteller darf ein Anzeigegerät mit dem „HD ready“-Logo versehen, wenn
• der Bildschirm des Fernsehers oder das Bild erzeugende Element des Projektors auf Grund der real vorliegenden Pixel-Anzahl mindestens 720 Zeilen im Breitbildformat 16:9 wiedergeben kann
• das Gerät über mindestens einen analogen YUV-Komponenteneingang verfügt
• das Gerät digitale Schnittstellen nach den Standards DVI (Digital Video Interface) oder HDMI (High Definition Multimedia Interface) aufweist, die außerdem den digitalen Kopierschutz-Standard HDCP (High Bandwidth Digital Content Protection) unterstützen.
• HD-Videoformate über beide Eingänge mit 50 oder 60 Bildwechsel pro Sekunde (beim digitalen Eingang unverschlüsselt und verschlüsselt) als Vollbilder mit 1280 x 720 Pixeln (720p) oder als Halbbilder im Zeilensprungverfahren mit 1920 x 1080 Pixeln (1080i) annehmen können.
Die Verbindung von einem HDTV-Empfänger (Set-Top-Box) oder HD-DVD-Player zum Wiedergabegerät führt über digitale Schnittstellen. Für die Konsum-Elektronik wurde das High Definition Multimedia Interface (HDMI) entwickelt. Es kann als der „digitale Ersatz“ für das aus der Analogtechnik bekannte SCART-Interface betrachtet werden. Über ein Kabel mit Stecker-Buchse-Verbindung werden digitale Videosignale, Audiosignale und Steuerdaten übertragen.
4.5.3 Computer-Auflösungsformate nach VESA
Durch die zunehmende Verknüpfung von Fernsehen und Multimedia mit möglichen gemeinsamen Bildwiedergabeeinrichtungen ist es angebracht, die wichtigsten Computer-Auflösungsformate anzuführen. Nach Vorschlägen der VESA (Video Electronic Standard Association) und einem ITU-Standard sind die nach Tabelle 4.3 definierten Formate, basierend auf quadratischen Bildpunkten, möglich.

5. Datenreduktion beim digitalen Videosignal
Die Übertragung des digitalen Video-Studiosignals über gegebene Breitbandkanäle beim Austausch von Programmbeiträgen zwischen den Rundfunkanstalten („Contribution“) sowie bei der Zuführung des Programmsignals zu den Sendestationen und insbesondere aber bei der Verteilung des Programmsignals zu den Fernsehteilnehmern („Distribution“) erfordert eine beträchtliche Datenreduktion. Für den Programmaustausch und die Versorgung der Sendestationen stehen im wesentlichen Digitalverbindungen mit den standardisierten Bitraten innerhalb der Plesiochronen Digitalen Hierarchie (PDH) (nach ITU-T für Europa) mit 8,448 Mbit/s, 34,368 Mbit/s und 139,264 Mbit/s bzw. Synchronen Digitalen Hierarchie (SDH) mit 155,52 Mbit/s zur Verfügung [18].
Die aufgeführten Bitraten werden auch im paketorientierten ATM-Übertragungs- verfahren (Asynchronous Transfer Mode) genutzt. Dieses Verfahren ermöglicht im Gegensatz zu den fest geschalteten Verbindungen eine bedarfsgesteuerte Zuordnung von Übertragungskapazität. Über spezielle Verbindungen, meist Glasfaserleitungen, wie z. B. beim Hybnet der ARD-Sender [70,72], findet auch ein Austausch von Programmbeiträgen mit dem Digitalen Studiosignal DSC 270 Mbit/s statt. Zukünftig wird die Verteilung des datenreduzierten Studiosignals mit 50 Mbit/s über LANs (Local Area Network) an Bedeutung gewinnen. Digitale Übertragungskanäle können nur mit einer festen, vorgegebenen Bitrate betrieben werden, weil empfangsseitig eine auf diese Bitrate abgestimmte Taktrückgewinnung stattfindet.
5.1 Prinzipien der Datenreduktion
Eine Datenreduktion kann auf dem Weg der Redundanzreduktion oder Irrelevanzreduktion erfolgen. Redundanzreduktion bedeutet das Herausnehmen von überflüssiger, weil bereits bekannter Information. Bei der Irrelevanzreduktion erfolgt ein Weglassen von unwesentlicher und meist vom menschlichen Sinnesorgan (Auge, Ohr) nicht wahrnehmbarer Information. Redundante Information findet sich beim Videosignal in nebeneinander oder übereinander liegenden Bildpunkten (spatiale Redundanz) und vor allem in aufeinanderfolgenden Teilbildern bzw. in Ausschnitten derselben (temporale Redundanz).
Es ist deshalb naheliegend, nur den Signalinhalt zu übertragen, der sich bezogen auf vorangehende Bildpunkte (spatial oder temporal), geändert hat. Der unveränderte Signalanteil wird jeweils einem Speicher entnommen. Eine Redundanzreduktion hat keinen Informationsverlust zur Folge. Man spricht deshalb auch von einer verlustlosen Codierung.
Irrelevante Information liegt beim Videosignal in einer hohen Chrominanzauflösung und in den Details der Bilder. Wie schon im Abschnitt 2.3.4 aufgeführt, hat das menschliche Sehorgan eine geringere Auflösung für Farbdetails im Vergleich zu Helligkeitsänderungen. Dem wird beim digitalen Video-Studiosignal mit dem 4:2:2-Abtastraster bereits Rechnung getragen. Darüber hinaus wird auf die Tatsache Bezug genommen, dass im Spektrum eines realen Videosignals die höheren Frequenzkomponenten zunehmend mit geringerer Amplitude vertreten sind und deshalb eine reduzierte Auflösung vertretbar ist. Im Zusammenhang mit der Analog-Digital-Wandlung käme dies einer zu höheren Signalfrequenzen hin größeren Quantisierung gleich. Eine Irrelevanzreduktion hat einen, wenn auch meist nicht wahrnehmbaren, Informationsverlust zur Folge. Es liegt deshalb eine verlustbehaftete Codierung vor.
5.2 Verfahren der Redundanzreduktion
Zugrunde liegt das Prinzip der „Differenzübertragung“, das schematisch in Bild 5.1 dargestellt ist. Einem zeitabhängigen Signal s(t) werden aufeinanderfolgend „Proben“ (Abtastwerte) entnommen. Jeweils ein vorangehender Abtastwert (n-1) aus dem Speicher bzw. dem „Prädiktor“ T wird mit dem aktuellen Wert (n) verglichen. Die Differenz d(n) wird dem Empfänger übertragen und dort zu dem ebenfalls gespeichert vorliegenden Abtastwert (n-1) addiert. Es handelt sich um eine „verlustlose“ Signalübertragung [19].
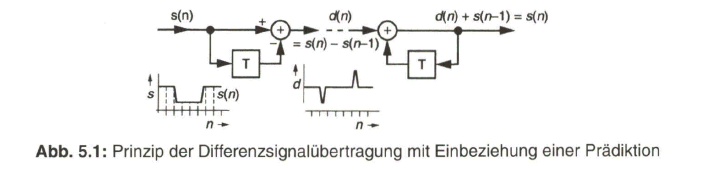
Zusammenhang mit digitaler Signalübertragung wird das zu übertragende Differenzsignal (n) in einem Encoder analog-digital gewandelt sowie empfängerseitig in einem Decoder wieder digital-analog gewandelt (Bild 5.2a). Dabei zeigt sich nun, dass auf der Sendeseite die Prädiktion (n-1) aus dem analogen Eingangssignal ![]() entnommen wird, aber das rekonstruierte Empfangssignal s(n)empf auf einem Vorhersagewert (Prädiktion) s
entnommen wird, aber das rekonstruierte Empfangssignal s(n)empf auf einem Vorhersagewert (Prädiktion) s![]() basiert, der mit dem Quantisierungsfehler des Encoders behaftet ist [20]. Damit wären sendeseitige und empfangsseitige Prädiktion unterschiedlich und es würde zu einer Fehlerfortpflanzung führen. Um dem zu begegnen, wird auch sendeseitig der aus dem Empfangssignal abgeleitete Wert s
basiert, der mit dem Quantisierungsfehler des Encoders behaftet ist [20]. Damit wären sendeseitige und empfangsseitige Prädiktion unterschiedlich und es würde zu einer Fehlerfortpflanzung führen. Um dem zu begegnen, wird auch sendeseitig der aus dem Empfangssignal abgeleitete Wert s![]() als Prädiktion verwendet (Bild 5.2b). Man kommt so zum Verfahren der Differenz-Pulscodemodulation (DPCM) mit prädiktiver Codierung [20].
als Prädiktion verwendet (Bild 5.2b). Man kommt so zum Verfahren der Differenz-Pulscodemodulation (DPCM) mit prädiktiver Codierung [20].
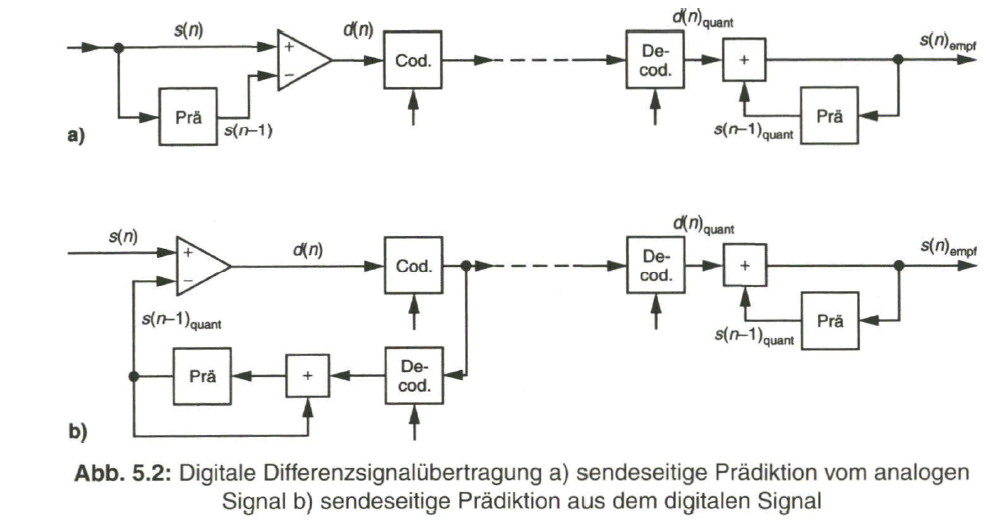
5.2.1 Anwendung der Differenz-Pulscodemodulation (DPCM)
Die statistische Auswertung der Differenzwerte d(n) eines Videobildes zeigt, dass der Wert Null am häufigsten vorkommt und die Wahrscheinlichkeit mit zunehmen dem Differenzwert, positiv oder negativ, sehr schnell absinkt. Es wird deshalb nicht der gesamte Quantisierungsbereich codiert, sondern nur ein kleinerer Bereich für die Differenz werte mit dem Ergebnis, dass die Codewortlänge kürzer und damit die zu übertragende Bitrate geringer wird. Bild 5.3 zeigt dies an einem Beispiel mit Gegenüberstellung der Codierung bei der Pulscodemodulation (PCM) und bei der Differenz-Pulscodemodulation (DPCM).
Der DPCM-Codiervorgang geht von einem „Startwert“ aus, der voll codiert wird (PCM). In gewissen Abständen wird ebenfalls jeweils ein PCM-codierter „Stützwert“ eingefügt, um die Abweichung des rekonstruierten Signals vom Originalsignal zu minimieren.
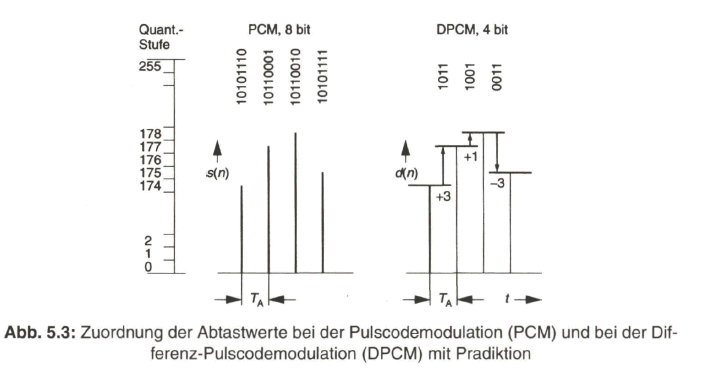
Die praktische Realisierung der DPCM erfolgt über digitale Signalverarbeitung, da ja das Videosignal bereits in digitaler Form vorliegt. Aus dem PCM-Signal, dem digitalen Leuchtdichtesignal Y oder den digitalen Chrominanzsignalen ![]() bzw.
bzw. ![]() mit einer Codewortlänge von z. B.
mit einer Codewortlänge von z. B. ![]() bit wird über digitale Subtraktion des Prädiktionssignals ein Differenzsignal
bit wird über digitale Subtraktion des Prädiktionssignals ein Differenzsignal ![]() mit
mit ![]() bit berechnet, das dann in einer nachfolgenden Quantisierung (Q) auf eine Wortbreite von
bit berechnet, das dann in einer nachfolgenden Quantisierung (Q) auf eine Wortbreite von ![]() bit reduziert wird. Dieses DPCM-Codesignal wird dem Empfänger zugeführt und dort über eine „inverse Quantisierung“
bit reduziert wird. Dieses DPCM-Codesignal wird dem Empfänger zugeführt und dort über eine „inverse Quantisierung“ ![]() in ein 8-bit-Codewort umgewandelt und in die Prädiktionsschleife eingeführt. Dieser Vorgang geschieht auch auf der Sendeseite zur Rekonstruktion des Prädiktionssignals. Siehe dazu Bild 5.4.
in ein 8-bit-Codewort umgewandelt und in die Prädiktionsschleife eingeführt. Dieser Vorgang geschieht auch auf der Sendeseite zur Rekonstruktion des Prädiktionssignals. Siehe dazu Bild 5.4.
Aus der Grundidee des DPCM-Verfahrens ist zu entnehmen, dass die zu übertragende Information im Differenzsignal (n) umso geringer ist, je näher der Prädiktionswert (n-1) an den tatsächlich vorliegenden Signalwert (n) herankommt, das heißt je besser die Prädiktion ist. Geht man von der konstanten Codewortlänge ab und ordnet den häufig vorkommenden geringen Differenzwerten kurze Codeworte zu, im Gegensatz zu längeren Codeworten für die nur selten vorkommenden größeren Differenzwerte, so ergibt sich bereits eine beträchtliche Datenreduktion. Ziel ist nun, eine Prädiktion bei den Abtastwerten zu gewinnen, die der aktuellen Situation am nächsten kommt.
Eine Prädiktion beim Videobild kann abgeleitet werden aus benachbarten Bildpunkten innerhalb einer Zeile (eindimensionale Prädiktion) oder unter Bezugnahme auf benachbarte Bildpunkte in der vorangehenden Zeile desselben Halbbildes oder Vollbildes (zweidimensionale Prädiktion, als „Intrafield-Prädiktion“ oder „Intraframe-Prädiktion“). In Bildbereichen ohne Bewegung erhält man die beste Voraussage durch den Bildpunkt an der gleichen Stelle im vorangehenden Vollbild (Interframe-Prädiktion). Diese Prädiktion wird jedoch dann zu Fehlern führen, wenn sich der Bildinhalt bei bewegten Vorlagen von Teilbild zu Teilbild ändert. Es wird deshalb zunächst der gesamte Bereich des aktiven Bildes, mit z.B. 720 x 576 Pixel, in kleine Ausschnitte unterteilt und die Änderung innerhalb dieser Ausschnitte untersucht.
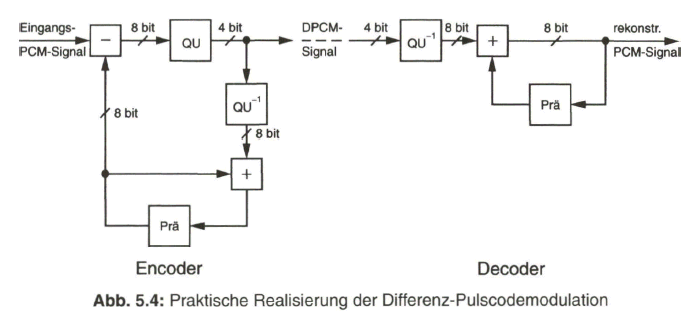
In Verbindung mit dem MPEG-2-Standard, der später im Abschnitt 7.2 ausführlich behandelt wird, bezeichnet man einen solchen „Ausschnitt“, der üblicherweise den Bereich von 16x16 Pixel abdeckt, als Makroblock. Das aktive Bild mit 720 x 576 Pixel wird damit in
(720 : 16) X (576 : 16) = 45 x 36 = 1620 Makroblöcke unterteilt.
5.2.2 Differenzbildübertragung mit Bewegungskompensation
Zur Verbesserung der Prädiktion erfolgt nun in den Makroblock-Ausschnitten eine so genannte Bewegungskompensation (Moving compensation). Es wird zunächst der Makroblock-Ausschnitt, im Folgenden als „Musterblock“ bezeichnet, des aktuellen (Voll-)Bildes mit dem korrespondierenden Musterblock des vorangehenden (Voll-)Bildes verglichen, indem ein Summenwert der Beträge der Differenz in den einzelnen Bildpunkten des Musterblocks berechnet wird: Displaced Frame Difference, DFD. Durch bildpunktweises Verschieben des Musterblockes aus dem vorangehenden Bild in horizontaler und vertikaler Richtung und jeweils erneutes Berechnen der DFD wird die Position des Musterblocks aus dem vorangehenden Bild gesucht, bei der die DFD am geringsten ist. Die Verschiebung des Musterblocks wird durch die Bewegungsvektoren Delta ![]() und Delta
und Delta ![]() ausgedrückt. Der Vorgang zur Ermittlung dieser Bewegungsvektoren wird als Bewegungsschätzung (Motion estimation) bezeichnet. Die Prädiktion zu den Bildpunkten aus dem aktuellen Musterblock liefern nun die Bildpunkte des Musterblocks aus dem vorangehenden (Voll-) Bild, verschoben um die berechneten Bewegungsvektoren Delta X und Delta Y (Bild 5.5). Auf diese Weise wird das bewegungskompensierte Bild blockweise dem aktuellen Bild weitestgehend ähnlich. In Bild 5.5 ist das übertragene Teilbild
ausgedrückt. Der Vorgang zur Ermittlung dieser Bewegungsvektoren wird als Bewegungsschätzung (Motion estimation) bezeichnet. Die Prädiktion zu den Bildpunkten aus dem aktuellen Musterblock liefern nun die Bildpunkte des Musterblocks aus dem vorangehenden (Voll-) Bild, verschoben um die berechneten Bewegungsvektoren Delta X und Delta Y (Bild 5.5). Auf diese Weise wird das bewegungskompensierte Bild blockweise dem aktuellen Bild weitestgehend ähnlich. In Bild 5.5 ist das übertragene Teilbild ![]() als voll übertragendes „Stützbild“ angenommen. Die verbleibende zu übertragende Differenz-Information ist nun wesentlich geringer als die Information aus den Original-Musterblöcken. Wegen der „blockweisen“ Anpassung des Bildinhaltes spricht man auch von Blockmatching.
als voll übertragendes „Stützbild“ angenommen. Die verbleibende zu übertragende Differenz-Information ist nun wesentlich geringer als die Information aus den Original-Musterblöcken. Wegen der „blockweisen“ Anpassung des Bildinhaltes spricht man auch von Blockmatching.
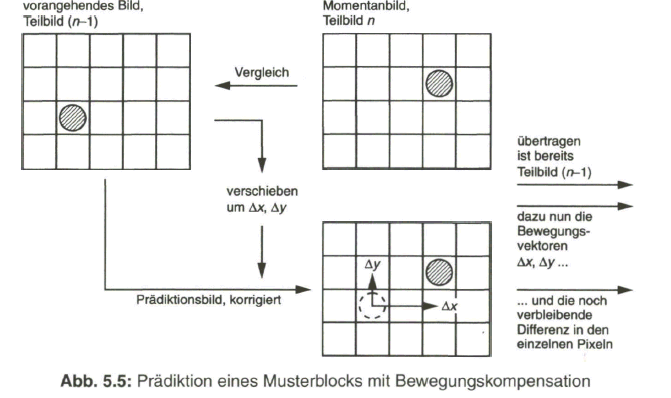
Der Rechenaufwand bei diesem Verfahren ist zunächst sehr hoch. Mit einem Suchbereich von ±16 Pixel horizontal und ±8 Pixel vertikal und den Rechenoperationen Subtraktion und Betragsbildung, sowie Addition der absoluten Differenzen führt das zu
(45 x 36 Makroblöcke/Bild) x (32 x 16 Suchpositionen/Makroblock) x (16 x 16 Pixel/Makroblock) x (3 Rechenoperationen/Pixel) x (25 Bilder/s)
= 16 Milliarden Rechenoperationen/s.
Mit intelligenten Rechenverfahren ist eine Verringerung möglich. Die Musterblock-Größe mit 16 x 16 Pixel stellt einen Kompromiss zwischen möglichst guter Prädiktion und möglichst geringer Datenmenge des Differenzbildes dar. Je kleiner der Musterblock ist, umso besser wird die Prädiktion, aber der Rechenaufwand steigt an.
Mit größerem Musterblock sinkt zwar der Rechenaufwand, aber die Prädiktion wird schlechter. Der Suchbereich hängt von der maximalen Bewegungsgeschwindigkeit der Bildszene ab, meist wird dafür eine Bildbreite/s angenommen. Die Grenzen des Suchbereiches werden darauf bezogen üblicherweise mit ±16 Pixel horizontal und ±8 Pixel vertikal festgelegt. Je kleiner die Schrittweite bei der Suche nach dem Minimum der DFD ist, desto genauer werden die ermittelten Bewegungsvektoren. Es wird deshalb auch mit „half-pixel-Schritten“ gearbeitet. Das durch die Bewegungskompensation ergänzte Blockschaltbild des DPCM- Encoders und -Decoders zeigt Bild 5.6. Auf der Empfangsseite entfällt die aufwändige Berechnung der Bewegungsvektoren. Vielmehr werden diese über datenreduzierte Codeworte zusammen mit dem eigentlichen Differenzsignal übertragen.
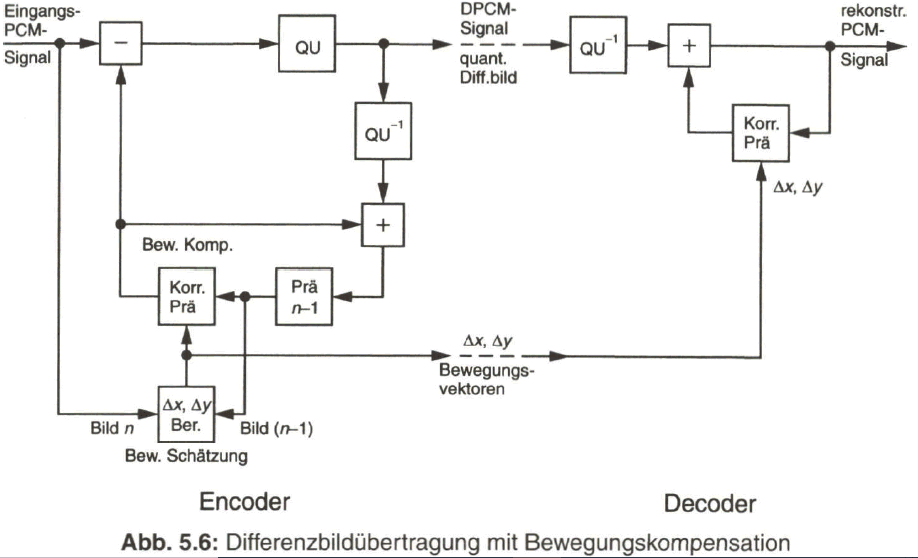
Die Differenzübertragung mit Bewegungskompensation bewirkt eine Datenreduktion bis etwa um den Faktor vier, abhängig vom Bildmaterial.
5.3 Verfahren der Irrelevanzreduktion
Die Irrelevanzreduktion beim Videosignal nimmt Bezug auf gewisse Unvollkommenheiten des menschlichen Auges. Dies gilt auch für die mit feineren Bildstrukturen nicht mehr wahrnehmbaren Quantisierungsverzerrungen. Eine Umsetzung dieser Tatsache in eine technische Realisierung könnte bei einem analogen Videosignal so erfolgen, indem das Videofrequenzband über Bandpässe in mehrere Teilbereiche aufgespaltet wird, deren Signale mit zunehmender Mittenfrequenz bei der Analog-Digital-Wandlung grober quantisiert werden. Das Verfahren wäre sehr aufwändig und insbesondere bei schmalen Bandpässen sehr problematisch hinsichtlich der dabei auftretenden Gruppenlaufzeitverzerrungen. Eine elegantere Lösung bietet sich mit dem digitalen Videosignal und digitaler Signalverarbeitung durch Verlagerung des Aufwandes in die Software-Ebene. Zur Anwendung kommt dabei eine Transformationscodierung mit Codierung im Frequenzbereich. Von verschiedenen Möglichkeiten hat sich bei Videosignalen als günstigstes Verfahren die Diskrete Cosinus-Transformation (DCT) erwiesen. Die Diskrete Cosinus-Transformation (DCT) ist eine nahe Verwandte der Diskreten FOURIER-Transformation (DFT), aus deren Ergebnis der Cosinus-Anteil übernommen wird, was bei dem mathematischen Verfahren der „schnellen“ Diskreten FOURIER-Transformation (FDFT) zu Vereinfachungen führt.
5.3.1 Anwendung der Diskreten Cosinus-Transformation (DCT)
Die Zuordnung des Bildinhaltes auf eine Vielzahl von „Teilfrequenzbereichen“ erfolgt nun unter Bezugnahme auf so genannte „Basismuster“. Dazu wird die Bildvorlage wiederum in kleine Ausschnitte unterteilt, die mit dem aus dem MPEG-2- Vokabular vorweggenommenen Ausdruck „Block“ bezeichnet werden. Die Blockgröße beträgt üblicherweise 8 x 8 Pixel. Die „Intensitätsverteilung“ (Leuchtdichte /oder Chrominanzanteil CB bzw. CR) in jedem Block wird dann interpretiert durch eine gewichtete Überlagerung der Basismuster, die mit Koeffizienten (Adresse und Intensität) in codierter Form ausgedrückt werden. Man verwendet 8 x 8 = 64 Basismuster, die in horizontaler und vertikaler Richtung steigend feiner strukturiert sind und so einen Bezug auf eine Vielzahl von „Teilfrequenzbereichen“ erlauben. Die bei der DCT verwendeten Basismuster sind in Bild 5.7 wiedergegeben.

In der linken oberen Ecke findet sich das homogene Basismuster, mit dem die mittlere Helligkeit (DC) im Block angegeben wird. Von dort bzw. von den Mustern in der linken Spalte nach rechts gerichtet wird die Horizontalauflösung feiner und von der oberen Zeile nach unten gerichtet wird die Vertikalauflösung feiner. In der Diagonale ist deutlich die ansteigende Strukturauflösung zu ersehen. Den Basismustern wird eine Gewichtung über 64 Intensitätsstufen zwischen den Helligkeits- (Intensitäts-) Grenzen „weiß“ und „schwarz“ zugeordnet.
Das Videobild mit 720 x 576 Pixel (für Luminanz Y) wird unterteilt in (720 : 8) x (576 : 8) = 90 x 72 = 6480 Blöcke mit jeweils 8 x 8 Pixel. Jeder Block wird dann in seinem Bildinhalt verglichen mit den 64 Basismustern und „synthetisiert“ durch die Überlagerung der gewichteten Basismuster, die durch ihre Koeffizienten Fuv angegeben werden. Die Umsetzung der Helligkeitsverteilung Y (x,y) eines 8 x 8-Pixel-Blocks in die 8x8 Koeffizienten der Basismuster durch die DCT bzw. die Rückumsetzung der Koeffizienten in die Helligkeitsverteilung durch die Inverse DCT zeigt prinzipiell Bild 5.8.
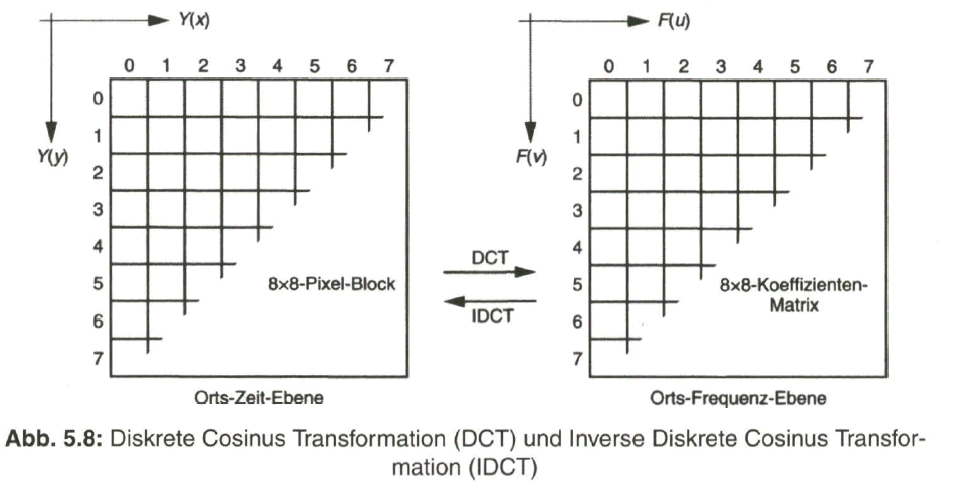
Die Koeffizienten ![]() der Basismuster sind in einer 8x8-Matrix abgelegt. Die Zuordnung zwischen den Basismustern und den Koeffizienten zeigt ausschnittsweise Bild 5.9
der Basismuster sind in einer 8x8-Matrix abgelegt. Die Zuordnung zwischen den Basismustern und den Koeffizienten zeigt ausschnittsweise Bild 5.9
Für die Diskrete Cosinus-Transformation der Intensitätsverteilung Y (x,y) = f (x,y) aus dem Orts-Zeit-Bereich in den Orts-Frequenz- bzw. Orts-Koeffizienten- Bereich F (uv) gilt die Rechenvorschrift:
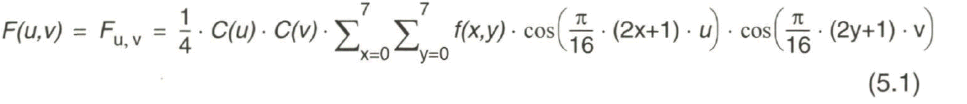
Das Eingangssignal F (x,y) liegt aus einem 8x8-Pixel-Block mit x, y = 0,1,2, 3,4, 5, 6, 7 vor.
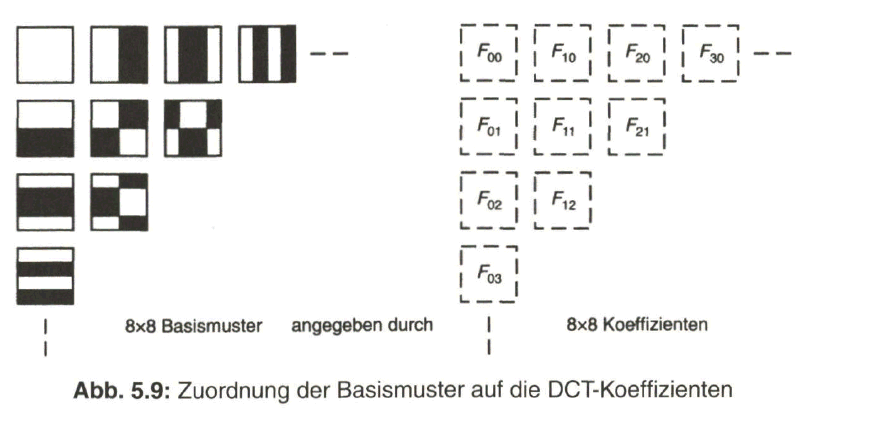

Die Orts-Frequenzen der Koeffizienten-Matrix werden angegeben mit u, v= 0, 1,
2, 3,4, 5, 6, 7.
An einem Beispiel mit den aus [24] entnommenen Zahlenwerten sei die DCT mit den nachfolgenden Schritten zur Datenreduktion nun demonstriert.
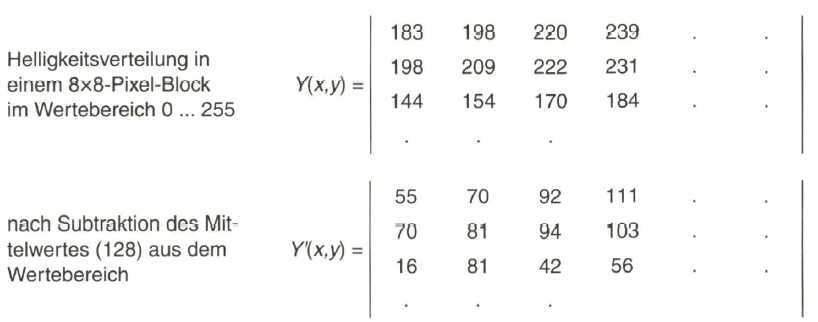
Als Vorbereitung für die Irrelevanzreduktion erfolgt nun die Diskrete Cosinus- Transformation, mit Bezug auf die Basismuster und Angabe der DCT-Koeffizienten F(u,v)
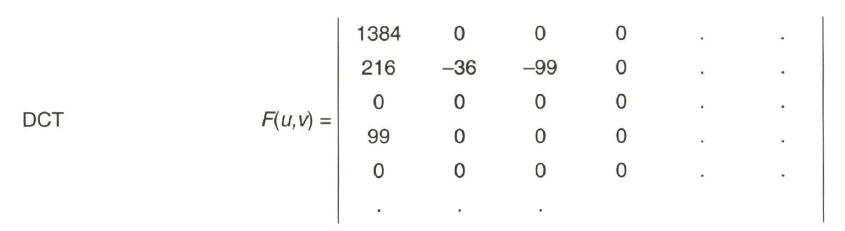
Der DC-Koeffizient wird mit höherer Genauigkeit angegeben
5.3.2 Frequenzabhängige Quantisierung
Mit dem nächsten Schritt wird eine frequenzabhängige Quantisierungstabelle Q(u,v) eingebracht,


Nach Rundung (INT) erhält man QF'(u, v) zu

Es zeigt sich, dass viele der Koeffizienten zu Null werden, was die Möglichkeit einer datenreduzierten Übertragung der Koeffizienten erschließt.
5.4 Redundanzreduktion beim Datenstrom durch Lauflängencodierung (RLC) und Variable Längen Codierung (VLC)
Als Vorbereitung für die Datenreduktion wird über ein Zick-Zack-Auslesen das Umsortieren derquantisierten und gerundeten Koeffizienten vorgenommen. Man erhält damit aus der Matrix. Als Vorbereitung für die Datenreduktion wird über ein Zick-Zack-Auslesen das Umsortieren derquantisierten und gerundeten Koeffizienten vorgenommen. Man erhält damit aus der Matrix
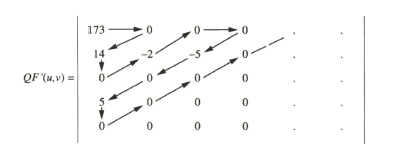
die Koeffizienten in der Reihenfolge
173 0 14 0-2 00-5 05 00 0 . . .
Diese Koeffizientenfolge wird nun einer Redundanzreduktion unterzogen, über eine Lauflängencodierung, Run Length Coding (RLC) mit zwei Ziffern. Dabei gibt die erste Ziffer die Länge der ununterbrochenen Folge von Nullen vor dem Wert an, der gleich der zweiten Ziffer selbst ist. Am Ende der Koeffizientenfolge aus der Zick-Zack-Abtastung befindet sich meist nur noch eine lange Folge von Nullen. In diesem Fall wird das „end of block“-Codewort ausgegeben und der Decoder weiß, dass nur noch Nullen folgen. Es folgt eine weitere Redundanzreduktion über eine Entropie-Codierung als Variable-Längen-Codierung, Variable Length Coding (VLC).
Dabei werden mit Hilfe von HUFFMAN-Tabellen häufig vorkommende Codewort- Kombinationen in kürzere Codeworte und weniger häufig vorkommende Kombinationen in längere Codeworte umgesetzt. Insgesamt ergibt sich eine beträchtliche Reduktion der Datenmenge, Das Prinzip der variablen Längen-Codierung liegt bereits dem MORSE-Alphabet zu Grunde.
Koeffizientenfolge nach der Zick-Zack-Abtastung:
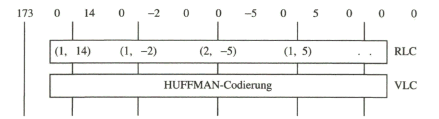
Der DC-Koeffizient (im Bereich 0 ... 511) wird mit 9 bit direkt codiert.
Die Variable-Längen-Codierung mit HUFFMAN-Tabellen wird auf Lauflängen und Amplitudenwerte im Bereich 0 ... 15 angewendet. Für Kombinationen, die nicht in der auf diesen Bereich bezogenen Tabelle enthalten sind, wird die Codierung der Lauflänge und der Amplitude mit fester Codewortlänge vorgenommen. Für diesen Fall muss den beiden Codewörtern eine eindeutige Markierung vorangestellt werden, damit der Decoder erkennt, dass auf diese Codewörter nicht die Huffmann-Tabelle angewendet werden darf.
Bei der Wahl der Blockgröße ist abzuwägen, dass bei zu großen Blöcken verschiedene Bildinhalte an den Blockgrenzen nach der Quantisierung in den Nachbarblock übersprechen können und ein sehr hoher Rechenaufwand erforderlich wird. Bei zu kleinen Blöcken aber werden die Nachbarschaftsbeziehungen im Block nur wenig ausgenutzt. Eine Blockgröße von 8x8 Pixel hat sich bei der DCT als optimal erwiesen, Bei der unabhängigen Codierung benachbarter Bildblöcke können teilweise noch durch die Unstetigkeiten an den Blockgrenzen sichtbare Plattenstrukturen auftreten. Man bezeichnet dies als „Blocking-Effekt“.
Die Datenreduktion über
• DCT, mit Quantisierung und Rundung, als Irrelevanzreduktion,
• Zick-Zack-Auslesen der Koeffizienten und
• RLC sowie VLC, als Redundanzreduktion
führt zu einer Reduzierung der Datenrate, abhängig von der Bildvorlage, bis etwa um den Faktor 12.
Zusammen mit der über DPCM mit Bewegungskompensation vorgenommenen Redundanzreduktion lässt das je nach Bildmaterial eine Datenreduktion bis nahezu um den Faktor 50 zu, ohne dabei wesentlich auf Qualität verzichten zu müssen. In der Praxis kann von einem Faktor zwischen 25 und 40 ausgegangen werden, wie später noch an einem Beispiel gezeigt wird.
5.5 Anwendung der Datenreduktionsverfahren bei der Magnetbandaufzeichnung
Das eigentliche Ziel bei der Datenreduktion ist ein hoher Reduktionsfaktor ohne merkbaren Qualitätsverlust beim wiedergegebenen Signal. Beim Videosignal werden dazu eine Redundanzreduktion mit dem Verfahren der Differenzbildübertragung mit Bewegungskompensation und eine Irrelevanzreduktion unter Zuhilfenahme der DCT vorgenommen. Die Differenzbildübertragung bezieht mindestens zwei oder sogar mehrere aufeinanderfolgende Teilbilder in den Vorgang mit ein. Dies kann aber zu Problemen bei der Bearbeitung von Programmbeiträgen im Studio beim bildgenauen „Schneiden” führen. Somit kann für diesen Fall nur die auf ein Teilbild bezogene DCT zur Anwendung kommen. Um trotzdem eine über die Möglichkeit der DCT und die darauf folgenden Maßnahmen hinausgehende Datenreduktion zu erreichen, wird zusätzlich vorangehend eine Bewegungsschätzung vorgenommen. Das Verfahren der so genannten Intraframe-Codierung kommt zur Anwendung bei allen auf dem DV-Standard basierenden Aufzeichnungsformaten. Dazu gehören für
• semiprofessionelle Anwendung
die Systeme DVund DVCam (u.a. Panasonic, Sony) mit Rasterkonversion von 4:2:2 auf 4:2:0 zur Aufzeichnung und Datenreduktion auf 25 Mbit/s,
• professionelle Anwendung
die Systeme DVCPro25 (Panasonic) und SX (Sony) mit Rasterkonversion von 4:2:2 auf 4:1:1 mit einer Datenrate von 125 Mbit/s und Aufzeichnung mit 25 Mbit/s bzw. 18 Mbit/s und DVCPro (Panasonic) sowie Digital-S (Sony) mit Beibehaltung des 4:2:2- Abtastrasters und Datenreduktion auf 50 Mbit/s.
Bei diesen Systemen für professionelle Anwendung wird zusätzlich über eine Bewegungsschätzung die optimale Wahl der Quantisierungstabellen vorgenommen. In Bild 5.10 wird dies am Beispiel der Codierung bei DVCPro erläutert. Eine weitere Möglichkeit der Datenreduktion und Erhaltung einer nahezu Studioqualität basiert auf der Codierung gemäß dem MPEG-2-Video-Standard mit I-Bildern (Intraframe) oder einer kurzen Gruppe von Bildern (GOP) aus jeweils einem I-Bild und einem zwischen zwei I-Bildern interpolierten B-Bild (bipolar prädiziert), einer so genannten I-B-Gruppe. Zur MPEG-Codierung siehe Näheres im Abschnitt 7.
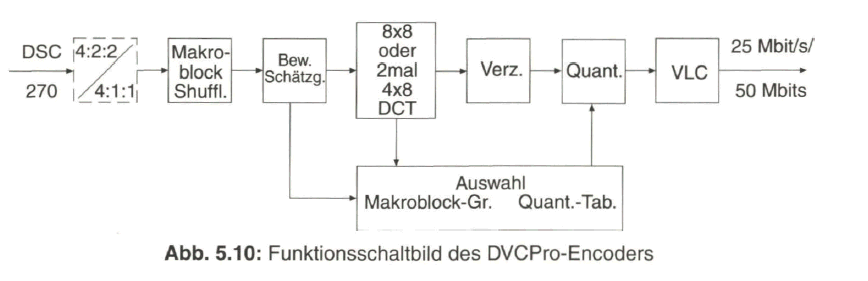
Der aktive Anteil des digitalen Studiosignals DSC 270 wird entweder direkt übernommen (DVCProöO) oder einer Rasterkonversion von 4:2:2 auf 4:1:1 (DVCPro25) unterzogen. Es werden dann Makroblöcke gebildet mit 16 x 16 Pixel (je 4 Blöcke 8x8 Pixel) beim ![]() Signal und dazugehörige Makroblöcke für
Signal und dazugehörige Makroblöcke für ![]() und
und ![]() mit jeweils 8 x 16 Pixel bei DVCPro50 beziehungsweise 8 x 8 Pixel bei DVCPro25. Über ein Shuffling der Makroblöcke eines Teilbildes werden Makroblock-Gruppen gebildet, die sich bezogen auf weniger oder mehr Bewegung innerhalb einer Gruppe unterscheiden. Daraus wird auf DCT in einem 8x8-Pixel-Block (vom Vollbild) oder auf zweimal DCT in 4x8-Pixel-Blöcken (beide Halbbild- Anteile) entschieden. Ergänzend wird über die Bewegungsschätzung eine Auswahl der günstigsten Quantisierungstabelle vorgenommen, die wegen der Bearbeitungszeit in der Bewegungsschätzung auf die verzögert übernommenen DCT- Koeffizienten eingebracht wird. Die nachfolgende Variable Längencodierung (VLC) setzt die statistisch häufiger vorkommenden quantisierten und gerundeten Koeffizienten in kürzere Codeworte um, die seltener vorkommenden Koeffizienten in längere Codeworte, so dass im Mittel eine zusätzliche Datenkompression auf die Aufzeichnungs-Bitrate von 25 Mbit/s bei DVCPro25 beziehungsweise 50 Mbit/s bei DVCPro50 erfolgt.
mit jeweils 8 x 16 Pixel bei DVCPro50 beziehungsweise 8 x 8 Pixel bei DVCPro25. Über ein Shuffling der Makroblöcke eines Teilbildes werden Makroblock-Gruppen gebildet, die sich bezogen auf weniger oder mehr Bewegung innerhalb einer Gruppe unterscheiden. Daraus wird auf DCT in einem 8x8-Pixel-Block (vom Vollbild) oder auf zweimal DCT in 4x8-Pixel-Blöcken (beide Halbbild- Anteile) entschieden. Ergänzend wird über die Bewegungsschätzung eine Auswahl der günstigsten Quantisierungstabelle vorgenommen, die wegen der Bearbeitungszeit in der Bewegungsschätzung auf die verzögert übernommenen DCT- Koeffizienten eingebracht wird. Die nachfolgende Variable Längencodierung (VLC) setzt die statistisch häufiger vorkommenden quantisierten und gerundeten Koeffizienten in kürzere Codeworte um, die seltener vorkommenden Koeffizienten in längere Codeworte, so dass im Mittel eine zusätzliche Datenkompression auf die Aufzeichnungs-Bitrate von 25 Mbit/s bei DVCPro25 beziehungsweise 50 Mbit/s bei DVCPro50 erfolgt.
Das System Digital-S von Sony wurde sehr bald von dem MPEG50 l-frame only abgelöst, das unter dem Sony-Markenzeichen IMX eingeführt wurde. Das Interesse mehrerer ARD-Rundfunkanstalten richtete sich auf die „Vielseitigkeit” von IMX in Bezug auf Einsatzmöglichkeiten, Verwendbarkeit der Cassetten, verschiedene Ausgangssignale und der Möglichkeit, vorhandene Aufzeichnungen mit Magnetaufzeichnungsgeräten der älteren Systeme Beta, BetaSP und DigiBeta auf IMX-Geräten abzuspielen.
6. Datenreduktion beim digitalen Audiosignal
Die Aufbereitung des digitalen Audio-Quellensignals erfolgt nach dem Verfahren der Pulscodemodulation, wie in Abschnitt 4.1.1 beschrieben. Der Signalfrequenzbereich reicht von 20 Hz (30 Hz) bis 20 kHz (15 kHz). Standardisierte Werte für die Abtastfrequenz sind 32 kHz (>2-15 kHz), 44,1 kHz (Abtastfrequenz bei der MCD) und 48 kHz (Studio). Mit einer Abtastfrequenz von 48 kHz und einer Codierung mit üblicherweise 16 bit pro Codewort (im Studio auch mit 20 bit) beträgt die Bitrate pro Audiokanal
![]()
r ein Stereosignal beläuft sich die Bitrate dann auf 1,536 Mbit/s.
Obwohl die Datenrate des digitalen Audiosignals im Vergleich zum Videosignal wesentlich niedriger liegt, bietet sich auch hier eine Datenkompression über Verfahren der Irrelevanzreduktion und Redundanzreduktion an. Die Arbeiten an Verfahren zur Datenreduktion beim digitalen Audiosignal wurden in den achtziger Jahren entscheidend beeinflusst durch die beabsichtigte Einführung der digitalen Tonsignalübertragung im Rundfunkbereich mit dem Digital Audio Broadcasting (DAB). Es wurden dafür Datenreduktionsverfahren untersucht, die vornehmlich die Unzulänglichkeiten des menschlichen Gehörs ausnutzen.
Am Institut für Rundfunktechnik (IRT) in München wurde 1988 das sog. MAS-CAM-Verfahren vorgestellt, aus dem im Folgenden über die Zusammenarbeit mit Philips und Matsushita das MUSICAM-Verfahren (Masking Pattern Universal Subband Integrated Coding And Multiplexing) entstand. Basis dieses Verfahrens ist die Teilbandcodierung mit Herausnahme von nicht wahrnehmbarer Information. Es wird so eine Irrelevanzreduktion vorgenommen.
Parallel zu diesem Teilbandcodierungsverfahren wurde von der Fraunhofer-Gesellschaft und Thomson das ASPEC-Verfahren (Adaptive Spectral Perceptual Entropy Coding) entwickelt, das nach dem Prinzip der Transformationscodierung arbeitet. Das Audiosignal wird mittels DCT vom Zeitbereich in den Frequenzbereich transformiert, um in dieser Ebene irrelevante Signalanteile zu entfernen. Auf die zu übertragenden Codeworte und Steuerinformationen wird im Weiteren noch zusätzlich eine Redundanzreduktion eingebracht.
6.1 Psychoakustisches Modell des menschlichen Ohres
Die weitgreifende Irrelevanzreduktion bei den Tonsignalen basiert auf einem psychoakustischem Modell des menschlichen Ohres, das im Wesentlichen auf Untersuchungen von Prof. Zwicker an der TU München zurückgeht. Seit langer Zeit war bereits bekannt, dass die Empfindlichkeit des menschlichen Ohres für die Hörbarkeit von Tönen stark frequenzabhängig ist. Die höchste Empfindlichkeit weist das Ohr im Frequenzbereich von etwa 1 kHz bis 5 kHz auf, sehr tiefe Töne unter 30 Hz und sehr hohe Töne oberhalb 15 kHz werden praktisch nicht mehr wahrgenommen. Auch eine gewisse Mindestlautstärke ist Voraussetzung für die Wahrnehmbarkeit von akustischen Reizen.
Bild 6.1 gibt dazu die Ohrempfindlichkeitskurve für die Ruhehörschwelle wieder, womit der Schalldruckpegel L als physikalisches Maß für die Lautstärke angegeben wird, der notwendig ist für die Wahrnehmbarkeit eines Tones abhängig von seiner Frequenz. Zu höherer Lautstärke hin verschiebt sich die Kurve im Wesentlichen parallel zu höheren Werten des Schalldruckpegels.
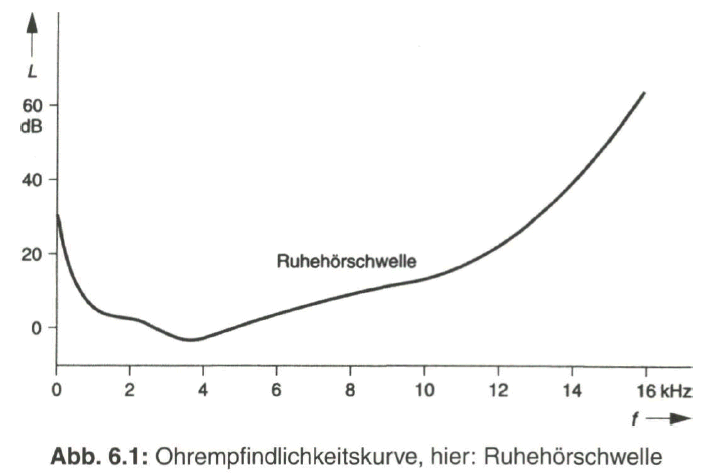
Die Untersuchungen am menschlichen Hörorgan haben zu der Entdeckung von Maskierungseffekten geführt. Beim Auftreten eines starken Tonsignals werden weitere frequenzbenachbarte und über der Ruhehörschwelle liegende Töne durch die Maskierung im Frequenzbereich nicht mehr wahrgenommen. Im Gegensatz zur statischen Ruhehörschwelle tritt nun eine dynamische Mithörschwelle oder Maskierungsschwelle (Masking Threshold) auf. Deren Verlauf hängt von der Frequenz des maskierenden Tones ab. Der beeinflusste Frequenzbereich ist umso breiter je höher die Frequenz des dominierenden Signals ist (Bild 6.2). Die überdeckten und vom Ohr nicht mehr wahrgenommenen Tonsignale müssen nicht übertragen werden. Es erschließt sich damit auch die Möglichkeit, sowohl den Bereich unterhalb der statischen Ruhehörschwelle als auch den Bereich unterhalb der sich ständig ändernden dynamischen Mithörschwelle für das Quantisierungsgeräusch auszunutzen.
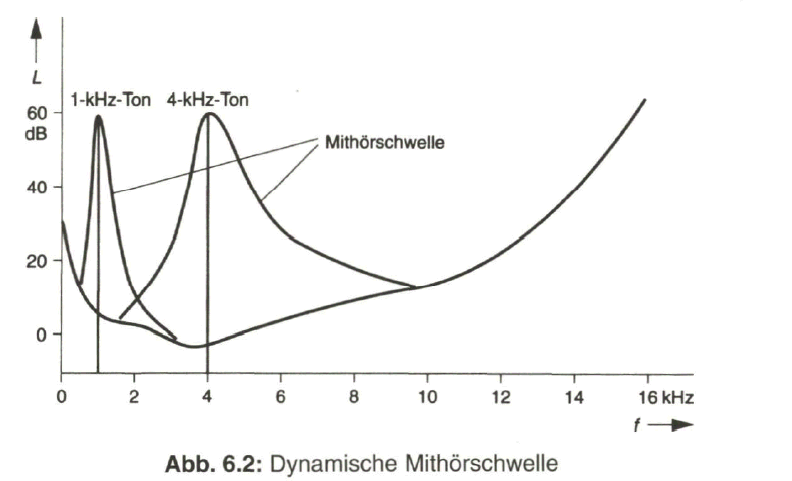
Ein weiterer Maskierungseffekt tritt im Zeitbereich auf. Beim Auftreten eines starken, impulsartigen Signals werden Töne unter einer bestimmten Schwelle sowohl vor, aber insbesondere nach dem maskierenden Signal überdeckt. Bei den bisher technisch realisierten Audio-Datenkompressionsverfahren wird dieser Effekt jedoch noch nicht berücksichtigt.
6.2 Prinzip der Teilbandcodierung
Ähnlich wie bereits bei der Wahrnehmung von Farbreizen durch das menschliche Auge im Abschnitt 2.3 beschrieben, lässt sich auch beim menschlichen Hörorgan über eine eingeschränkte Wahrnehmbarkeit von Schallereignissen eine Irrelevanzreduktion einbringen. Auf Grund der Frequenzabhängigkeit des menschlichen Hörorgans bietet es sich an, zur Verarbeitung der Tonsignale den gesamten Audiofrequenzbereich von 20 Hz bis 20 kHz in Teilbänder mit fester Bandbreite zu separieren. Bei dem MUSICAM-Verfahren, das die Teilbandcodierung mit einbezieht, sind es 32 Teilbänder mit je 750 Hz Bandbreite. Diese grobe Aufteilung des Audio-Frequenzbereiches in die Teilbänder wird über eine so genannte „Filterbank“ vorgenommen, mit digitaler Signalverarbeitung des PCM-Eingangssignals. In Bild 6.3 ist diese Unterteilung schematisch durch 8 Teilbänder (1 ... 8) angedeutet.
Die Codierung des Audiosignals in den Teilbändern erfolgt so, dass das damit verbundene Quantisierungsgeräusch den Pegel bis zur Ruhehörschwelle ausnutzt. Bei tiefen und bei höheren Frequenzen kann mit einer gröberen Quantisierung gearbeitet werden und es braucht nicht der gesamte Frequenzbereich mit der vollen Codewortlänge von z.B. 16 bit aufbereitet werden. Wird ein Signal (7 kHz-Ton in Bild 6.3) in einem Teilband durch Signale in benachbarten Teilbändern (5 kHz-Ton) vollkommen maskiert, so kann das entsprechende Teilband (4) bei der Übertragung wegfallen. Damit erschließt sich aber auch die Möglichkeit, den Bereich unterhalb der Mithörschwelle (Bild 6.3, Teilband 3) zusätzlich für das Quantisierungsgeräusch auszunutzen.
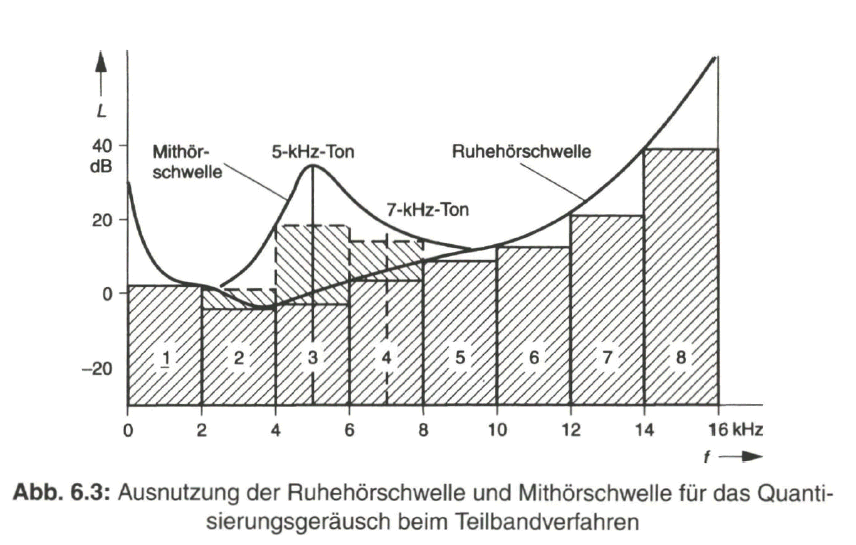
Neben der groben Frequenzbandunterteilung mit Bandpässen (BP) und nachfolgender, der Ruhehörschwelle angepasster Quantisierung, wird eine spektrale Analyse des anliegenden Signalgemisches mittels schneller FOURIER-Transformation (FFT) über einen Block von Abtastwerten vorgenommen. Mit einer zeitlichen Auflösung von z.B. 24 ms, über die das Signal mit 1024 Abtastwerten als unverändert betrachtet wird, erfolgt eine Transformation in den Frequenzbereich mit einer feinen spektralen Auflösung. Daraus wird unter Einbeziehung des psychoakustischen Modells des menschlichen Hörorgans über die Mithörschwelle eine dynamische Steuerung der Quantisierung vorgenommen. Bild 6.4 zeigt schematisch die Teilbandcodierung mit variabler Quantisierung in den Teilbändern.
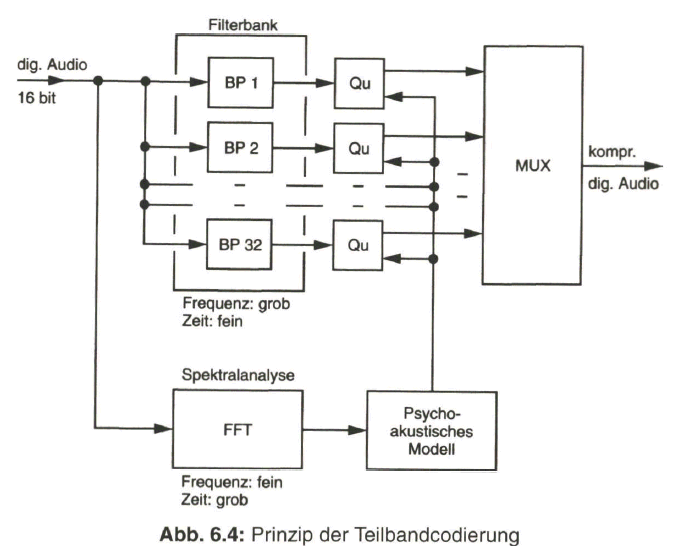
Das psychoakustische Modell des menschlichen Ohres ist als zentrale Funktionseinheit im MUSICAM-Encoderenthalten. Neben der bereits beschriebenen spektralen Analyse, mit grober Unterteilung über die „Filterbank“ und feiner Analyse mittels FFT, wird auch im Spannungs- bzw. Pegelbereich eine Unterteilung vorgenommen. Der gesamte Dynamikbereich von 128 dB wird in 64 Stufen von je 2 dB aufgeteilt, markiert durch einen Skalenfaktor in 6-bit-Codeworten.
Der Skalenfaktor wird jeweils aus einem Block von 12 Abtastwerten ermittelt, indem man aus dem höchsten Abtastwert einen Skalierungsfaktor bestimmt, mit dem diese Signalproben bewertet übertragen werden [2, 8, 24, 27]. Mit zusätzlichen Maßnahmen, wie Lauflängencodierung (RLC) sowie variabler Längen-Codierung (VLC), erfolgt eine Redundanzreduktion bei den gewonnenen Daten. Bild 6.5 zeigt nun das Funktionsschaltbild des MUSICAM-Encoders. Die erreichbare Datenreduktion erfolgt je nach der Komplexität des Encoders ausgedrückt durch die Layers (siehe Abschnitt 6.3) bis zu einem Faktor zehn. Den Layers I und II liegt die Teilbandcodierung zu Grunde.
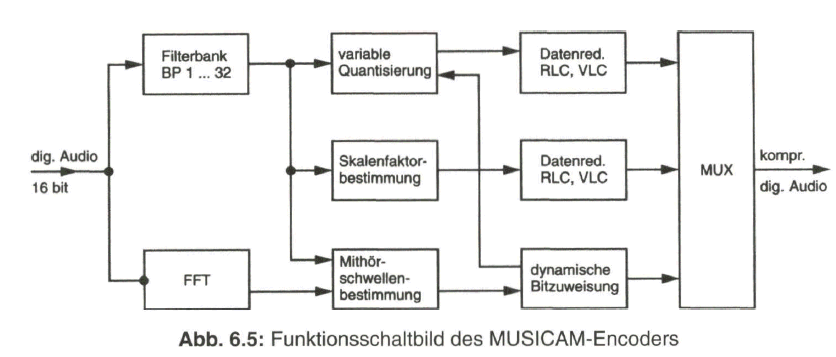
Das psychoakustische Modell ist nur beim Encoder erforderlich. Beim Decoder werden nach Demultiplexen des Datenstroms und Decodieren der Steuerungsanweisungen die übertragenen Teilbandsignale in einer inversen Filterbank wieder zum Summensignal zusammengesetzt. Siehe dazu das vereinfachte Funktionsschaltbild in Bild 6.6
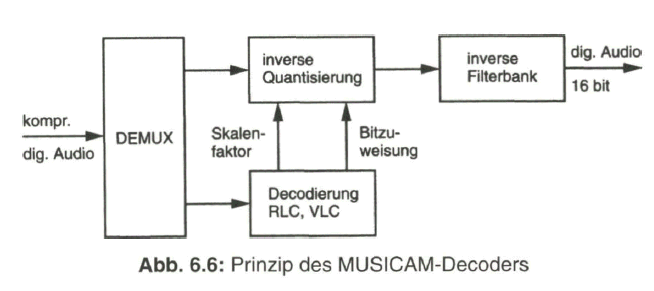
Neben der Teilbandcodierung gibt es die Transformationscodierung, eingebracht in Layer III der MPEG-Zuordnung. Bei der Transformationscodierung kommt an Stelle der Filterbank eine modifizierte Diskrete Cosinus-Transformation (MDCT) zum Einsatz. Diese ermöglicht eine feinere Unterteilung des Audio-Frequenzbereiches und damit eine höhere Irrelevanzreduktion.
6.3 Layers bei den Codierverfahren
Bei der Audiocodierung werden verschiedene Layers, je nach dem Grad der Datenreduktion und dem notwendigen technischen Aufwand, unterschieden. Diese Festlegung ist eigentlich in dem MPEG-Standard enthalten, der im folgenden Abschnitt 7 erläutert wird. Ziel ist in jedem Fall eine hohe Qualität des wiedergegebenen Audiosignals.
Layer I, auch als „Pre-MUSICAM“ bezeichnet, basiert auf dem PASC-Algorithmus (Precision Adaptive Subband Coding), der von Philips für die digitale Audio-Cassette DCC entwickelt wurde. Die Ausgangsbitrate kann mit 14 Werten im Bereich von 32 bis 442 kbit/s pro Audiokanal liegen. Subjektive HiFi-Qualität erfordert 192 kbit/s pro Kanal und damit 384 kbit/s für ein codiertes Stereo-Audiosignal. Der Vorteil des Verfahrens, das mit dem bereits in Abschnitt 6.1 beschriebenen psychoakustischen Modell und fester Codierung der Teilband-Koeffizienten arbeitet, ist die relative Einfachheit von Encoder und Decoder.
Layer II, basiert auf dem MUSICAM-Verfahren, das wie schon erwähnt, für das europäische Digital Audio Broadcasting DAB entwickelt wurde. Für eine vergleichbare Audio-Qualität kommt Layer II mit nur etwa 30 ... 50 % der übertragenen Bitrate von Layer I aus. Die Bitrate kann Werte zwischen 32 ... 192 kbit/s pro Audiokanal annehmen. Subjektive HiFi-Qualität wird erreicht mit 96 kbit/s bzw. 192 kbit/s für das Stereosignal. Die Komplexität von Encoder und Decoder ist nur unwesentlich höher als bei Layer I. Es wird das gleiche psychoakustische Modell mit variabler Codewortlänge in den Teilbändern verwendet.
Layer III, arbeitet mit einem gegenüber Layer I und II geänderten psychoakustischen Modell und einer auf DCT (Diskreter Cosinus-Transformation) basierten Signalanalyse an Stelle der Teilbandcodierung. Die Bitrate kann im Vergleich zu Layer II nochmals um den Faktor 2 abgesenkt werden, aber es steigt auch die Komplexität von Encoder und Decoder. Dieses Verfahren wird auch bei Dolby Digital (AC-3) für den Begleitton beim Kinofilm, bei der DVD und verschiedentlich auch schon beim Digitalen Fernsehen angewendet. AC-3 besagt „Audio Coding Layer 3“.
Layer III ist vor allem für niedrige Bitraten, z. B. für ISDN-Übertragung oder Audio- Files nach dem Internet-Standard MP3, ausgelegt. Der Begriff „MP3“ steht für „MPEG-1 Layer III“ als Datenformat. Ein verbesserter Nachfolger dieses Standards wurde vom FRAUNHOFER-Institut für Integrierte Schaltungen entwickelt und mit AAC (Advanced Audio Coding) benannt.
6.4 Mehrkanal-Codierung
Bei der Verarbeitung von Tonsignalen unterscheidet man zwischen Einzelkanal-Codierung mit
• Single Channel Coding (Monosignale),
• Dual Channel Coding (zweisprachige Monosignale),
• Stereo Coding (Rechts- und Unks-Signale) und
• Joint Stereo Coding,
bei dem die Redundanz zwischen Links- und Rechts-Kanal ausgenutzt wird. Aufgrund der Tatsache, dass die räumliche Ortung bei höheren Frequenzen mehr auf dem Lautstärkeverhältnis beruht als auf der Phasenbeziehung zwischen Links- und Rechts-Signal, genügt es, bei höheren Frequenzen praktisch nur ein Mono-Signal zu übertragen (Irrelevanzreduktion)
und
• Multi Channel Audio Coding (Mehrkanalton) bei Layer II mc und Layer III me, mit fünf bzw. sechs Tonkanälen für Surround Sound. Dabei kann aus der Korrelation von nicht für den räumlichen Höreindruck notwendigen Signalanteilen aus den einzelnen Kanälen eine Irrelevanzreduktion abgeleitet werden, wie dies bei Dolby Digital 5.1 Surround angewendet wird.
Die Anordnung der Lautsprecher zur Wiedergabe eines Stereosignals bzw. eines Surround-Sound-Signals gibt Bild 6.7 wieder. Im Gegensatz zu Dolby Surround (auch bekannt als Pro Logic), das eigentlich nur vier Kanäle aufweist (L, C, R mit voller Bandbreite und Effekt-Kanal mit begrenztem Frequenzbereich von 100 ... 7000 Hz), verfügt bei Dolby Digital 5.1 jeder der fünf Kanäle (L, C, R, LS, RS) über den vollen Frequenzbereich von 20 ... 20000 Hz. Die Bezeichnung „5.1“ weist mit „1“ auf den getrennten Subwoofer-Kanal (Tiefton-Kanal) hin. Durch Datenkompression wird die Datenrate insgesamt auf 384 kbit/s begrenzt.
Für eine Kompatibilität mit den beiden Stereokanälen, z. B. auch in Layer I, wird der Mehrkanalton mit den Hauptkanälen L, C, Front (Left, Center, Right),
mit Anordnung der Lautsprecher vor dem Zuhörer, und LS, RS (Left Surround, Right Surround), mit Anordnung der Lautsprecher hinter dem Zuhörer in einem Coder mit spezieller Matrizierung in fünf Transportkanäle
![]()
aufbereitet, aus denen ein empfangsseitiger Decoder entweder die beiden Stereosignale L oder die fünf Surround-Signale L, C, R und LS, RS rekonstruiert.
Die eigentliche Bedeutung dieser Aufspaltung liegt in der Kompatibilität des MPEG-1-Audiosignals mit dem MPEG-2-Audiosignal, wie aus Bild 6.8 hervorgeht.
6.5 Datenraten bei digitalen Audiosignalen
Nicht komprimierte digitale PCM-Audiosignale (Linearcodierung)

Mit Datenreduktion nach MPEG-1 Audio, mögliche Abtastfrequenz neben 48 kHz auch 44,1 kHz und 32 kHz, mögliche Bitrate 192 kbit/s,... 128 kbit/s, ... 96 kbit/s,... 64 kbit/s,... 32 kbit/s, verbunden mit den Codier-Algorithmen Layer I (typ. 192 kbit/s), Layer II (typ. 128 kbit/s), Layer III (typ. 64 kbit/s, 32 kbit/s) MPEG-2 Audio, kompatible Erweiterung zu MPEG-1 Audio, mit Layer II MC und Layer III MC (Multichannel), wobei MPEG-2 Layer III mit Advanced Audio Coding (AAC) nicht kompatibel mit MPEG-1 ist, mögliche Abtastfrequenzen außer 48, 44,1 und 32 kHz auch 24, 22,05 und 16 kHz, typische Bitraten zwischen 64 kbit/s und 128 kbit/s für einen Tonkanal und 384 kbit/s (möglich, mit n x 8 kbit/s, von 320 bis 896 kbit/s) für Mehrkanalton bei Kinofilmen (Dolby Digital 5.1).
Das MP3-Format erlaubt Datenraten von 8 kbit/s bis zu 320 kbit/s. Ein Stereo-Tonsignal behält subjektiv die CD-Qualität bei einer Bitrate im Bereich von 112 bis 128 kbit/s und ist damit von den meisten Menschen nicht mehr vom Original zu unterscheiden. Annähernd CD-Qualität wird erreicht mit einer Bitrate von 96 kbit/s. Ein Mono-Tonsignal bringt mit einer Bitrate von 32 kbit/s noch ausreichende Hörqualität. Für ein Sprachsignal reichen 8 kbit/s.
7. Video- und Audio-Codierung nach dem MPEG-Standard
7.1 Entwicklung des MPEG-Standards
Nachdem in den achtziger Jahren mit durchwegs beachtlichen Erfolgen bei verschiedenen Institutionen intensiv an Verfahren zur Datenreduktion bei Audio- und Videosignalen gearbeitet wurde, war es naheliegend, über die Internationale Standardisierungs-Organisation ISO (International Standards Organisation) einen weltweit verbindlichen Standard zur Codierung von Audio- und Videosignalen zu schaffen. Dazu wurde vom Joint Technical Committee (JTC) der International Standards Organisation (ISO) und der International Electrotechnical Commission (IEC) eine Arbeitsgruppe aus Experten eingerichtet, die sich zunächst mit der Erarbeitung eines Standards zur Codierung von Standbildern unter Anwendung der DCT zum Zweck der Speicherung und Übertragung befassen sollte. Die Arbeitsgruppe etablierte sich unter dem Begriff Joint Photographie Experts Group, abgekürzt mit JPEG. Das Ergebnis der Arbeitsgespräche, der JPEG-Standard, wurde 1993 als ISO/ IEC 10918 veröffentlicht. Der ursprünglich nur für die Codierung von Standbildern gedachte JPEG-Standard lässt sich prinzipiell auch auf die Codierung von Bewegtbildern anwenden, wenn man diese als eine Folge von Standbildern betrachtet. Ein Interims-Ergebnis, ohne Festlegung auf einen Standard, führte zu dem Begriff Motion-JPEG, ein Verfahren, das aber wegen
• fehlender Standardisierung und daraus resultierenden Problemen bei der Abstimmung zwischen verschiedenen Anwendern und Herstellern, keine Bedeutung erlangte.
• der nur geringen Datenreduktion, bedingt durch die fehlende Ausnutzung der Ähnlichkeit von Teilbildern in zeitlicher Folge und
• nicht vorgesehener Audiocodierung und Multiplexbildung von Video- und Audio-Komponenten
Der nächste Schritt war nun die Erweiterung der Arbeitsgruppe zur Moving Pictures Expert Group, MPEG mit der Aufgabe, einen Algorithmus zur Codierung von bewegten Bildern und dem dazugehörigen Ton zu definieren. Das erste Ergebnis war der MPEG-1-Standard mit dem Titel „Coding of Moving Pictures and Associated Audio for Digital Storage Media up to about 1,5 Mbit/s“, veröffentlicht am 1. August 1993 als ISO/IEC 11172-1 bis -3 und ausgerichtet auf Anwendungen bei Multimedia mit Computer und die Speicherung von komprimierten Videosignalen auf eine herkömmliche CD mit einer maximalen Datenrate von etwa 1,5 Mbit/s.
Um bei dieser niedrigen Datenrate noch annehmbare Bildqualität zu erreichen, wurde zunächst von gewissen Einschränkungen ausgegangen: Rasterauflösung in 352 x 288 Bildpunkte (aus dem SIF-Format mit 360 x 288 Bildpunkten durch Weglassen von jeweils 4 Bildpunkten am linken und rechten Bildrand, wegen der Unterteilung in Makroblöcke mit 16 x 16 Bildpunkten) und einer Bildwiederholfrequenz von < 30 Hz bei progressiver Abtastung. Die Datenreduktion beim Audiosignal erfolgt nach dem MUSICAM-Verfahren mit Layer l [8, 31]. Schon bald versuchte man, den MPEG-1-Standard auf das ITU-R-601-Format mit einer Rasterauflösung von 720 x 576 (bzw. 720 x 480 beim US-Standard) Bildpunkten auszuweiten. Es führte zu einer „MPEG-1 +“- und weiter zu einer „MPEG- 1,5“-Version. Aber es war kein Zeilensprungverfahren möglich.
Deshalb kam es zur Erarbeitung des MPEG-2-Standards mit dem Titel „Generic Coding of Moving Pictures and Associated Audio“, der von vorneherein für die Übertragung von Fernsehbildern mit progressiver oder Zeilensprung-Abtastung ausgerichtet war und die Codierung der vollen Rasterauflösung nach ITU-R BT.601 mit 4:2:2- oder 4:2:0-Chrominanzauflösung zulässt. Außerdem waren verschiedene Qualitätsstufen vorgesehen. Das Ergebnis lag zum Jahresende 1994 vor. Ein ursprünglich vorgesehener MPEG-3-Standard für hochauflösendes Fernsehen (HDTV) konnte entfallen, weil der MPEG-2-Standard mit seinen verschiedenen Qualitätsebenen, beschrieben durch „Levels“ und „Profiles“, neben SDTV auch HDTV abdeckt.
Dagegen wurde ein MPEG-4-Standard geschaffen, der für niedrige Datenraten bis 64 kbit/s und Anwendung bei Computer-Animation, mobile Bildkommunikation und Videokonferenzen gedacht war, sowie für Zuspielungen im Internet, Zukünftig wird die MPEG-4-Spezifikation mit der Einbeziehung des H.264 Advanced Video Code (AVC) bei der Codierung von HDTV-Signalen Bedeutung erlangen.
7.2 Der MPEG-2-Standard
Auf Grund der Anforderungen für den „Fernseh-Standard“, wie Fernsehsignalübertragung über Satelliten- und Kabelkanäle sowie terrestrische Netze, über ATM- und Computernetzwerke, Magnetband- und Disc-Aufzeichnung usw. wurden von der MPEG-Arbeitsgruppe geeignete Codierungswerkzeuge, so genannte „tools“ geschaffen, die an Stelle von festen Parametersätzen eine weitgehende Flexibilität gewährleisten. Mit diesen Codier-Werkzeugen werden komprimierte Video- und Audio-Datenströme generiert, die so genannten Elementary Bitstreams. Diese „elementaren Datenströme“ werden in Pakete unterteilt und im Zeitmultiplex nach den System-Vorgaben zusammengefasst. Ergänzend dazu werden zur Identifikation und Synchronisation notwendige Zeitmarken in den Datenstrom eingefügt. Bild 7.1 gibt dazu den prinzipiellen Ablauf wieder.
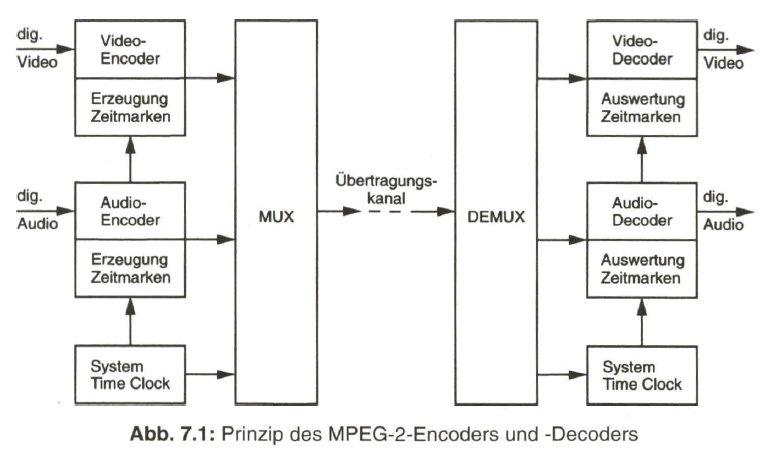
Von den Normungsgremien ISO und IEC wurde 1994 der MPEG-2-Standard ISO/IEC 13818 Generic Coding of Moving Pictures and Associated Audio mit den drei Teilen
ISO/IEC 13818-1 Systems
ISO/IEC 13818-2 Video
ISO/IEC 13818-3 Audio
spezifiziert, vergleichbar mit der bereits für den MPEG-1-Standard erfolgten Spezifizierung unter ISO/IEC 11172-1,-2,-3.
7.2.1 MPEG-2, Teil 1: Systems
Der MPEG-2-Systems-Teil baut auf den Festlegungen in MPEG-1-Systems auf und kann als dessen Erweiterung betrachtet werden, die im Wesentlichen zu der dualen Struktur des Multiplex-Datenstroms mit Programm-Datenstrom und Transport-Datenstrom führt. Der Systems-Standard definiert nicht die genauen Coder-Prozeduren. Vielmehr werden syntaktische, die Zusammenstellung betreffende und semantische, die Bedeutung betreffende Regeln für die Generierung der Bitströme festgelegt. Damit kann ein Decoder, dem diese Regeln bekannt sind, über geeignete Funktionseinheiten den Bitstrom richtig interpretieren. Die Syntax des Datenstroms beschreibt eine Pack-Layer und eine Packet Structure, mit deren Hilfe die komprimierten Video- und Audiodaten im Multiplex geordnet werden. Jedem Paket vorangehend werden Header- und Descriptor-Daten übertragen. Video- und Audio-Information werden zusammen mit ihren den Decodierzeitpunkt bestimmenden Decoding Time Stamps (DTS) und den für den Wiedergabezeitpunkt verantwortlichen Presentation Time Stamps (PTS) in aufeinanderfolgende Pakete eingebracht. Eine Folge von Paketen wird zu so genannten Packs mit Startcode und generellen Informationen über den Bitstrom, sowie der wichtigen System Clock Reference (SCR) als absoluter Zeitbasis zusammengefasst. Sowohl bei MPEG-1 als auch bei MPEG-2 liegt eine einzige Zeitbasis als Referenz für Codierung und Decodierung vor. Der System Time Clock (STC) weist bei MPEG-1 die Frequenz von 90 kHz auf. Bei MPEG-2 wurde die System Clock Frequency auf 27 MHz erhöht, um eine größere Genauigkeit der Zeitbasis sicherzustellen. Alle Codier-, Decodier- und Wiedergabezeitpunkte werden durch die DTS- und PTS-Marken bestimmt, die man durch Abtastung des System Time Clock (STC) während des Codiervorgangs erhält. Nähere Erläuterungen dazu folgen im Abschnitt 8.
7.2.2 MPEG-2, Teil 2: Video
Der MPEG-2-Standard wurde geschaffen, um komprimierte Videobilder für verschiedene Qualitätsebenen, von Low Definition Television (LDTV) über Standard Definition Television (SDTV) bis zu High Definition Television (HDTV), zu speichern oder zu übertragen. Um einerseits ein Maximum von Austauschbarkeit zu ermöglichen und andererseits nicht zu hohen Aufwand bei der Codierung und Decodierung auf niedrigerer Qualitätsebene zu bewirken, wurde bei MPEG-2 eine Konfiguration mit Profiles und Levels konzipiert und in den Standard aufgenommen. Die Profiles geben indirekt die Codierungstechnik an, beginnend mit der Chrominanzauflösung und ergänzend mit einer möglichen Skalierbarkeit. Das „einfachste“ Profil lässt darüber hinaus eine vereinfachte Prädiktion beim Hybrid- Coder zu. Es wird unterschieden in
• Simple Profile (SP), basierend auf 4:2:0-Abtastraster, keine bidirektionale Prädiktion (Erklärung folgt),
• Main Profile (MP), basierend auf 4:2:0-Abtastraster, keine Skalierbarkeit,
• SNR Scalable Profile (SNRP), entsprechend Main Profile mit SNR-Skalierbarkeit,
• Spatial Scalable Profile (SSP), entsprechend Main Profile mit Auflösungs-Skalierbarkeit und
• High Profile (HP), basierend auf 4:2:2-Abtastraster und gesamte Funktionalität mit Skalierbarkeit.
Die spatiale Skalierbarkeit kann zum Beispiel verwendet werden, um aus einem HDTV-Signal einen HDTV- und einen SDTV-Datenstrom zu erzeugen. Mit der SNR-Skalierbarkeit können zwei Datenströme erzeugt werden, die bei gleicher örtlicher Auflösung einer unterschiedlichen Quantisierung zuzuordnen sind. Damit besteht die Möglichkeit, bei ungünstigen Empfangsbedingungen nur den robusteren Anteil, aber mit gröberer Quantisierung auszuwerten [33]. Die Levels beziehen sich auf die Werte der Hauptparameter wie Bildformat, Anzahl der Pixel horizontal und vertikal und maximale Bitrate, die bestimmend ist für die Kapazität des Eingangs-Buffers beim Decoder. Die Levels werden zugeordnet wie in Tabelle 7.1 angegeben.
Tab. 7.1: Levels beim MPEG-2-Standard
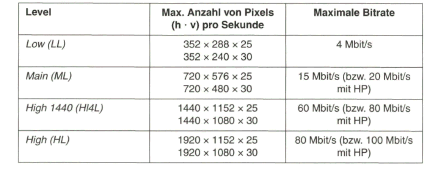
Der Low Level (LL) bezieht sich auf SIF-Auflösung, der Main Level (ML) berücksichtigt die volle Auflösung bei SDTV nach ITU-R 601.
Bei HDTV wurde unterschieden zwischen High 1440 Level (H14L) mit 1440 Bildpunkten pro Zeile, gedacht mit 25 bzw. 30 Zeilensprung-Bilder pro Sekunde, und der vollen Breitbildauflösung mit 1920 Bildpunkten pro Zeile beim High Level (HL), ggf. mit 50 bzw. 60 progressiv abgetasteten Bildern pro Sekunde, um eine stufenweise Einführung von HDTV zu ermöglichen.
Das Pixel-mal-Bilder/s-Produkt, das indirekt die Buffer-Größe zum Ausdruck bringt, ist für den europäischen und den amerikanischen Standard entweder vollkommen oder annähernd gleich, wie nachfolgende Berechnung beweist.

Die möglichen und bisher als notwendig und sinnvoll erachteten Kombinationen von Levels und Profiles zeigt Tabelle 7.2 auf. Die Verbindung von Profile mit Level erfolgt mit dem „at“-Zeichen @.
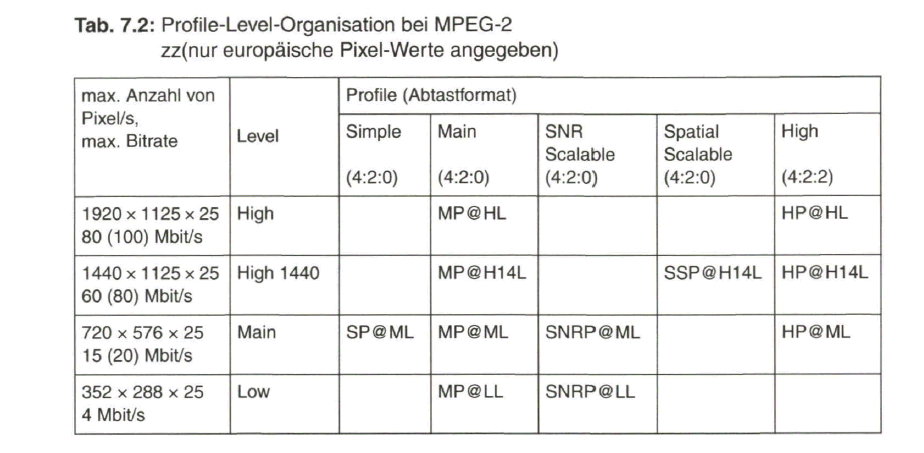
Für die Fernseh-Produktionstechnik im Studio hat sich mittlerweile ein eigener Standard mit der Bezeichnung

und einer Bitrate von 50 Mbit/s als sinnvoll erwiesen. Es handelt sich um ein „modifiziertes“ Main Profile mit 4:2:2-Abtastraster, weil eine Bitrate von 50 Mbit/s nach der Profile-Level-Organisation mit der HP@ML-Kombination nicht zugelassen ist. Die hohe Bitrate von 50 Mbit/s ist dadurch bedingt, dass für Studiobearbeitung, insbesondere wegen der Vornahme von Schnitten, die Länge der Group of Pictures (GOP) nur ein oder zwei Bilder betragen darf (GOP siehe später).
Die praktische Ausnutzung der nach MPEG-2 definierten Level beim Rundfunk-Fernsehen beschränkt sich in Europa zurzeit nur auf den Main Level beim Standard-Fernsehen mit 625 Zeilen (576 aktive Zeilen) und 50 Halbbildern/s, d.h. mit Zeilensprung. HDTV im High Level mit 1250 Zeilen (1080 aktive Zeilen) mit Zeilensprung oder mit progressiver Abtastung ist für zukünftige Anwendungen vorgesehen. Dahingegen wird in den USA gemäß den vom FCC (Federal Communications Commission) schon Mitte 1996 festgelegten 18 Parameter-Kombinationen sowohl im Main Level als auch im High 1440 und High Level neben dem Standard-Fernsehen auch hochauflösendes Fernsehen von verschiedenen Rundfunkanstalten bereits angeboten.
Verschiedene Interessen wie Rundfunk, Computer-Industrie und Kinofilm sind zu berücksichtigen. Die traditionellen Fernsehempfänger-Hersteller in den USA sind bereit, alle 18 Formate zu implementieren, wogegen die Computer-Industrie, vertreten durch das Digital-TV-Team mit Compaq, Microsoft und Intel, eine praktikable Untermenge des von der FCC bestätigten ATSC-Vorschlags (Advanced Television Systems Committee) befürwortet. Dabei steht vor allem die progressive Abtastung im Vordergrund. Tabelle 7.3 gibt die Situation nach dem Stand von 1997 wieder, mit den vom Digital-TV-Team bevorzugten Formaten in Fettdruck.

Die Video-Codiertechniken von MPEG-1, die auf der so genannten Hybridcodierung, der Kombination von DPCM mit Bewegungskompensation und DCT basieren, können auch für höhere Bitraten nun bei MPEG-2 angewendet werden. Später wird an Hand eines Blockschaltbildes der Funktionsablauf in dem MPEG-2-Video-Encoder erläutert. Die Codierung wird auf verschiedenen Ebenen vorgenommen, um dem Datenstrom eine hierarchische Struktur zu geben. Damit wird der Decodierprozess vereinfacht. Der MPEG-2-Video-Standard definiert für die Codierungseinheiten so genannte Layers beim Videodatenstrom.
Ihre Kennzeichnung erfolgt über spezielle Codeworte. Die Layers beim MPEG-2-Video-Datenstrom werden, von der obersten Stufe ausgehend, bezeichnet mit
• Sequence Layer (Video-Reihenfolge),
• Group of Pictures Layer (Gruppe von Bildern),
• Picture Layer (Bild),
• Slice Layer (Scheibe),
• Macrobiock Layer (Makroblock) und
• Block Layer (Block).
Bild 7.2 gibt die Zuordnung der Layers innerhalb einer Video-Sequenz grafisch wieder.
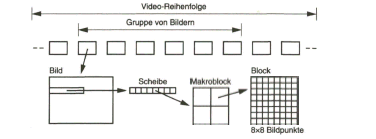
Abb. 7.2: Layers beim MPEG-2-Video-Datenstrom
Die Bedeutung der Layers ist folgende:
• Die Sequence Layer als oberste Schicht definiert die Basis-Parameter für die „Video-Sequenz“, z.B. ein Programmbeitrag. Zu den Basis-Parametern gehören das Abtastraster für Chrominanz (4:2:2 oder 4:2:0), Anzahl der horizontalen und vertikalen Bildpunkte, Bildpunkt-Seitenverhältnis vertikal-zu-horizontal (0,6735 bis 1,2015), Bitrate, minimal erforderliche Kapazität des Eingangsbuffers beim Decoder, maximale Größe der DCT-Koeffizienten (±255 oder ±2047), Quantisierer-Matrix und weitere Angaben.
• Die Group of Pictures Layer (GOP) beschreibt die Prädiktion innerhalb einer Gruppe von Teilbildern (geschlossene GOP) bzw. gibt einen Hinweis, wenn Bewegungsvektoren auf Bilder außerhalb dieser GOP zeigen. Es wird die Zusammensetzung dieser Gruppe von Teilbildern beschrieben aus.
• intracodierten Bildern (I-Pictures), die ganz ohne Bezug auf andere Teilbilder im Vollbild oder im Halbbild codiert werden und die notwendig sind für den Neuzugriff auf eine Bildsequenz,einseitig vorhergesagten Bildern (P-Pictures), die mit dem Verfahren der Bewegungskompensation über Bezug auf ein vorangehendes intracodiertes oder ein bereits einseitig vorhergesagtes Bild codiert werden und Stützpunkte für die Rekonstruktion der kompletten Bildsequenz bilden.
• zweiseitig, bidirektional, vorhergesagten Bildern (B-Pictures), die über Bezug auf ein vorangehendes und ein folgendes Teilbild als eine bidirektionale Interpolation codiert werden.
Um stets einen Neustart des Decodiervorgangs zu gewährleisten, müssen I-Bilder mindestens etwa alle 0,5 s übertragen werden. P- und B-Bilder sind nach einer definierten Reihenfolge zwischen den I-Bildern eingeordnet. Siehe dazu Bild 7.3. I-Bilder weisen die geringste Datenreduktion auf, B-Bilder sind mit der höchsten Datenreduktion verbunden.
In der Picture Layer ist die Information über die Position des Bildes innerhalb der GOP und die Codierung des einzelnen Teilbildes als I-, P- oder B-Bild enthalten und außerdem eine Angabe, ob es sich um ein Vollbild oder um das erste oder zweite Halbbild handelt. Der Video-Encoder kann für jedes Teilbild entscheiden, ob Vollbild- oder halbbildbasierte Prädiktion zum besseren Ergebnis führt.
Die Slice Layer dient zur Angabe einer expliziten Position innerhalb eines Bildes und ist für die Resynchronisation notwendig. Eine „Scheibe“ (Slice) wird aus einer Folge von Makroblöcken gebildet. Die Gesamtheit der Slices überdeckt das gesamte Teilbild. Ein Slice kann theoretisch von einem Makroblock bis zum ganzen Bild reichen. Die Anzahl der Makroblöcke in einer Slice wird in der Slice Layer angegeben. Die Macroblock Layer ist die Basis für die bewegungskompensierte Prädiktion. Es werden darin die Bewegungsvektoren übertragen. Ein Makroblock weist üblicherweise 16x16 Pixel beim Luminanzsignal auf. In der Block Layer finden sich die Koeffizienten aus den DCT-transformierten 8x8-Pixel-Blöcken. Bei I-Bildern ist es die Information aus dem Originalbild, bei P- und B-Bildern aus dem Differenzbild.
Innerhalb einer Group of Pictures kann die Anzahl und Reihenfolge aufeinanderfolgender I-, P- und B-Bilder für verschiedene Anwendungen unterschiedlich gewählt werden. Tabelle 7.4 gibt hierzu einige typische Beispiele. Der Abstand zwischen aufeinanderfolgenden I-Bildern wird mit dem Parameter N angegeben, der Abstand der P-Bilder durch den Parameter M. Die Tabelle gibt die Reihenfolge am Eingang des Coders (Cod) und die Reihenfolge der Übertragung (Übtr) an, weil eine Umsortierung notwendig wird, wie später an Hand von Bild 7.4 erläutert wird.
Tab. 7.4: Beispiele verschiedener Kombinationen von I-, P- und B-Bildern innerhalb einer Group of Pictures
Bei Anwendungen mit niedriger Bitrate, wo also eine hohe Datenkompression notwendig ist, werden umfangreiche Kompressionsmöglichkeiten benötigt. Vielfach wird deshalb mit den Parametern ![]() und
und ![]() gearbeitet. Bild 7.3 zeigt die Teilbildfolge innerhalb der Group of Pictures für diese Parameter-Kombination und die dabei ablaufende Prädiktion.
gearbeitet. Bild 7.3 zeigt die Teilbildfolge innerhalb der Group of Pictures für diese Parameter-Kombination und die dabei ablaufende Prädiktion.
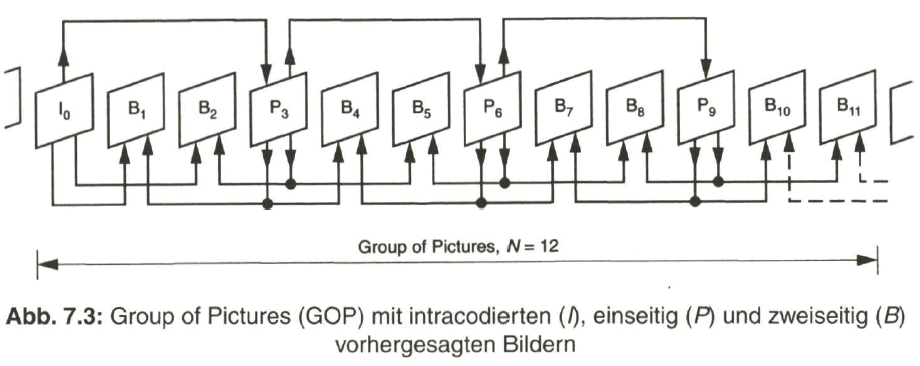
Der Parameter ![]() erlaubt jedoch nur in Abständen von 480 ms den Zugriff auf intracodierte Bilder. Das kann zu Problemen beim Editieren von Videobildern führen. Für eine Nachbearbeitung ist deshalb diese Kombination nicht geeignet. Eine Folge von nur intracodierten Bildern wäre hier am besten, liefert aber die geringste Datenreduktion. Siehe dazu auch nachfolgendes Zahlenbeispiel. Datenreduktion vom Studio-Quellensignal bis zum MPEG-2-Signal am Beispiel einer Group of Pictures, mit
erlaubt jedoch nur in Abständen von 480 ms den Zugriff auf intracodierte Bilder. Das kann zu Problemen beim Editieren von Videobildern führen. Für eine Nachbearbeitung ist deshalb diese Kombination nicht geeignet. Eine Folge von nur intracodierten Bildern wäre hier am besten, liefert aber die geringste Datenreduktion. Siehe dazu auch nachfolgendes Zahlenbeispiel. Datenreduktion vom Studio-Quellensignal bis zum MPEG-2-Signal am Beispiel einer Group of Pictures, mit ![]() und
und ![]()
Ausgangssituation: Netto-Bitrate des aktiven Videoanteils aus dem DSC-270Mbit/s-Signal 207,36 Mbit/s bei 10bit-Codierung bzw. 165,888 Mbit/s bei 8bit-Codierung
Nächster Schritt: Übergang vom 4:2:2-Abtastraster auf das 4:2:0-Abtastraster
Berechnung der Datenmenge eines Teilbildes:
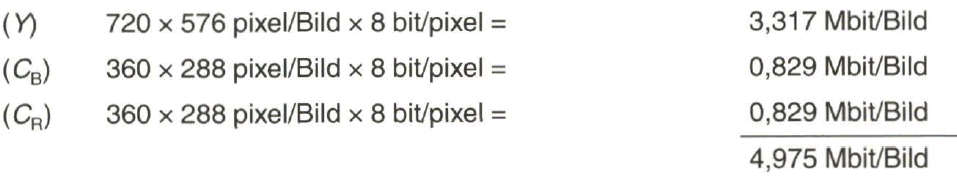
Mit 25 Bildern/s ergibt das eine Bitrate von 124,4 Mbit/s. Nach Datenreduktion über Differenzbildübertragung (nur bei P- und B-Bildern) und DCT mit nachfolgender RLC und VLC erhält man aus der statistischen Auswertung von Bildmaterial

Damit berechnet sich die Datenmenge in einer GOP, mit l-B-B-P-B-B-P-B-B-P-B-B
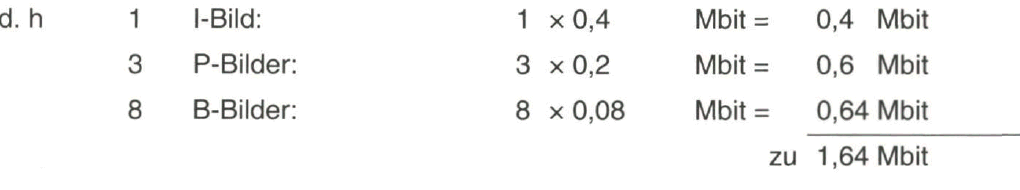
entsprechend einer mittleren Datenrate über 12 Teilbilder (in 12 x 40 ms = 480 ms) von 1,64 Mbit/0,48 s = 3,42 Mbit/s.
Wie in Tabelle 7.4 schon erwähnt, werden die Teilbilder aus der GOP zur Übertragung umsortiert. Zur Rekonstruktion von P- oder B-Bildern beim Decoder muss die übertragene Differenz zwischen P- und I-Bild bzw. zwischen B-Bild und I- sowie P-Bild wieder zu dem I-Bild bzw. dem Mittelwert aus I- und P-Bild addiert werden. Dazu ist es notwendig, beim Decoder das I- und das P-Bild zu speichern. Die gewählte Umsortierung bei der Übertragung erfordert nur beim Encoder vier Teilbildspeicher (Sp) und kommt aber beim Decoder mit zwei Teilbildspeichern (Sp) aus. Siehe dazu Bild 7.4.
Dem Decoder wird mit dem Picture Header in der Picture-Layer die jeweilige Art des Bildes, ob I-, P- oder B-Bild mitgeteilt. In den I-Bildern werden alle Makroblocke ohne Prädiktion codiert, das heißt es wird das Originalbild übertragen. Dagegen wird bei den P- und B-Bildern die Art der Codierung, ob über eine Prädiktion oder „Intracodiert“, für jeden Makroblock neu bestimmt, abhängig von der „Qualität“ der Prädiktion. Somit können auch verschiedene Makroblöcke in P- und B-Bildern intracodiert werden.
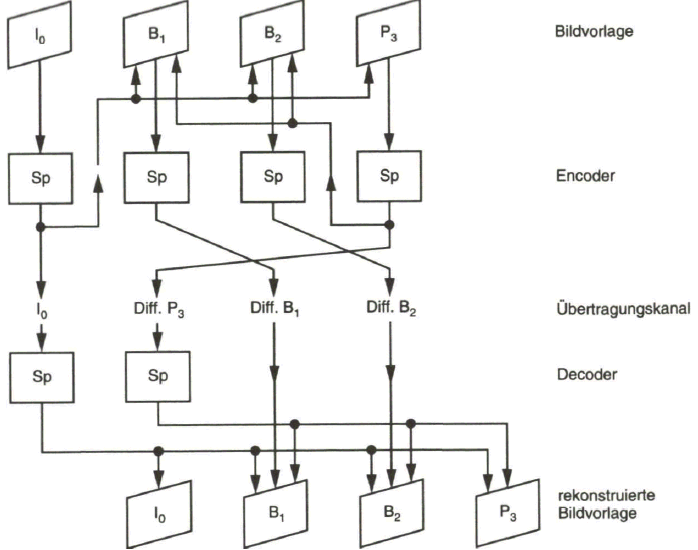
Abb. 7.4: Verarbeitung und Übertragung der Teilbilder innerhalb einer Group of Pictures
Wie nachfolgend in Bild 7.6 gezeigt, erfolgt die Regelung einer konstanten Datenrate am Ausgang des Hybrid-Encoders, mit Bewegungskompensation und DCT, durch eine gesteuerte Rückkopplung auf die Quantisierungsstufe. Man vermeidet so, dass bei vielen hohen Frequenzanteilen oder bei einem Versagen der Prädiktion auf Grund zu starker Änderungen im Bild der Ausgangsbuffer beim Encoder nicht mehr aufnahmefähig ist. In diesem Fall wird die Quantisierungsstufenhöhe vergrößert, was allerdings eventuell auch die Bildqualität kurzzeitig verschlechtert. Die Beeinflussung der Quantisierung erfolgt über einen von Makroblock zu Makroblock variablen Quantisierungsfaktor, der von der Buffer-Steuerung eingestellt werden kann. Abhängig von der Quantisierung fließen damit mehr oder weniger Daten in den Ausgangs-Buffer.
Reicht die Einstellung des Quantisierungsfaktors in den Grenzen von 1 bis 31 nicht aus, um einen Überlauf des Buffers zu verhindern, so treten so genannte „skipped macroblocks“ auf, d.h. diese Makroblöcke werden nicht codiert und durch entsprechende Makroblöcke des vorangehenden Bildes ersetzt. Mit der Festlegung der Makroblöcke als Grundeinheit für die Bewegungsschätzung und Kompensation bietet sich die Möglichkeit, denselben Bewegungsvektor sowohl für das Luminanzsignal, mit dem die Bewegungsschätzung vorgenommen wird, als auch für die Chrominanzsignale zu verwende. Je nach dem Abtastraster ergibt sich eine entsprechende Makroblock-Block- Zuordnung, wobei stets der gesamte Makroblock-Bildausschnitt von den Blöcken für das Luminanzsignal ![]() und die beiden Chrominanzsignale
und die beiden Chrominanzsignale ![]() und
und ![]() abgedeckt wird (Bild 7.5).
abgedeckt wird (Bild 7.5).
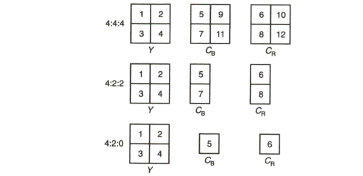
Abb. 7.5: Makroblock-Block-Zuordnung beim 4:4:4-, 4:2:2-und 4:2:0-Abtastraster
Die Makroblöcke und Blöcke sind jetzt nur indirekt „zeilengebunden”, weil eine Anzahl von 16 bzw. 8 übereinander liegenden Bildpunkten aus 16 bzw. 8 aufeinanderfolgen Zeilen des Vollbildes für die Makroblock- bzw. Blockbildung herangezogen werden.
Bei dem 4:4:4-Abtastraster bilden jeweils vier Blöcke des ![]() -,
-, ![]() - bzw.
- bzw. ![]() - Signals einen Makroblock. Das ergibt bei einem SDTV-Signal mit 720 Bildpunkten pro aktive Zeile und 576 aktiven Zeilen, aus
- Signals einen Makroblock. Das ergibt bei einem SDTV-Signal mit 720 Bildpunkten pro aktive Zeile und 576 aktiven Zeilen, aus
720:16 = 45 und 576:16 = 36,
sowohl für das ![]() Signal als auch für die Chrominanzsignale
Signal als auch für die Chrominanzsignale ![]() - und
- und ![]() - eine Anzahl von
- eine Anzahl von
45 x 36 = 1620 Makroblöcke pro Bild
und entsprechend
90 x 72 = 6480 Blöcke pro Bild.
Bezogen auf die geometrische Breite des sichtbaren Fernsehbildes mit z.B. 52 cm, bei einer Diagonale von 65 cm, würden auf einen Makroblock etwa 1,15 cm entfallen. Den vier Blöcken des Signals beim 4:2:2-Abtastraster werden jeweils zwei Blöcke des ![]() - bzw.
- bzw. ![]() - Signals mit nun „breiteren” Pixeln zugeordnet, weil ja nur über zwei nebeneinander liegende Original-Pixel ein Chrominanz-Abtastwert gewonnen wird. Beim 4:2:0-Abtastraster schließlich wird der Bildbereich eines Makroblocks für das Y-Signal mit 16 x 16 Pixel durch einen gleich großen Bereich für jeweils einen Makroblock oder auch Block mit 8 x 8 nun „größeren”, aber wieder quadratischen Pixeln für das CB- bzw. CR-Signal abgedeckt. Zusammenfassend gibt nun Bild 7.6 das Funktionsschema eines MPEG-2- Video-Encoders wieder. Es zeigt die Verarbeitung beim Luminanzsignal. Die parallele Verarbeitung der beiden Chrominanzsignale kommt ohne die Bewegungsschätzung aus, wie oben erläutert.
- Signals mit nun „breiteren” Pixeln zugeordnet, weil ja nur über zwei nebeneinander liegende Original-Pixel ein Chrominanz-Abtastwert gewonnen wird. Beim 4:2:0-Abtastraster schließlich wird der Bildbereich eines Makroblocks für das Y-Signal mit 16 x 16 Pixel durch einen gleich großen Bereich für jeweils einen Makroblock oder auch Block mit 8 x 8 nun „größeren”, aber wieder quadratischen Pixeln für das CB- bzw. CR-Signal abgedeckt. Zusammenfassend gibt nun Bild 7.6 das Funktionsschema eines MPEG-2- Video-Encoders wieder. Es zeigt die Verarbeitung beim Luminanzsignal. Die parallele Verarbeitung der beiden Chrominanzsignale kommt ohne die Bewegungsschätzung aus, wie oben erläutert.
Das Eingangssignal aus dem Videoanteil des digitalen Studiosignals wird entweder im 4:2:2-Abtastraster übernommen (High Profile) oder durch Filterung und Dezimation beim Chrominanzanteil auf das 4:2:0-Abtastraster gebracht (Main Profile). Es folgt die Makroblock- und Block-Zuordnung der Pixel. Dazu müssen die Pixel aus 16 bzw. 8 Zeilen in einen Speicher übernommen werden.
Bei intracodierten Bildern (I-Bilder) wird das Signal dann blockweise der DCT zugeführt. Nach Quantisierung und Rundung der DCT-Koeffizienten werden diese im Zick-Zack-Verfahren ausgelesen und über eine Lauflängencodierung (RLC) und Variable-Längen-Codierung (VLC) einem Multiplexer zugeführt, der charakteristische Größen aus der Sequence Layer und der Group of Picture Layer einbringt. Vom Ausgangsbuffer aus erfolgt wiederum die Steuerung des Quantisierungsfaktors.
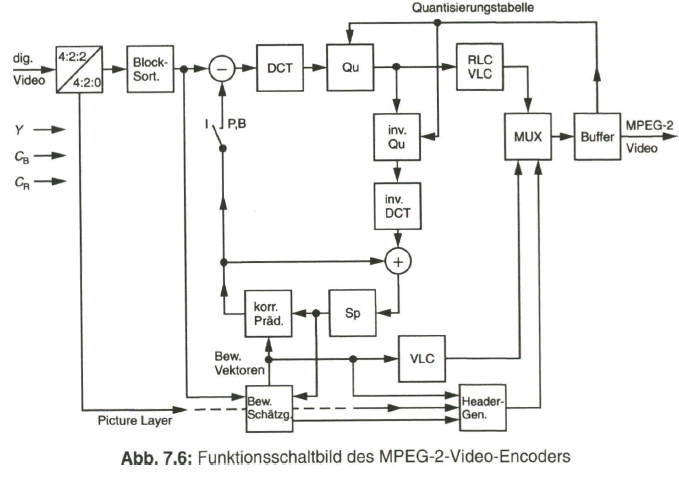
Bei prädizierten Bildern, ob einseitig prädiziert (P-Bilder) oder zweiseitig prädiziert (B-Bilder), gelangt das Differenzbild zur DCT. Dieses erhält man auf Makroblock-Ebene aus dem Vergleich des aktuell anliegenden Bildes mit der Prädiktion von dem vorangehenden Bild, das mit den aus der Bewegungsschätzung ermittelten Bewegungsvektoren in den Makroblökken so verschoben wird, dass es dem aktuellen Bild möglichst gleich kommt. Die Prädiktion baut sich aus dem gespeicherten I- oder P-Bild und der über inverse DCT und inverse Quantisierung zurückgewonnenen Differenz auf. Die Daten über die Art der Prädiktion und die Bewegungsvektoren werden nach einer variablen Längen-Codierung dem Multiplexer zugeführt und in den Ausgangsdatenstrom eingefügt.
Der Video-Encoder entscheidet über die Vorgabe der I-, P- oder B-Bilder hinaus abhängig vom aktuellen Bildinhalt, ob ein Makroblock in einem P- oder B-Bild
• intraframe codiert wird, also komplett neu mittels DCT,
• differenz-codiert wird oder
• übersprungen wird {skipped), wenn es keine Differenz gibt, und ob die Codierung
• vom Vollbild (frame encoded) oder
• von den Halbbildern aus erfolgt.
Bei der Vollbild-Codierung kann zwar die Bildqualität etwas leiden, aber es kommt zu einer besseren Korrelation zwischen den aufeinanderfolgenden Zeilen und die Datenreduktion ist höher als bei der Halbbild-Codierung, die aber wiederum eine bessere Bildqualität ermöglicht.
Eine Vorgabe bei der Festlegung des MPEG-2-Standards war auch, dass der Decoder möglichst einfach zu realisieren sein sollte. Dies zeigt sich u. a. im Wegfall der aufwändigen Bewegungsschätzung zur Bestimmung der Bewegungsvektoren, weil diese ja vom Encoder her übertragen werden. Ein Funktionsschema des MPEG-2-Video-Decoders gibt Bild 7.7 wieder.
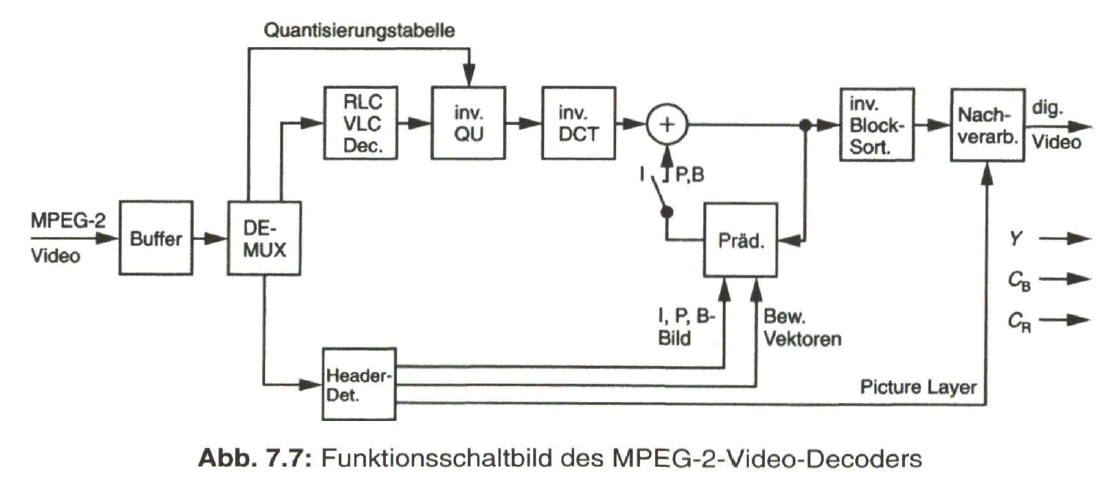
Im Decoder laufen prinzipiell die umgekehrten Vorgänge wie im Encoder ab. Mit konstanter Bitrate wird der Datenstrom dem Eingangsbuffer zugeführt und gelangt von dort zum Demultiplexer. Ein Header-Detektor wertet zunächst die Daten in der Sequence Layer aus. Die Verarbeitung der weiteren Daten wird nach Decodierung der Lauflängencodierung und variablen Längencodierung übereine Funktionssteuerung in den einzelnen Stufen vorgenommen. Zu berücksichtigen ist die in der Quantisierungstabelle übertragene aktuelle Situation bei der inversen DCT. Es folgt die Rücksortierung von den Blöcken und Makroblöcken in das zeilenorientierte Ausgangsbild. Dieses setzt sich aus den übertragenen I-Bildern und den mit der Prädiktion zusammengefassten Differenzbildern zur Rekonstruktion der P- und B-Bilder zusammen. Am Ausgang stehen wieder die Komponentensignale ![]()
![]() und
und ![]() zur Verfügung.
zur Verfügung.
7.2.3 MPEG-2, Teil 3: Audio
Der MPEG-2-Audio-Standard übernimmt im Wesentlichen die Vorgaben von MPEG-1 -Audio mit der Unterteilung in Layer I, II und III. Die Layer sind abwärtskompatibel organisiert, so dass ein Layer-Ill-Decoder auch den Layer-Il- und Layer-I-Datenstrom decodieren kann. Gegenüber MPEG-1 wurde MPEG-2-Audio auf Mehrkanal- und Surround-Codierung erweitert, und zwar in einer rückwärts- und vorwärtskompatiblen Weise, was bedeutet, dass ein MPEG-1-Audio-Decoder die Stereoinformation eines MPEG- 2-Audio-Datenstroms decodieren kann. Umgekehrt kann ein MPEG-2-Audio- Decoder die im MPEG-1-Datenstrom enthaltenen Mono- und Stereo-Audiosignale wiedergeben. Siehe dazu auch Bild 6.8.
Die Mehrkanal-Erweiterung ist wegen der höheren Gesamtdatenrate auf die Layer II und III beschränkt, wie aus Tabelle 7.5 zu ersehen ist. Die Mehrkanal-Codierung erstreckt sich über die beiden Stereokanäle L und R, den Mitten-Front-Kanal C und zwei Raumklang-Kanäle LS und RS. Zusätzlich kann ein Effekt-Kanal codiert werden.

MPEG-2-Audio sieht auch noch zusätzliche Abtastfrequenzen von 16 kHz, 22,05 kHz und 24 kHz für die Codierung mit sehr niedrigen Bitraten vor. Neben der von MPEG-1-Audio übernommenen Teilbandcodierung wurde bei MPEG-2 das Verfahren „Advanced Audio Coding (AAC)“ in den Standard ISO/IEC 13818-7 aufgenommen. Typische Datenraten für ein Stereo-Audiosignal liegen bei MPEG-2 zwischen 128 und 256 kbit/s. Die Tendenz geht jedoch in Richtung „Surround Sound”, besonders bei der Übertragung von Kinofilmen. Der Mehrkanalton bei Kinofilmen (Movie Soundtrack) erfordert Datenraten zwischen 320 und 640 kbit/s. MPEG-2 definiert hierfür die „Multichannel-Version” mit fünf Audiokanälen bei voller Bandbreite (20 Hz bis 20 kHz) und einem tieffrequenten Effektkanal (etwa 30 bis 120 Hz). Dieser wird auch als LFE Channel (Low Frequency Enhancement Channel) oder Subwoofer Channel bezeichnet.
In diesem Zusammenhang wird auch der Begriff Dolby Digital 5.1 verwendet (siehe dazu auch Abschnitt 6.4). Den fünf hochwertigen Audiokanälen ist ein schmalbandiger Effektkanal zugeordnet, der auch nur etwa 1/10 (.1 in englischer Schreibweise) der Datenrate eines breitbandigen Kanals erfordert. Des Weiteren können bei MPEG-2-Audio, Layer II noch bis zu sieben Sprachkanäle (Mehrsprachen-Ton, Kommentare oder Telekonferenz) mit wählbaren Abtastfrequenzen übertragen werden.
7.3 Weitere MPEG-Standards: MPEG-4, MPEG-7, MPEG-21
Die Festlegung des MPEG-4-Standards stand zunächst unter dem Aspekt von sehr niedrigen Datenraten der komprimierten Video- und Audiosignale für die Anwendung bei Multimedia und Internet-Übertragung. Daneben sollte dem Fernsehzuschauer eine nutzerangepasste und interaktive Navigation angeboten werden. Im Unterschied zu den bisherigen MPEG-Standards basiert MPEG-4 auf einer Aufteilung der Bildvorlage in Verbindung mit dem Begleitton in einzelne audiovisuelle Objekte. Die eigenständige Beschreibung dieser Objekte innerhalb des gesamten Datenstroms mit Hilfe einer speziellen Beschreibungssprache ermöglicht es, die vorliegende Szene auf der Empfängerseite durch Benutzerinteraktion nach eigenen Vorstellungen des Fernsehteilnehmers zu verändern. Damit bleiben Funktionen, die bisher nur während der Produktion des Programmbeitrags ausführbar waren, auf dem gesamten Signalweg erhalten. Mit dem später geschaffenen MPEG-7-Standard bietet sich damit eine Plattform für so genannte „Mehrwertdienste“.
Der MPEG-4-Standard nach ISO/IEC 14496 weist, wie auch bei MPEG-1 und MPEG-2 definiert, neben den Teilen Systems (14496-1), Audio- (14496-2) und Video (14496-3 Codecs) noch weitere Teile auf, von denen jedoch der Teil AVC (Advanced Video Coding) (14496-10) eine weit reichende Bedeutung erlangt hat. Von ITU-T wurden im Laufe der vergangenen Jahre Video-Kompressions-Standards definiert, die unter der Bezeichnung H.261 in MPEG-1 (Teil 2), H.262 in MPEG-2 (Teil 2)und H.263 in MPEG-4 (Teil 2) übernommen wurden. Es folgte ein neues, wesentlich verbessertes Kompressionsverfahren, das von der ITU-T mit H.264 bezeichnet und in MPEG-4, Teil 10, AVC eingebracht wurde.
Mit AVC/H.264 reduziert sich die Datenrate des komprimierten Videosignals gegenüber dem bei MPEG-2 verwendeten Verfahren auf die Hälfte oder weniger, bei gleicher Qualität des rekonstruierten Bildes. Allerdings ist die Rechenkomplexität auch um den Faktor zwei bis drei höher. H.264 wurde nicht für eine spezielle Anwendung entwickelt. Das Kompressionsverfahren bietet sich aber optimal an für den Einsatz bei HDTV-Übertragung, sowie bei der HD-DVD und Blu-ray-Disc [91]. Auch bei Videoübertragung auf Mobiltelefone oder PDAs mit dem DVB-H- oder DMB-Standard kommt H.264 zum Einsatz.
Gegenüber MPEG-2 weist die Videocodierung nach H.264 deutliche Veränderungen und Erweiterungen auf. Diese sind u. a.:
• An Stelle der Diskreten Cosinus-Transformation (DCT) auf 8x8-Pixel-Blöcke wird eine von der DCT abgeleitete Integertransformation auf 4x4-Pixel-Blöcke verwendet.
• Die Entropiecodierung (VLC) wurde an die veränderte Transformation angepasst.
• Die Makroblöcke mit 16x16 Pixel können auf Unterblöcke bis hinab auf 4x4 Pixel unterteilt werden.
• Die Bewegungskompensation ist immer auf 1/4 Pixel genau zum besseren Erhalt der Bildschärfe.
• Auch innerhalb von I-Bildern gibt es eine Prädiktion zu umliegenden Pixeln.
• P-Bilder und B-Bilder können nicht nur Referenzen auf das letzte I- oder P-Bild enthalten, sondern auch auf praktisch maximal fünf vorhergehende Referenzbilder.
• Mit einem Deblocking-Filter als integraler Bestandteil von H.264 wird der Bezug auf decodierte, aber bereits gefilterte Referenzbilder gewonnen.
• Die Makroblöcke innerhalb eines Slices können in relativ freier Reihenfolge angegeben werden. Dies ermöglicht eine Fehlerverdeckung bei Kanalverlusten, z.B. bei Videoübertragung im Mobilfunk.
MPEG-7-Standard mit dem Titel „Multimedia Content Description Interface” standardisiert die Techniken zur Beschreibung von Multimediadaten. Dieser Standard liefert ähnlich wie bei MPEG-2 der Abschnitt 1, Systems die „Grammatik” der beschreibenden Merkmale. Diese können sich auf Standbilder, Grafiken, dreidimensionale Modelle oder Musik beziehungsweise Sprache beziehen und zusätzlich auch Information enthalten, wie diese Elemente in einer gemeinsamen Präsentation zusammengefügt werden, MPEG-7 wurde im Jahr 2001 zum ISO/ IEC-Standard erklärt. Die programmbegleitenden Daten werden auch als Meta-Daten bezeichnet. Eine praktische Anwendung hat MPEG-7 zum ersten Mal bei der MHP (Multimedia Home Platform) gefunden als ein Standard für die neuere Generation der Set-Top-Box, als Zusatzgerät für den Empfang von digitalen Fernsehsignalen.
Die nach MPEG-4 und MPEG-7 aufbereiteten Datenströme bilden eine Ergänzung zu einem MPEG-1- oder insbesondere MPEG-2-Datenstrom. Dazu werden sendeseitig nach einer MPEG-2-adaptierten Umsetzung der MPEG-4-Teildatenströme diese zusammen mit dem ergänzenden MPEG-7-Datenstrom in einem Multiplexer in den MPEG-2-Transportstrom eingebracht (Bild 7.8, links). Empfängerseitig erfolgt zunächst eine parallele Verarbeitung des MPEG-2-Hauptdatenstroms und der zusätzlich übertragenen MPEG-4- und MPEG-7-Anteile. Ein Compositor verarbeitet die Teildatenströme zu den für die Bild- und Ton-Wiedergabe am Fernsehempfänger erforderlichen Signalen (Bild 7.8, rechts).
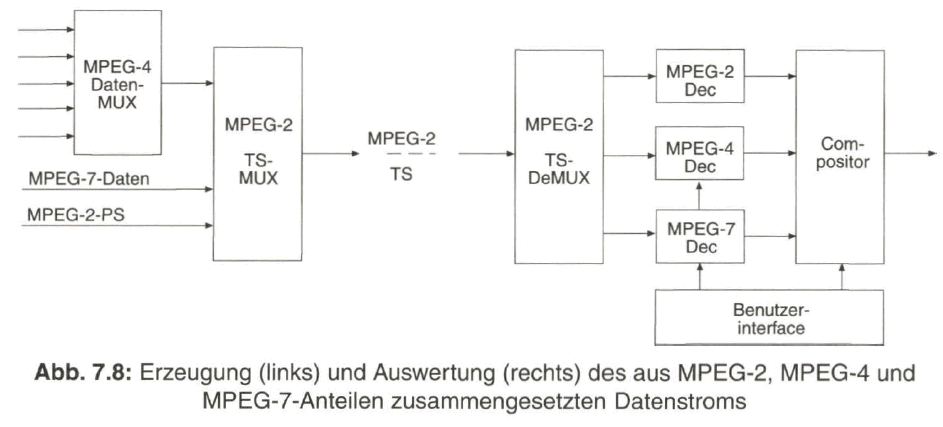
Der MPEG-4-Standard erweitert einerseits die in MPEG-2 implementierte Technik um die Interaktionsmöglichkeit mit einzelnen Video-, Audio- oder Grafikobjekten und ist damit wesentlich auf den vom Computer gewohnten Umgang mit Multimedia ausgerichtet. Andererseits lassen sich mit MPEG-4 Video- und Audiodaten sehr stark komprimieren und fehlerresistent aufbereiten, so dass diese Daten auch über neuere GSM-Mobilfunknetze übertragen werden können. Auch bei der Datenreduktion von HDTV-Signalen wird, wie schon erwähnt, das in MPEG-4-10 eingebrachte Verfahren nach H.264 zur Anwendung kommen. Zur Vorbereitung vom MPEG-21-Standard befasste sich die MPEG-Arbeitsgruppe zunächst mit einer Analyse der Situationen, die zukünftig bei der Komposition von individuellen Multimedia-Produktionen auftreten. Das Ergebnis dieser Analyse wurde als technischer Report definiert mit dem Titel „Vision, Technologien und Strategie”. Jeder elementare Multimediainhalt wird als digitaler Artikel bezeichnet. Im Weiteren werden sieben Unterabschnitte festgelegt, in denen detaillierte Festlegungen zu treffen sind. Bis Mitte 2002 waren die Inhalte von zwei dieser Unterabschnitte festgelegt. Das Ziel von MPEG-21 ist ein technischer Rahmen für die Abwicklung von Produktion, Verteilung und Ausnutzung von Multimedia auf einem durchgehend digitalen Weg.
8. MPEG-2 Systemmultiplex
MPEG-2-Video- und Audio-Encoder liefern an ihren Ausgängen die Elementary Streams (ES), die Bestandteile der Compression Layer sind. Wie bereits im Abschnitt 7.2.1 kurz erläutert, werden der komprimierte Video- und Audio-Datenstrom in Pakete (packets) aufgeteilt. Dies führt zu dem paketierten Elementarstrom PES für Video (Video Packetized Elementary Stream) und PES für Audio (Audio Packetized Elementary Stream).
8.1 Programmstrom (PS)
Die Aufteilung des Datenstroms in Pakete erfolgt zu dem Zweck der Verschachtelung von Paketen verschiedenen Ursprungs in einem gemeinsamen Bitstrom. Dies wird in einem ersten Schritt zunächst der so genannte Program Stream (PS) sein, in dem für ein Fernsehprogramm der Video-Datenstrom und der Audio-Datenstrom mit einer gemeinsamen Zeitbasis (System Time Clock, STC) sowie eventuell ein Datenstrom mit alphanumerischen Zeichen (z. B. Teletext) eingebracht werden (Bild 8.1).
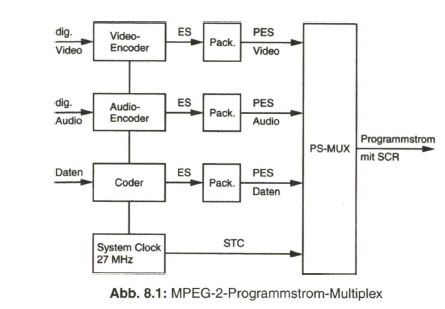
Ein Elementardatenstrom (ES) wird in Pakete unterschiedlicher Länge zerlegt, in der Regel mit einer maximalen Paketlänge von ![]() - 1 byte = 65 535 byte, in Ausnahmefällen bei Video-Paketen aber auch länger. Ein PES-Paket enthält nur Video- oder nur Audiodaten, bei Videodaten enthalten diese ein komprimiertes Teilbild. Das vereinfacht den Decodierprozess. Die Folge der Elementarstrom-Pakete bildet dann den Packetized Elementary Stream (PES).
- 1 byte = 65 535 byte, in Ausnahmefällen bei Video-Paketen aber auch länger. Ein PES-Paket enthält nur Video- oder nur Audiodaten, bei Videodaten enthalten diese ein komprimiertes Teilbild. Das vereinfacht den Decodierprozess. Die Folge der Elementarstrom-Pakete bildet dann den Packetized Elementary Stream (PES).
Ein Packet Header mit 6 byte wird vor die eigentlichen Nutzdaten mit Angaben über den Paketinhalt (Identifikation) und die Paketlänge eingefügt. Zusätzlich kann ein optionaler PES Header mW minimal 3 byte und maximal 253 byte ergänzt werden, der Steuerinformationen für das jeweilige Paket, wie Zeitmarken zur Decodierung, Decoding Time Stamps (DTS), und zur Wiedergabe der (Bild-) lnformation, Presentation Time Stamps (PTS) enthält. Für die eigentlichen Nutzdaten (PES Packet Data) verbleiben damit maximal 65 535 byte - 9 byte = 65 526 byte (Bild 8.2).
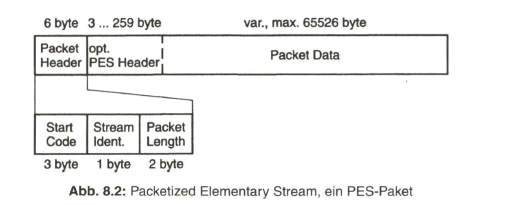
Die Aufeinanderfolge der PES-Pakete wird zwischenzeitlich durch das Einfügen eines Pack Headers und eines System Headers unterbrochen. Der Pack Header enthält Zeitmarken, die aus dem System Clock abgeleitet werden und nun die System Clock Reference (SCR) bilden, die der Decoder zur Synchronisation benötigt. Im System Header sind systemspezifische Informationen über den Datenstrom enthalten. Beide Header markieren den Rahmen, der die kontinuierliche Folge von PES-Paketen, die Packs oder Gruppen, unterteilt. Diese Unterteilung ist vom MPEG-1-Programmstrom übernommen worden, um eine möglichst große Kompatibilität zu gewährleisten. Den Aufbau des Rahmenkopfs eines PES Pack gibt Bild 8.3 wieder.
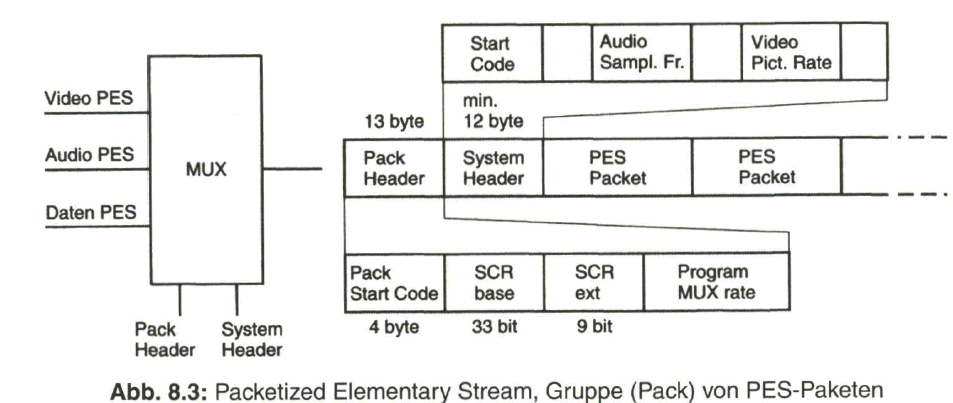
Die Übertragung der System Clock Reference durch Codeworte, die mindestens alle 700 ms in den Programmstrom eingefügt werden, wird beim Transportstrom ausführlich behandelt. Wegen der relativ langen Pakete eines Programmstroms und der damit verbundenen Störanfälligkeit ist seine Anwendung auf eine quasi-fehlerfreie Umgebung beschränkt. Hierzu zählen die Programmerstellung im Studio sowie die Speicherung auf Magnetband oder Platten. Der Programmstrom weist eine feste Bitrate auf. Die Bedeutung des Programmstroms ist aber nur untergeordnet bei dem eigentlichen „Digitalen Fernsehen“
.
8.2 Transportstrom (TS)
Die Datenübertragung in Weitverkehrsnetzen und bei der Fernsehprogrammübertragung über Satelliten- oder Kabelkanäle sowie im terrestrischen Verteilnetz erfolgt auf der Basis des Transport Stream (TS). Der Transportstrom kann oder wird meistens die Daten von mehreren Programmen enthalten, die im Transportstrom-Multiplex zusammengefügt werden.
Wegen möglicher streckentypischer Übertragungsfehler muss der Transportstrom eine besonders robuste Struktur in Form von kurzen Paketen aufweisen. Die Transportstrompakete weisen eine feste Paketlänge von 188 byte auf, wovon 4 byte vom Header belegt werden und die restlichen 184 byte für die Übertragung der Nutzinformation zur Verfügung stehen. Ein Teil der Nutzdaten kann einem Adaptation Field zugewiesen werden, wo in ausgewählten Transportstrompaketen u. a. mit der Program Clock Reference (PCR) die Systemzeit übertragen wird (Bild 8.4).

Die Paketlänge von 188 byte wurde als ein Vielfaches (4-mal) der Länge des Datenblocks einer ATM-Zelle (Asynchronous Transfer Modus) mit 47 byte wegen der kompatiblen Übertragung in ATM-Netzen gewählt. Bei dem Asynchronen Transfer Modus handelt es sich um ein paketvermitteltes Übertragungsverfahren, bei dem die Nutzinformation in Zellen fester Länge übertragen wird. Die ATM-Zellen haben eine feste Länge von 53 byte, wovon 5 byte dem Header zugeordnet sind und 48 byte für die Nutzinformation zur Verfügung stehen (Bild 8.5 a). Bei der Übertragung von Transportstrompaketen werden davon jeweils 47 byte belegt, ein Byte wird für spezifische Information ausgenutzt (Bild 8.5 b).
Außerdem soll die Nutzinformation wegen der Anwendung von Verschlüsselungstechniken, die im Allgemeinen auf einer 8-byte-Sequenz basieren, ganzzahlig durch 8 byte teilbar sein.
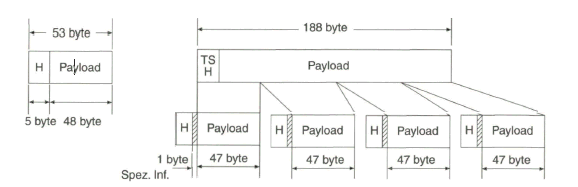
Abb. 8.5: a) ATM-Zelle, b) Aufteilung eines Transportstrompakets auf die ATM-Zellen
8.2.1 Transportstrom-Multiplex
Auch beim Transportstrom ist jedes Paket auf die Daten einer Signalkomponente (Video, Audio oder anderes) beschränkt. Die Quellencoder für Video, Audio und Zusatzdaten liefern einen paketierten Elementarstrom (PES), in dem auch die Zeitmarken DTS und PTS enthalten sind, an den Transportstrom-Multiplexer (TS).
Darin werden die Komponenten zusammengefasst und mit Program Specific Information (PSI) sowie der aus dem System Time Clock abgeleiteten Program Clock Reference (PCR) ergänzt. Aus mehreren MPEG-2-Transportströmen wird dann letztendlich in einem Service-Multiplexer das „Programm-Bouquet“ gebildet. Dieser „Sende-MPEG-2-Transportstrom“ wird in die TV-Verteilnetze eingespeist (Bild 8.6)
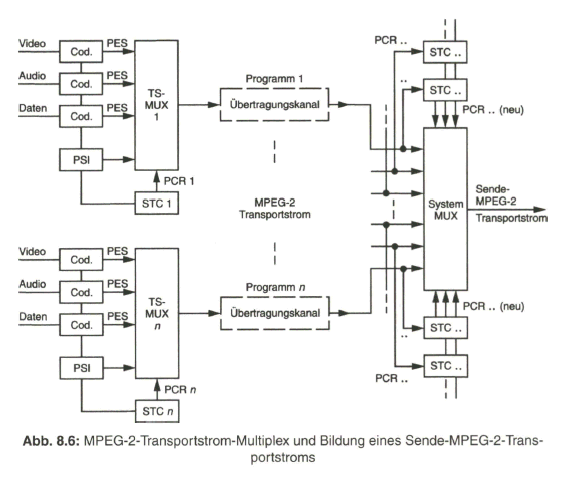
Der Sende-MPEG-2-Transportstrom kann sich aus Programmen mit Video- und Audioanteilen, mit Audiobeiträgen (Rundfunk-Programmen) oder der Information aus Datendiensten zusammensetzen. Die Struktur ist flexibel und kann sich auch noch während der Übertragung verändern. Die aktuelle Zusammensetzung aus den verschiedenen Beiträgen wird in der nach MPEG-2-Systems definierten Program Association Table (PAT) übertragen.
Die Summenbitrate des „Sende-MPEG-2-Transportstroms“ hat einen festen Wert. Dieser kann sich zusammensetzen aus:
• festen Bitraten der einzelnen Programmbeiträge beim so genannten statischen Multiplex, wobei berücksichtigt wird, dass z. B. eine Sportveranstaltung mit hohem Bewegungsanteil eine höhere Datenrate als ein Spielfilm mit anteilig mehr statischen Szenen und ruhendem Hintergrund verlangt, oder
• aus in gewissen Grenzen schwankenden Bitraten, abhängig vom momentanen Programminhalt, mit einem stets festen Wert der Gesamtbitrate beim statistischen Multiplex. Eine Übereinkunft der in dem „Bouquet“ zusammengefassten Programmanbieter ist dazu notwendig. Siehe dazu Bild 8.7.
Der Decoder auf der Empfangsseite muss sich auf diese in Grenzen variable Bitrate eines Programmbeitrags automatisch einstellen können.
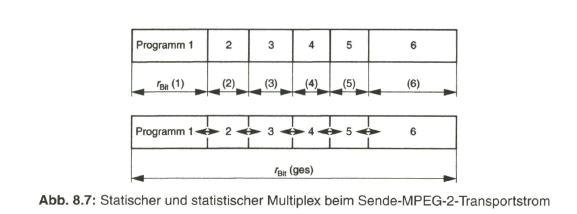
Der Vorteil des statistischen Multiplex liegt darin, dass mit einer relativ niedrigen mittleren Datenrate bei plötzlich auftretenden ungünstigen Codiersituationen in einem Programm kein zu starker Eingriff auf die Bitrate über die Steuerung der Quantisierung bei den DCT-Koeffizienten erforderlich ist und damit kein so deutlicher Qualitätsverlust beim wiedergegebenen Bild sichtbar wird.
Die Programmdatenrate, die einem einzelnen Fernsehprogramm im Sende-Multiplex zur Verfügung gestellt wird, richtet sich nach der Art des Programms. Mit Steuerung der Bitrate innerhalb der zulässigen Schwankungsbreite kann ein für alle Programme eines Bouquets vergleichbarer Qualitätseindruck erreicht werden. Der zusätzliche Aufwand in der Technik kommt insbesondere dann zum Tragen, wenn Qualitätseinbrüche, die durch spontane Änderungen im Bildinhalt auftreten, wirksam reduziert werden. Durch statistischen Multiplex kann jedoch nicht die Anzahl der in diesem Bouquet übertragbaren Programme erhöht werden.
Die Zuordnung der Daten aus einem PES Packet auf die 188-byte-Pakete des Transportstroms gibt Bild 8.8 wieder. Der MPEG-2-Standard sieht vor, dass der PES Header in der Regel gleich nach dem Transport Stream Header folgt. Bei einem Transportpaket mit einem Adaptation F/e/d wird der PES Header nach dem Adaptation Field übertragen. Im Transportstrom können Pakete mit den Daten aus verschiedenen Elementarströmen und damit unterschiedlichen Zeitbasen (STC) aufeinander folgen. Maßgeblich für die absolute Zeitreferenz ist die Program Clock Reference (PCR), die im Transportstrom-Multiplexer bzw. im Service-Multiplexer im Abstand von maximal 100 ms (nach der DVB-Spezifikation nur 40 ms) in das Adaptation Field eingebracht wird.
Jedes Transportstrompaket hat einen Paketkopf, den Transport Paket Header, mit 4 Bytes. Für die Payload verbleiben maximal 184 Bytes, wovon ein Teil vom Adaptation Field genutzt werden kann (Bild 8.9). Der Paket Fleader beginnt mit einem Sync-Byte, mit dessen Hilfe die Rahmensynchronisation auf die 188-byte-Pakete erfolgt.
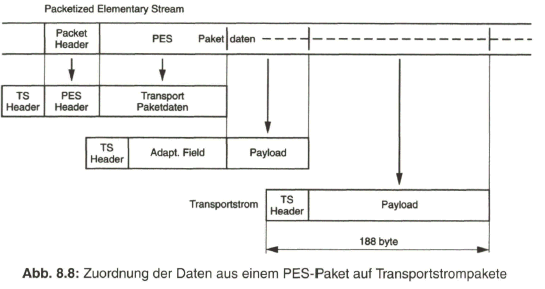
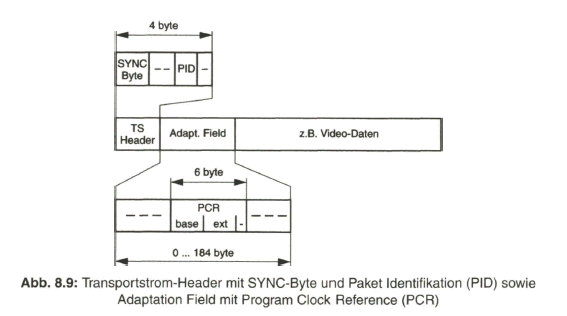
Die Zusammensetzung des Transport Stream Header gibt die folgende Tabelle 8.1 wieder.

Über die Paket Identification (PID) lassen sich die Daten eines Transportstrompakets auf die verschiedenen Programmstrom-Anteile, unterschieden nach Programmanbieter und Video, Audio oder Zusatzdaten, zuordnen. Die PID mit der Nummer 0 ist für die Program Association Table (PAT) vergeben. Diese Tabelle enthält die Zusammensetzung des Programm-Multiplexes aus den einzelnen Fernseh-Programmen und verweist auf die zugehörigen PIDs. Beim MPEG-2-Decoder werden zunächst nur die Pakete mit der PID-Nummer 0 ausgewertet, woraus eine Liste der übertragenen Programme erstellt wird. Dann erfolgt über die Programmwahl durch den Fernsehteilnehmer der Zugang auf die dem gewünschten Programm zugeordneten PIDs.
8.2.2 Zeitreferenz im Transportstrom
ln den Paketen, die zur Video-Information des ausgewählten Programms gehören, wird in ausgewählten Adaptation Fields die Program Clock Reference (PCR) übertragen. Diese repräsentiert eine „Referenzzeit“, die aus dem jeweiligen System Time Clock (STC) eines Programms abgeleitet wird. Im Programmstrom wird die Referenzzeit in die System Clock Reference (SCR) eingebracht und in einem erweiterten Packet Header übertragen. Die Unterscheidung wird getroffen, weil beim Programmstrom nur ein Programm, beim Transportstrom hingegen mehrere Programme übertragen werden. Der Begriff Program Clock Reference (PCR) verdeutlicht, dass sich diese Zeitmarken im Transportstrom auf ein bestimmtes Programm beziehen.
Die Synchronisation der Datenströme auf der Encoder- und Decoderseite beruht auf dem Prinzip, dass auf beiden Seiten eine Systemuhr (System Time Clock, STC) vorhanden ist, mit der die aktuelle „Uhrzeit“ festgelegt wird. Diese wird aber nicht in Stunden, Minuten und Sekunden, z.B. als „Weltzeit“ UTC angegeben, sondern jeweils in einem Zeitabschnitt von etwa 24 Stunden durch eine „Nummer“, mit der die Anzahl der seit dem Startzeitpunkt abgelaufenen Schwingungen des 27-MHz-Systemtakts ausgedrückt wird.
Beim Encoder wird ein Zähler von dem hochstabilen 27-MHz-Taktalle 37,037... ns inkrementiert. Der Zählerstand wird im Abstand von etwa 100 ms bzw. in Verbindung mit Digital Video Broadcasting (DVB) im Abstand von etwa 40 ms in der Program Clock Reference übertragen. Der Decoder wertet die PCR zur Synchronisierung des decoderseitigen 27-MHz-Oszillators und zur Rückgewinnung der Systemzeit aus (Bild 8.10).
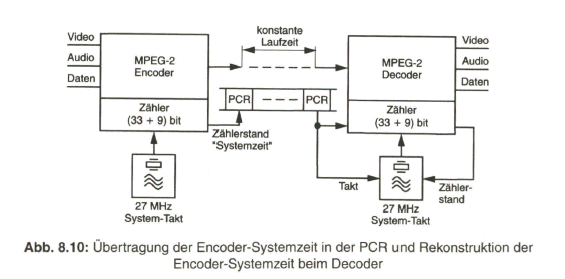
Ein Zeitbereich von
24 h = 24 x 3600 s = 24 x 3600 x 109 ns = 8,64 x 1013 ns,
zusammengesetzt aus Inkrementen von 37,037... ns
erstreckt sich über 2,3328 x 1012 Inkremente.
Zur binären Codierung dieses Zahlenbereiches sind
1 d (2,3328 x 1012) = 1 g (2,3328 x 1012) / 1 g 2 = 41,085... bit
erforderlich, das heißt es sind 42 bit nötig.
Mit 42 bit wäre aber der abdeckbare Zeitbereich nun 45,24 Stunden. Die 42 bit werden gemäß MPEG-2 aufgeteilt in eine PCR base mit einer Codewortlänge von 33 bit und in eine PCR extension mit 9 bit. Der Sinn dieser Aufteilung liegt in der Kompatibilität mit MPEG-1, wo von einer 90- kHz-Zeitbasis (System Time Clock) mit einem Zeit-Inkrement von 11,11... ![]() ausgegangen wird. Von diesem 90-kHz-System-Time-Clock wird die PCR base mit 33-bit-Codeworten abgeleitet. Bei MPEG-2 allerdings wird eine höhere Zeitgenauigkeit gefordert. Die 9-bit-Codeworte aus der PCR extension takten einen zyklischen Zähler, der beim Erreichen eines Zählerstandes von 300 einen Übertrag zu dem 33-bit-Basisfeld liefert, d.h. den numerischen Betrag der PCR base um den Wert eins erhöht, und selbst dabei gleichzeitig zurückgesetzt wird. Von den möglichen 512 Werten der 9-bit-Codeworte wird so nur der Bereich bis 300 ausgenutzt. Der gesamte codierbare Zeitbereich mit den Inkrementen von 37,037... ns reduziert sich damit auf
ausgegangen wird. Von diesem 90-kHz-System-Time-Clock wird die PCR base mit 33-bit-Codeworten abgeleitet. Bei MPEG-2 allerdings wird eine höhere Zeitgenauigkeit gefordert. Die 9-bit-Codeworte aus der PCR extension takten einen zyklischen Zähler, der beim Erreichen eines Zählerstandes von 300 einen Übertrag zu dem 33-bit-Basisfeld liefert, d.h. den numerischen Betrag der PCR base um den Wert eins erhöht, und selbst dabei gleichzeitig zurückgesetzt wird. Von den möglichen 512 Werten der 9-bit-Codeworte wird so nur der Bereich bis 300 ausgenutzt. Der gesamte codierbare Zeitbereich mit den Inkrementen von 37,037... ns reduziert sich damit auf
45,24 h x 300/512 = 26,5 h, also etwas mehr als 24 Stunden.
Die System-Datenströme sind byteweise definiert. Die Program Clock Reference belegt mit 33 bit für PCR base, 9 bit für PCR extension und weiteren reservierten 6 bit insgesamt 6 byte. Der PCR-Wert entspricht dem Stand des encoderseitigen Zählers mit dem 27-MHz-Takt zum Zeitpunkt des Eintreffens des ersten Bytes des Transportstrompakets, in dem der PCR-Wert übertragen wird.
In einem korrekt übertragenen MPEG-2-Datenstrom trifft jede PCR genau zu der „Uhrzeit“ beim Decoder ein, die im PCR-Wert übertragen wird. Wenn der decoderseitige 27-MHz-System-Takt genau dem des Encoders entsprechen würde, dann würde irgendein PCR-Wert genügen, um die Decoder- „Uhrzeit“ auf die des Encoders einzustellen. Diese Situation wird jedoch bei einer Diskontinuität im ausgewerteten Datenstrom, z. B. beim Umschalten auf ein anderes Programm aus dem Transportstrom, gestört. Es ist deshalb ein Regelmechanismus in Form einer PLL (Phase Locked Loop) vorgesehen, bei der an Stelle von zeitabhängigen Signalen für die Ist- und Soll-Größen nun codierte Zahlenwerte (PCR-Wert und Zählerstand) treten. Siehe dazu Bild 8.11.
Zu dem Zeitpunkt, zu dem die PCR den Decoder erreicht, wird ihr Wert mit dem momentanen Zählerstand der Decoder-Systemzeit verglichen. Die Differenz, als Zahlenwert codiert mit (33 + 9) bit, wird auf Inkremente des 27-MHz-Taktes gebracht und nach einer Tiefpass-Filterung zur Mittelwertbildung über mehrere Zyklen hinweg als Stellgröße an den 27-MHz-NCO angelegt. Durch Beeinflussung der Frequenz des NCO wird gewährleistet, dass diese bis auf eine sehr geringe Regelabweichung identisch ist mit der Frequenz des encoderseitigen 27-MHz-System-Takts und somit zum Decoder System Time Clock wird. Außerdem wird dieser System-Takt einem Zähler zugeführt, der nun, nach Laden der übertragenen PCR, als Stützwert die decoderseitige Systemzeit generiert. Diese setzt sich aus dem PCR-base-Anteil (33 bit) und dem PCR-extension-Anteil (9 bit) zusammen. Sie wird wiederum auf den Vergleicher im PLL zurückgeführt.
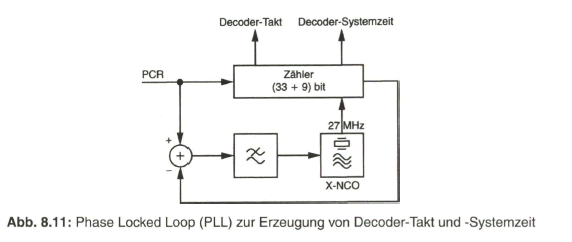
Der mit 33 bit codierte 90-kHz-Anteil des System Time Clock dient als Zeitbasis für die im Program Elementary Stream enthaltenen Decoding Time Stamps (DTS) und die Presentation Time Stamps (PTS), die ebenfalls mit 33 bit codiert sind. Eine Unterscheidung nach „Decoding“ und „Presentation“ Time Stamps ist notwendig, weil die Reihenfolge der Ankunft der PES-Pakete und deren Decodierung nicht immer der Reihenfolge der Präsentation der Videobilder entspricht, z.B. bei der Übertragung von Differenzbildern. Häufig aber haben PTS und DTS den gleichen Wert oder es wird nur ein Presentation Time Stamp übertragen.
Die in manchen Transportstrompaketen (bei DVB mindestens alle 40 ms) in deren Adaptation Field übertragene PCR (Program Clock Reference) ist die absolute Zeitbasis, auf die sich der Empfänger bei der Verarbeitung der Datenpakete für ein bestimmtes Programm bezieht. Sie ist genauso definiert wie die im paketierten Elementarstrom (PES) enthaltene SCR (System Clock Reference). Jedes Programm führt somit innerhalb des Sende-Transportstroms, gekennzeichnet durch eine PID oder mehrere PIDs, seine eigene PCR mit sich. Mit der Auswahl des Programms werden nur die zu diesem Programm gehörigen PCRs ausgewertet. Die gerade als erste eintreffende PCR (i) wird, selektiert über die PID, dem Datenstrom entnommen und startet nun den 27-MHz-Systemtakt und die Systemzeit. Damit wird gewährleistet, dass sich die Decoder-Systemzeit auf die Encoder-Systemzeit des ausgewählten Programms einstellt (Bild 8.12).
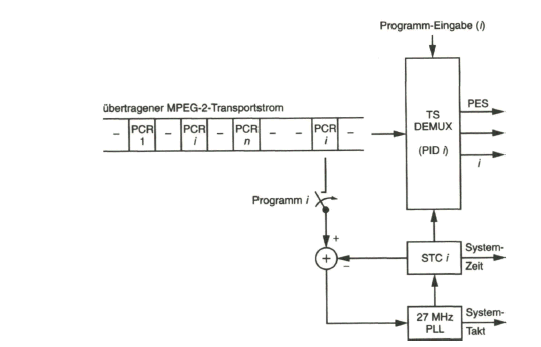
Abb. 8.12: Einstellung von Decoder-Takt und -Systemzeit auf Encoder-Takt und -Systemzeit des ausgewählten Programms
Durch die Rekonstruktion der Encoder- „Uhrzeit“ auf der Decoderseite haben bei angenommen konstanter Laufzeit auf der Übertragungsstrecke die unterschiedlichen Verzögerungen beim Transportstrom-Multiplexer und beim Transportstrom-Decoder keine Auswirkung. Siehe dazu den Hinweis in Bild 8.10.
Die Regenerierung der Encoder- „Uhrzeit” wird allerdings beeinträchtigt, sobald die PCR-Zeitmarken aus ihrer eigentlichen Position im Datenstrom verschoben werden. Dies kann durch einen Takt-Jitter auf digitalen ATM-Übertragungsstrecken erfolgen oder beim Umsortieren von Paketen für einen neu zu konfigurierenden Datenstrom, wie z.B. beim Übergang vom Satelliten- auf den Kabel-Übertragungskanal mit etwas unterschiedlichen Datenraten im Programmanteil des Transportstroms (mit 38,015 Mbit/s im Satellitenkanal und 38,15 Mbit/s im Kabelkanal) oder bei der Zusammensetzung von neuen Transportstrom-Multiplexen mit geändertem Programmangebot. Beim Übergang von der niedrigeren Datenrate im Satellitenkanal auf die etwas höhere Datenrate im Kabelkanal müssen die einzelnen Transportstrompakete zeitlich komprimiert werden. Die entstehenden Lücken im Transportstrom werden dann durch Stopf-Bits (Null-Pakete) aufgefüllt.
Ein Aktualisieren der Zeitmarken (Restamping) wird in diesem Fall notwendig. Dies geschieht in dem System-Multiplexer, wie in Bild 8.6 dargestellt. Es müssen dazu die einzelnen paketierten Elementarströme (PES) zurückgewonnen werden (Demultiplex), bevor sie wieder zu einem neuen Sende-Transportstrom zusammengestellt werden (Remultiplex). Von jedem ankommenden Transportstrom wird die aktuelle Systemzeit durch Auswerten der PCR über eine PLL zurückgewonnen. Während die „Uhr” weiterläuft, findet in einem Zwischenspeicher die Neuzuordnung der Pakete von den einzelnen Programmen statt. Im Multiplexer wird dann die aktuelle „Uhrzeit” durch Überschreiben der vorangehenden Werte in das Datenfeld der PCR eingebracht. Das muss für jedes Programm mit seinem zugeordneten System Time Clock erfolgen.
Eine mehrmalige Aktualisierung der PCR kann zu einer steigenden Ungenauigkeit in der Zeitangabe führen, was zu einem Jitter bei der Rekonstruktion der Systemzeit führen kann. Nach einer MPEG-Vorgabe sollte dieser Jitter bei den PCR-Werten den Toleranzbereich von 500 ns nicht überschreiten.
8.2.3 Programmspezifische Information
ln den Transportstrompaketen wird die Nutzinformation der Video- und Audio-Programmanteile übertragen. Es können aber auch alphanumerische Zeichen, z. B. für Teletext oder von Mehrwertdiensten, eingebracht werden. Ergänzend dazu wird es erforderlich, programmbegleitende Information und Angaben über die Struktur des betreffenden Transportstroms zu übermitteln. Dies geschieht in der nach MPEG-2 definierten Program Specific Information (PSI). Darin enthalten sind vier verschiedene Tabellen (tables), die ihrerseits wieder in Segmente (sections) unterteilt sind. Je nach Bedeutung enthält eine Tabelle bis zu 256 sections. Die Untergliederung der Tabellen in Segmente hat den Vorteil, dass bei der Aktualisierung einer Tabelle nicht deren gesamter Inhalt neu zu übertragen ist, sondern nur das betreffende Segment, in dem sich der aktualisierte Teil der Tabelle befindet.
Die Wiederholfrequenz der Tabellen ist nicht im Standard festgelegt, muss jedoch so hoch sein, dass der Decoder sich schnell auf das gewünschte Programm einstellen kann. In der Praxis werden die Tabellen etwa 10 bis 50 mal pro Sekunde wiederholt. In den ersten beiden Tabellen wird angegeben, welche Programme in diesem Transportstrom enthalten sind und aus wie vielen und welchen Elementarströmen jeweils ein Programm zusammengesetzt ist. Dazu verweist eine im Transportstrom-Header enthaltene PID mit der Nummer Null (0x000) zunächst auf die in der Payload dieses Transportstrompakets übertragene Program Association Table (PAT). Sie informiert über die Anzahl und die PIDs der in diesem Transportstrom enthaltenen Programme. Die Programmnummer 0 ist reserviert für den Verweis auf die Network Information Table (NIT).
Die Programmnummer, angegeben durch die zugehörige PID, führt zur Program Map Table (PMT). Diese wiederum enthält eine Liste aller PIDs für die Elementarströme, die zu dem in der Tabelle zugeordneten Programm gehören. Ergänzend werden in den zugehörigen sections bei den descriptors Verweise auf Transportstrompakete mit der Program Clock Reference (PCR) gegeben und Angaben zur näheren Beschreibung der Elementarströme gemacht. Bild 8.13 gibt die Zuordnung von der Program Association Table auf die Program Map Table wieder.
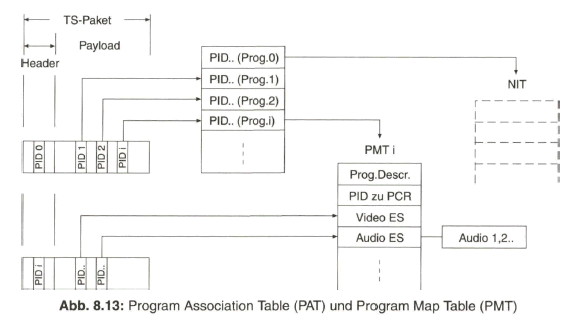
Aus einem Transportstrompaket mit der PID 0 im TS Header wird vom Payload-Teil die PAT als eine Auflistung der PIDs für die in diesem Transportstrom enthaltenen Programme entnommen. Diese PIDs wiederum führen zu den PMTs, die den einzelnen Programmen zugeordnet sind. Die Program Map Tables sind ausgewählte Transportstrompakete mit eigener PID und einem differenzierten Payload-Teil. Wenn z.B. das Programm i ausgewählt werden soll, dann wird zunächst die PID i aus der Liste aller PIDs im Payload-Teil der PAT entnommen. Der Decoder holt dann alle Transportstrompakete mit der PID i im TS-Header heraus. In diesen TS-Paketen ist nun die PMT für das Programm i enthalten. In der PMT für das Programm i finden sich im Weiteren die PIDs für alle Elementarströme von Video, Audio und Daten. Dabei können z.B. auch verschiedene Sprachen für den Begleitton übertragen werden, was wiederum in einer näheren Spezifizierung angegeben wird.
In der Network Information Table (NIT), für die, wie schon erwähnt, nach MPEG die Programmnummer 0 reserviert ist und die nicht näher spezifiziert ist, können Private Data mit Angaben zu der Orbitposition des Satelliten, dem Frequenzband, der Transpondernummer, Kanalbandbreite oder Symbolrate übertragen werden. Damit werden Informationen für die automatische Abstimmung der Empfänger bereitgestellt.
Die Conditional Access Table (CAT) wird übertragen, sobald wenigstens ein Programm im Transportstrom verschlüsselt ist und damit nur bedingten Zugriff hat. Sie steht gleichrangig neben der Program Association Table (PAT) und ist durch die PID mit der Nummer 01 (0x001) versehen. Die Aufgabe der Conditional Access Table besteht in der Bereitstellung von Informationen zum Entschlüsseln der für Pay-TV verwürfelten Datensätze, das heißt die Kennzeichnung des Verschlüsselungssystems, die Vergabe von Zugangsberechtigungen und die Übermittlung der Code-Sequenzen. Genauso wie die NIT ist auch die CAT nicht mehr von MPEG spezifiziert, sondern fällt unter die Spezifizierung nach DVB.
Über die von MPEG-2 in der Program Specific Information (PSI) definierten Tabellen hinaus besteht die Möglichkeit, im Rahmen der Service Information (Sl) von DVB weitere Tabellen mit Informationen, die direkt für den Fernsehzuschauer gedacht sind, z.B. für eine elektronische Programmzeitschrift oder zur Videorecorder-Steuerung, im Transportstrom zu übertragen [2]. Mit der Service Information lässt sich ein so genanntes „Lesezeichen” realisieren, das zum Auffinden von bestimmten im Empfänger einprogrammierten Beiträgen dient, oder ein elektronischer Programmführer EPG (Electronic Program Guide). Mit diesem wird dem Fernsehteilnehmer eine komfortable Benutzeroberfläche angeboten, die zur gezielten Suche nach bestimmten Programmbeiträgen dient.
Die zusätzlich von DVB definierten Tabellen sind: Bouquet Association Table (BAT). Sie enthält Informationen über die verschiedenen Programme (das „Bouquet“ der Programme) eines Anbieters, unabhängig von deren Verteilwegen. Die Service Description Table (SDT) führt die Namen und Parameter der verschiedenen Dienste innerhalb des Daten-Multiplex auf. Es werden die Programme beschrieben und Hinweise zu den Sendeanstalten gegeben. Die Event Information Table (EIT) stellt eine elektronische Fernsehzeitschrift mit Kennung der Programmart und Klassifizierung in bezug auf die Eignung für bestimmte Altersgruppen dar.
Die Running Status Table (RST) beinhaltet Statusinformationen zu den einzelnen Programmen, z.B. ob eine bestimmte Sendung gerade läuft oder eventuell verzögert beginnen wird, und dient so insbesondere zur Steuerung von Videorekordern. Die Time and Date Table (TDT) und Time Offset Table (TOT) liefern Informationen über die aktuelle Uhrzeit und das Datum sowie über lokale Zeitverschiebungen. Die Stuffing Table (ST) hat keinen relevanten Inhalt und wird zum Überschreiben nicht mehr gültiger, vorher benutzter Tabellen verwendet.
8.2.4 Teletext-Übertragung bei Digital Video Broadcasting (DVB)
Das Teletext-System beim analogen Fernsehen, in Deutschland unter dem Namen Videotext bekannt, basiert auf der Übertragung von Roll-Off-gefilterten NRZ-Datenbits während der Vertikal-Austastlücke des FBAS-Signals mit Anbindung der Videotext-Zeilen an die Fernsehzeilen.
Nach DVB-Spezifikationen wird ein Videotext-Elementarstrom erzeugt und in den MPEG-2-Transportstrom eingebracht. Die Videotext-Daten werden magazin- und zeilenweise aufbereitet und zunächst als Packetized Elementary Stream zusammengestellt. In dem 6 byte langen PES-Header ist ein Stream Identifier mit der Kennung OxBD enthalten, was einem „Private Stream 1“ entspricht. Die Paketlänge wird bei Videotext so festgelegt, dass sie immer einem ganzzahligen Vielfachen von 184 byte entspricht. Sie wird mit einem Längenindikator im PES-Header angegeben (Bild 8.14a).
Dem PES-Header mit 6 byte folgt ein optionaler PES-Header mit 39 byte. Mit einem Byte wird anschließend die Data ID angegeben, die immer den Wert Ox10 hat. Die eigentliche Videotext-Information ist in Blöcke von 44 byte eingeteilt, wobei die jeweils einem 1-byte-Zusatzfeld folgenden 43 byte direkt dem Aufbau einer Videotext-Zeile, nach dem Run-In-Code, gemäß der Spezifizierung nach EBU-VTXT entsprechen (Bild 8.14b).
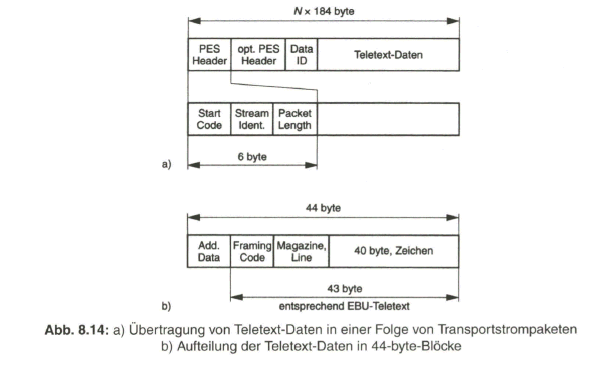
Es werden so die Angaben über Magazin- und Zeilennummer sowie die darzustellende Information mit 40 byte für 40 Zeichen pro darzustellende Zeile übernommen. Eine Videotext-Seite beinhaltet 24 Zeilen mit je 40 Zeichen. Der in den langen PES-Paketen aufbereitete Teletext wird im Multiplexer in kurze Transportstrompakete mit je 184 byte Nutzinformation und einem 4-byte-Transportstrom-Header aufgeteilt und genauso wie Video- oder Audio-Pakete im Transportstrom übertragen. Die Packet Identifiers (PIDs) von Transportstrompaketen mit Videotext werden als PIDs für Private Streams in der Program Map Table (PMT) des jeweiligen Programms definiert. Damit kann der Decoder auf Transportstrompakete mit Videotext zurückgreifen.
8.2.5 Zugriff auf ein Programm
Die im Folgenden beschriebenen Vorgänge müssen beim Decoder ablaufen, um ein Programm oder einen Dienst in dem MPEG-2-Transport-Multiplex zu finden, nachdem das Programm-Bouquet durch Auswahl des HF-Empfangskanals bestimmt wurde. Der Transportstrom setzt sich aus den 188-byte-Paketen zusammen, mit jeweils dem SYNC-Byte zu Beginn eines Pakets. Das SYNC-Byte hat eine definierte Bitfolge mit 01000111 (hex 47). Dieses Bitmuster ist aber nicht nur für das SYNC-Byte reserviert, sondern kann auch im weiteren Datenstrom auftreten. Um dennoch eine sichere Synchronisation zu gewährleisten, wird das sich wiederholende Auftreten des SYNC-Byte-Musters im Abstand von 188 byte überprüft. Mit so genannten Hysterese-Parametern wird vorgegeben, wie oft das Bitmuster 01000111 im Abstand von 188 byte aufeinanderfolgend erkannt werden muss, damit die Synchronisation auf die Transportstrompakete als eingerastet gilt.
Sobald der Decoder sich auf den Transportstrom über die Sync-Bytes synchronisiert hat, müssen
• die Transportstrompakete mit der PID 0 herausgefiltert werden, um an die PAT-Segmente zu kommen.
• Die PAT wird aus den Segmenten aufgebaut. Dem Fernsehzuschauer kann so das Programmangebot tabellarisch sichtbar oder geräteintern über die Zuordnung von Programmnummern angeboten werden. Siehe dazu den Ablaufplan in Bild 8.15.
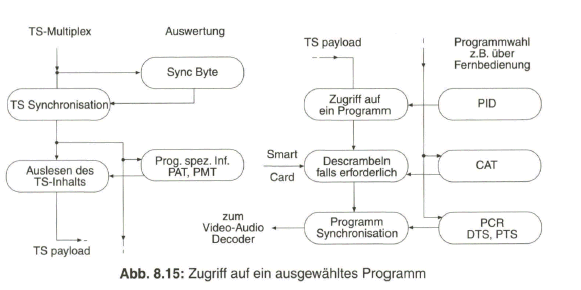
Nach Auswahl des gewünschten Programms muss der Decoder
• die entsprechenden PIDs gemäß der PMT dieses Programms herausfiltern und
• die PMT aus den relevanten Segmenten aufbauen.
Als Nächstes werden
• die Pakete, die durch das PCR_PID-Feld der PMT markiert sind, herausgefiltert, um daraus die Program Clock Reference (PCR) zu gewinnen und den System Clock (STC) zu synchronisieren.
Der Video- und Audio-Decodierprozess kann nun laufen. Das Umschalten auf ein anderes Programm nimmt mehr Zeit in Anspruch als dies beim Analog-Fernsehen der Fall ist. Es kann mehr als eine Sekunde dauern, bis der komplizierte Synchronisationsvorgang abgeschlossen ist. Zur Wiedergabe der Bildinformation ist es notwendig, auf das Eintreffen eines I-Bildes zu warten, von dem aus die weiteren Teilbilder rekonstruiert werden. Dies alleine kann schon bis zu 0,5 s dauern. Falls die empfangenen Daten verschlüsselt sind, ist nur ein bedingter Zugriff (Conditional Access) mit Zugangsberechtigung möglich. Die Verschlüsselung kann auf der Ebene des Packetized Elementary Stream (PES) oder des Transport Stream (TS) erfolgen. Die jeweilige Header-Information (PES Header oder TS Header) bleibt unverschlüsselt. Wird aber der Transportstrom verschlüsselt oder wie später erläutert einem definierten Verwürfeln unterzogen, dann bezieht sich dies auch auf den PES Header. Die Transportstrom Header bleiben in jedem Fall unverschlüsselt.
Für die Entschlüsselung müssen im Decoder spezielle Kontrolldaten verfügbar sein, die in den Entitlement Control Messages (ECM) und in den Entitlement Management Messages (EMM) übertragen werden. Die ECM enthalten die Schlüsselcodes, mit den EMM werden die Zugriffsberechtigungen für die Empfänger verteilt. ECM und EMM werden in der Program Specific Information in den CAT oder PMT übertragen. Der Entschlüsselungsvorgang läuft in einer anbieterspezifischen Hardware ab, die über eine einheitlich definierte Schnittstelle (Common Interface) an den Decoder angeschlossen wird.
9. Übertragung des MPEG-2- Transportstroms
Die Quellencodierung und Aufbereitung des Transportstroms wird nach weltweit gültigem MPEG-2-Standard vorgenommen. Die weitere Übertragung des Transportstroms bis zum Fernsehteilnehmer erfolgt nach den Richtlinien im europäischen DVB-Standard (Digital Video Broadcasting) oder nach dem nordamerikanischen ATSC-Standard (Advanced Television System Committee), der aber gewisse Gemeinsamkeiten mit dem DVB-Standard aufweist.
Mit der Quellencodierung über die Redundanz- und Irrelevanzreduktion wurde die ursprünglich sehr hohe Datenrate des digitalen Videosignals in starkem Maß reduziert. Damit wird es aber nun anfälliger gegenüber Bitfehlern durch Störungen im Übertragungskanal. Während bei einem digitalen Video-Studiosignal ein Bitfehler im Allgemeinen nur zur Verfälschung eines Pixels führt, ist die Auswirkung beim MPEG-codierten Videosignal wesentlich gravierender und kann bis zum Ausfall eines Bildes führen, insbesondere wenn die sehr komplexe Semantik des Datenstroms betroffen wird.
Bei der Übertragung des MPEG-2-Transportstroms sind deshalb Maßnahmen zu ergreifen, die einen hohen Fehlerschutz gewährleisten. Dies wiederum kann nur dadurch erfolgen, dass im Rahmen einer Kanalcodierung wieder redundante Information eingebracht wird, deren Auswertung auf der Empfangsseite eine Fehlerkorrektur ermöglicht (Bild 9.1). Die Fehlerkorrektur muss ohne Rückgriff auf die Sendeseite erfolgen. Man spricht deshalb von Vorwärts-Fehlerkorrektur (Forward Error Correction, FEC).
Neben dem Einbringen von redundanter Information zur Gewährleistung eines Fehlerschutzes wird der Datenstrom einerweiteren Manipulation unterzogen, die aber mit dem Fehlerschutz nichts zu tun hat. Um bei einem Auftreten von längeren „0“- oder „T‘-Folgen im Datenstrom das Entstehen einer Gleichkomponente im Basisbandsignal und vor allem das damit verursachte Hervortreten des unterdrückten Trägers im Spektrum des hochfrequenten Modulationsprodukts zu vermeiden, wird eine so genannte Energieverwischung (Energy Dispersal) durch Verwürfeln (Scrambling) des Datenstroms vorgenommen.
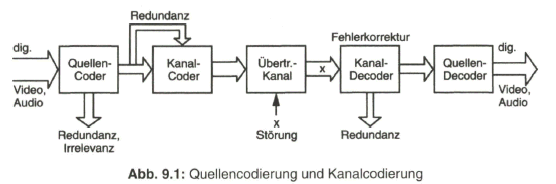
Schließlich muss zur Verteilung des Programmsignals bis zum Fernsehzuschauer eine dem jeweiligen Übertragungskanal angepasste Trägermodulation gewählt werden, um die vorgegebenen Transponderkanäle bei der Satellitenverteilung oder die Kabelkanäle sowie die terrestrischen Funkkanäle zu nutzen.
Bild 9.2 zeigt in einer Blockdarstellung die verschiedenen Maßnahmen, die auf der Sendeseite und rückgängig auf der Empfangsseite bei der Übertragung des MPEG-Datenstroms vorgenommen werden.
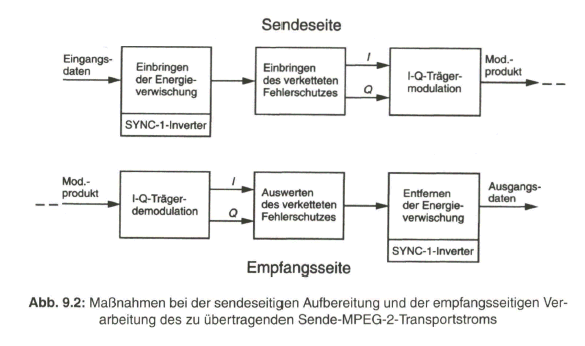
9.1 Energieverwischung
Die Transportpakete im MPEG-2-Datenstrom haben eine Länge von 188 byte, mit 4 byte im Packet Header und 184 byte für die Payload. Das erste Byte im Packet Header ist das Sync-Byte mit dem festen Bitmuster 01000111 (47 hex) (Bild 9.3). Mit Ausnahme der Sync-Bytes wird zur Energieverwischung der Datenstrom mit einer Pseudozufallsfolge (Pseudo Random Binary Sequence, PRBS) über eine Modulo-2-Verknüpfung verwürfelt.

Die Pseudozufallsfolge hat eine Generator-Polynomgleichung von
die gemäß Bild 9.4a durch eine Anordnung mit rückgekoppelten Schieberegistern technisch realisiert wird. Der Generator wird nach jeweils acht Transportpaketen neu initialisiert. Die Pseudozufallsfolge läuft so über eine Periode von (8 x 187 + 7 x 1) byte = 1503 byte.
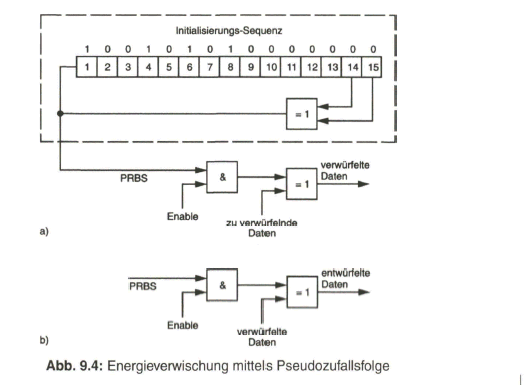
Damit auf der Empfangsseite, wo der Vorgang der Verwürfelung wieder rückgängig gemacht wird, der Entwürfler den Anfang der Pseudozufallsfolge lokalisieren kann, wird das Sync-Byte des ersten Transportpakets in der Achter-Sequenz invertiert, also mit der Folge 10111000 (B8 hex) übertragen. Die sieben anderen Sync-Bytes verbleiben mit der originalen Folge des Sync-Bytes im Datenstrom. Bild 9.5 zeigt die Transportstrompaket-Folge am Ausgang des Verwürflers.
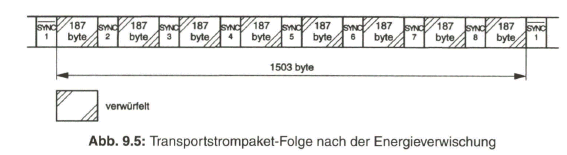
Ein Enable-Signal sorgt dafür, dass der Transport-Datenstrom während der Sync-Bytes, invertiert und nicht invertiert, auf der Sendeseite nicht verwürfelt und entsprechend auf der Empfangsseite nicht entwürfelt wird. Die Verwürfelungs-Sequenz (PRBS) ist dem Empfänger über die Polynom-Gleichung bekannt.
Die Anordnung zur Entwürfelung des Datenstroms ist ähnlich wie bei der Verwürfelung, mit dem gleichen Pseudozufalls-Generator, wie in Bild 9.4b dargestellt [8,47].
9.2 Verketteter Fehlerschutz
Im realen Übertragungskanal muss stets mit Störungen, im Wesentlichen mit einem dem Digitalsignal überlagerten Rauschen gerechnet werden. Dies kann zu einer falschen Auswertung von verschiedenen Bits führen. Die Störung kann verteilt bei einzelnen Bits auftreten - so genannte „Einzel-Bitfehler“ - oder mehrere aufeinanderfolgende Bits treffen, wobei man von einem „Bündelfehler“ oder „Burstfehler“ spricht [2].
Es gibt nun verschiedene Codiermethoden, um auftretende Bitfehler zu korrigieren, wobei in jedem Fall zusätzliche, redundante Information dem eigentlichen Datensignal hinzuzufügen ist. Die verschiedenen Codiermethoden haben unterschiedliche Effizienz bei Einzelbitfehlern oder Burstfehlern und erfordern abhängig von der auftretenden Bitfehlerhäufigkeit auch unterschiedliche Redundanz.
Damit ist es naheliegend, den gesamten Fehlerschutz auf mehrere Schritte aufzuteilen, um insgesamt mit möglichst geringer Redundanz auszukommen. Die schwer zu korrigierenden Burstfehler werden zusätzlich durch ein Umsortieren der Byte- oder Bitfolge, dem „Interleaving“, auf leichter zu korrigierende Einzel-Bytefehler oder Einzel-Bitfehler zurückgeführt.
Bild 9.6 gibt die Funktionseinheiten des so genannten verketteten Fehlerschutzes wieder, der sich aus äußerem Fehlerschutz, Byte-Interleaving und innerem Fehlerschutz zusammensetzt und in dieser Konstellation bei der Übertragung im Satellitenkanal zur Anwendung kommt.
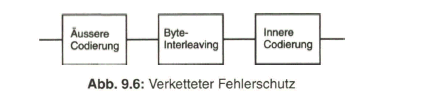
Das Ziel der Fehlerschutz-Codierung ist es, nach der Fehlerkorrektur einen „möglichst“ fehlerfreien, quasi error free (QEF) Datenstrom am Eingang des MPEG-2-Decoders zu gewährleisten. Bei Digital Video Broadcasting (DVB) geht man davon aus, dass maximal nur ein Bitfehler pro Tag auftreten soll. Das bedeutet mit einer angenommenen Nutzbitrate für ein Programm von 4 Mbit/s eine zulässige Bitfehlerhäufigkeit von ![]() .
.
Die Bitfehlerhäufigkeit (BFH) oder Bit Error Ratio (BER) gibt das Verhältnis der Anzahl von fehlerhaft empfangenen Bits zu der gesamten Anzahl von übertragenen Bits an.
9.2.1 Äußerer Fehlerschutz mit REED-SOLOMON-Blockcode
Die erste Stufe der Fehlerkorrektur betrifft die äußere Codierung, wobei sich „äußere“ Codierung auf den Eingang und Ausgang des quasi-fehlerfreien Übertragungskanals bezieht. Die nach den Entwicklern REED und SOLOMON benannten REED-SOLOMON-Codes sind leicht konstruierbar und weisen eine sehr gute Fehlerkorrekturfähigkeit, auch bei kurzen Bündelfehlern, auf [48]. REED-SOLOMON-Codes sind symbolorientierte, das heißt in der Regel auf die Byte-Folge bezogene Blockcodes. Die Fehlerauswertung muss sowohl erkennen, welches Symbol im Block mit der Länge n falsch ist, als auch das unverfälschte Symbol berechnen können [2].
Bei DVB kommt ein REED-SOLOMON-Code RS (204,188) zur Anwendung, was bedeutet, dass jeweils an ein Transportpaket mit m = 188 byte ein Block mit 16 Korrektur-Bytes angehängt wird. Das auf diese Weise mit Fehlerschutz versehene Transportpaket nimmt dann eine Länge von n = 204 byte an (Bild 9.7) [47]. Die berechnete und in dem Korrekturblock eingebrachte Redundanz ermöglicht einem REED-SOLOMON-Decoder bis zu acht fehlerhafte Bytes in diesem Transportpaket zu korrigieren. Der Code wird deshalb auch mit RS (204,188,8) bezeichnet, wobei der Wert t = 8 die Anzahl der korrigierbaren Bytes angibt. Falls mehr als acht falsche Bytes in diesem Paket auftreten, wird dies durch Setzen des Transport Error Indicator im Transport Stream Header markiert und der MPEG-Decoder wird dieses Paket nicht weiterverarbeiten. Es muss eine Fehlerverschleierung vorgenommen werden, das heißt aus benachbarten Paketen wird ein Mittelwert abgeleitet. Beim RS (204,188)-Code ist die Redundanz mit 8 % (16/ 188 x 100 %) relativ gering. Die Coderate R beträgt
R = m/n = 188/204 = 0,92.

Die Decodierung des REED-SOLOMON-Fehlerschutzcodes erfolgt nach Transformation (DFT) des gesamten Datenpakets mit n byte in den Frequenzbereich. Eine detaillierte Beschreibung ist u. a. in [2] zu finden. Die Zusammensetzung des Transportstroms bis zum Ausgang des REED-SOLOMON-Coders gibt Bild 9.8 in einer Übersichtsdarstellung wieder.
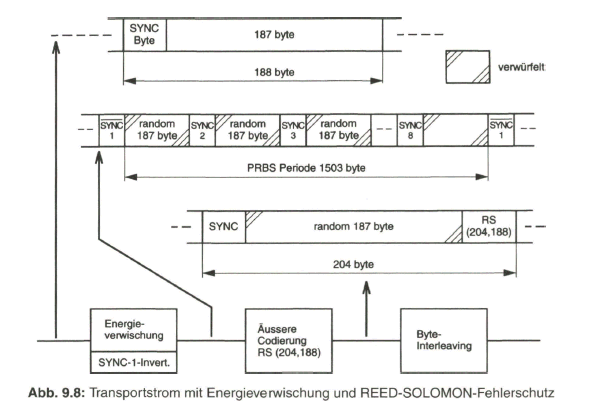
9.2.2 Byte-Interleaving
Beim Auftreten von längeren Bündelfehlern kann der REED-SOLOMON-Decoder versagen, wenn die Korrekturfähigkeit von maximal acht fehlerhaften Bytes überschritten wird. Durch ein „Spreizen“ des Bündelfehlers über einen Faltungs-Inter-leaver (Convolutional Interleaver) kann die Effektivität des REED-SOLOMON-Decoders gesteigert werden. Bei DVB wird dazu, nach ETS 300 421 [46], ein Byte-Interleaving mit einer Interleaving-Tiefe von ![]() 12, entsprechend der Anzahl der Zweige in der Interleaver- bzw. De-Interleaver-Anordnung (Bild 9.9), vorgenommen [8].
12, entsprechend der Anzahl der Zweige in der Interleaver- bzw. De-Interleaver-Anordnung (Bild 9.9), vorgenommen [8].
Mit der Länge L = 204 der Anzahl von zu schützenden Bytes und der Interleaving-Tiefe ![]() 12 ergibt sich eine Basisverzögerungseinheit von M = 204/12 = 17 für die Register, die in einer „Schalterbank“ mit zwölf Zweigen (j= 0 ... 11) die ankommenden Bytes um 0 x M bis 11 x M Byte-Takte unterschiedlich lang verzögern. Die SYNC-Bytes werden beim Interleaver immer im Zweig „0“ ohne Verzögerung weitergegeben. Jedes der aufeinanderfolgenden Bytes im Transportstrom wird so entsprechend seiner Positionsnummer um 0, 17, 34, ... 187 Positionen verzögert in den neuen Datenstrom eingeordnet.
12 ergibt sich eine Basisverzögerungseinheit von M = 204/12 = 17 für die Register, die in einer „Schalterbank“ mit zwölf Zweigen (j= 0 ... 11) die ankommenden Bytes um 0 x M bis 11 x M Byte-Takte unterschiedlich lang verzögern. Die SYNC-Bytes werden beim Interleaver immer im Zweig „0“ ohne Verzögerung weitergegeben. Jedes der aufeinanderfolgenden Bytes im Transportstrom wird so entsprechend seiner Positionsnummer um 0, 17, 34, ... 187 Positionen verzögert in den neuen Datenstrom eingeordnet.
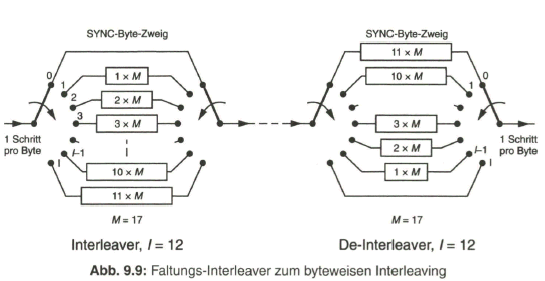
Beim De-Interleaver läuft der Prozess in ähnlicher Weise ab. Das Byte, das beim Interleaver vor der Übertragung um j x 17 Positionen, mit j = 1 ... 11 verzögert wurde, wird nun beim De-Interleaver um (11 - j) x 17 Positionen verzögert, so dass die gesamte Verzögerungszeit für alle Bytes (j + 11 - j) x 17 = 11 x 17 = 187 Positionen gleich ist und die ursprüngliche Reihenfolge wieder gilt.
Wenn jedoch ein Bündelfehler mehrere aufeinanderfolgende Bytes verfälscht, so wird die Störung nun nach dem De-Interleaver auf verstreute Positionen verteilt, was vom REED-SOLOMON-Decoder leichter korrigiert werden kann. Siehe dazu Bild 9.10
9.2.3 Innerer Fehlerschutz mit Faltungscode
Bei stark gestörten Übertragungswegen, wie im Satellitenkanal wegen des geringen Signal-zu-Rausch-Abstandes am Empfängereingang oder beim Terrestrischen Funkkanal wegen Bitverfälschungen durch Interferenzstörungen, kann die Bitfehlerhäufigkeit so hohe Werte annehmen, dass der REED-SOLOMON-Fehlerschutz alleine nicht mehr ausreichend ist. Es wird deshalb ein zusätzlicher Fehlerschutz über die Faltungscodierung eingebracht.
Beim Faltungscode wird die Information über mehrere Zeichen hinweg „verschmiert“. Die Verarbeitung erfolgt bitorientiert in der Weise, dass durch eine mehrstufige Verknüpfung des anliegenden Datenstroms mit dem über Schieberegister verzögerten Datenstrom, zwei Ausgangsdatenströme erzeugt werden, jeder mit der gleichen Bitrate wie der Eingangsdatenstrom. Die hinzugefügte Redundanz beträgt damit 100 %, was aber eine sehr effektive Fehlerkorrektur ermöglicht. Die Decodierung läuft nach einem von VITERBI angegebenen Algorithmus ab, weshalb auch vom VITERBI-Decoder gesprochen wird.
Ein einfaches Beispiel für eine Faltungscodierung zeigt Bild 9.11. Die Informationsbits des Eingangsdatenstroms c werden von links nach rechts in das Schieberegister eingelesen. Das aktuelle Bit steht dabei immer links in der ersten Zelle des Schieberegisters. Dieses aktuelle Bit wird mit den vorangegangenen Bits an den Anzapfungen des Schieberegisters modulo-2-verknüpft. Dadurch entstehen neue Codebits, die nicht nur vom aktuellen Informationsbit sondern auch von zeitlich vorangehenden Informationsbits abhängen. Die Ausgangsdatenströme x und y werden durch die Generator-Polynome G1 und G2 beschrieben. Im Fall der Anordnung nach Bild 9.11 sind dies
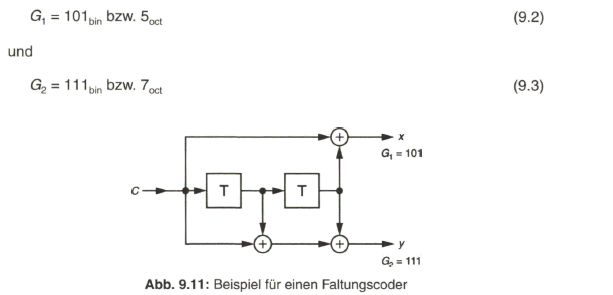
Die Generatorsummen G1 und G2 erhält man durch Zuweisen (von links nach rechts folgend) einer „1 “ für die genutzten Anzapfungen und einer „0“ für die nicht genutzten Anzapfungen. Die Binärzahl wird im Allgemeinen durch eine Oktalzahl angegeben. Die Coderate R, als Verhältnis von Eingangs- zu Ausgangs-Bitrate, beträgt bei dem dargestellten Faltungscoder R = 1/2 und die Beeinflussungslänge (Constraint Length) K, ausgedrückt durch die Anzahl der möglichen Anzapfungen, ist bei der Anordnung nach Bild 9.11 K= 3.
Die freie Distanz als ein Maß für die Korrekturfähigkeit hat in diesem Beispiel den Wert dfrei = 5. Je höher dieser Wert ist, umso effektiver ist die Korrekturfähigkeit des Codes. Der DVB-Standard gibt einen Basis-Faitungscoder mit R = 1/2 vor, wie in Bild 9.12, links, dargestellt [46]. Dieser weist eine Beeinflussungslänge von K = 7 auf, mit den Generator-Polynomen G1 = 171 oct und G2 = 133 oct. Die freie Distanz beträgt frei = 10. Die beiden Ausgangsdatenströme x und y werden mit je einem Bit zu der Symbolfolge zusammengefasst (![]() ) , die z. B. bei der QPSK mit x und y parallel auf den I- und Q-Kanal gegeben wird.
) , die z. B. bei der QPSK mit x und y parallel auf den I- und Q-Kanal gegeben wird.
Der DVB-Standard sieht aber auch vor, dass die Coderate am Ausgang des Faltungscoders durch eine Punktierung (Bild 9.12, rechts) erhöht werden kann, allerdings auf Kosten der Effizienz der Fehlerkorrektur. Je nach den Eigenschaften des vorliegenden Übertragungskanals wird man aber zwischen einer besseren Ausnutzung der Übertragungskapazität vom eigentlichen Nutzsignal her und einem Verlust an Codier-Effizienz abwägen [2, 8]. Bei der Punktierung werden nicht alle aufeinanderfolgenden Bits der beiden Datenströme X und Y weitergegeben, sondern je nach dem Punktierungs-Verhältnis nur eines von zwei gleichzeitig in den Datenströmen X und Y auftretenden Bits.
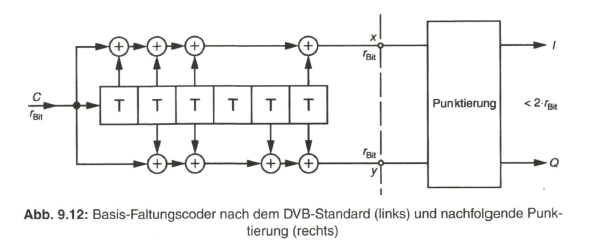
Das Punktierungsverhältnis drückt die Anzahl der Bits nach der Punktierung zu der Anzahl der Bits vor der Punktierung aus. Die verbleibenden Bits werden so umsortiert, dass in jedem der beiden parallelen Datenströme I und Q gleich viele Bits aus der ursprünglichen Konstellation übernommen werden. Die neue Coderate ergibt sich nun aus der Multiplikation der Basis-Coderate von R = 1/2 mit dem reziproken Punktierungsverhältnis.
Bild 9.13 gibt die nach dem DVB-Standard möglichen Punktierungen mit der dem Ausgangsdatenstrom I und Q zugeordneten Coderate R wieder.
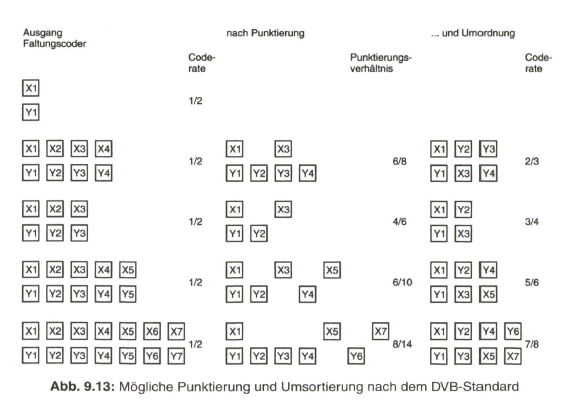
Nach den DVB-Vereinbarungen wird im Satellitenkanal bei der Faltungscodierung mit einer Coderate R = 3/4 und im terrestrischen Funkkanal mit R = 2/3 gearbeitet. Im Kabelkanal entfällt die Faltungscodierung. Die Auswertung des mit dem Faltungscode übertragenen Datensignals erfolgt in den meisten Fällen mit dem VITERBI-Algohthmus. Die Grundidee besteht darin, aus den aufeinanderfolgend empfangenen Bit-Kombinationen aus den beiden Kanälen mittels eines so genannten Trellis-Diagramms sukzessive die optimale Route zu finden, bis zu der Bit-Kombination, welche die höchste Wahrscheinlichkeit der Übereinstimmung mit dem gesendeten Signal aufweist. Das Ergebnis, das mit der größten Wahrscheinlichkeit zu erwarten ist, wird als decodierter Wert übernommen. Eine genaue Erklärung dieses Ablaufs wäre zu umfangreich. Es wird deshalb auf detaillierte Literatur verwiesen [2, 48, 49, 50].
Die Berechnung nach dem VITERBI-Algorithmus lässt sich noch verbessern, indem die Wahrscheinlichkeit auch Zwischenwerte berücksichtigt, die über fiktive Entscheiderschwellen gewonnen werden. Eine derart flexible Berechnung im VITERBI-Decoder ist das Merkmal der Soft-Decision-Decodierung. Gegenüber der Hard-Decision-Decodierung mit nur einer Entscheiderschwelle zwischen „0“ und „1“ ist ein Gewinn von etwa 2 dB beim Signal-zu-Rausch-Abstand möglich [49].
9.2.4 Effektivität der Fehlerkorrektur
Am Beispiel der Satellitenübertragung (Bild 9.14a) bzw. der Kabelübertragung (Bild 9.14b) wird die Wirksamkeit der Fehlerkorrektur-Maßnahmen bei den realen Systemen demonstriert. Die Übertragung des MPEG-2-Transportstroms erfolgt im Satellitenkanal durch 4-Phasenumtastung (Quadrature Phase Shift Keying, QPSK). In einem Satellitenkanal mit 33 MHz Bandbreite kann mit QPSK ein Brutto-Datenstrom von 55 Mbit/s übertragen werden. Am QPSK-Demodulator sollte ein Träger-zu-Rausch-Abstand von C/N > 7 dB vorliegen. Die dabei zu erwartende Bitfehlerhäufigkeit liegt bei BER ![]() . Der VITERBI-Decoder setzt diesen Wert auf etwa
. Der VITERBI-Decoder setzt diesen Wert auf etwa ![]()
![]() herab. Nach Auswertung des REED-SOLOMON-Fehlerschutzes wird eine Bitfehlerhäufigkeit BER
herab. Nach Auswertung des REED-SOLOMON-Fehlerschutzes wird eine Bitfehlerhäufigkeit BER ![]() erreicht, was einem quasi-fehlerfreien Signal entspricht.
erreicht, was einem quasi-fehlerfreien Signal entspricht.
Bei der Übertragung im Kabelverteilkanal mit einer Bandbreite von 8 MHz kommt 64-QAPSK (Quadratur Amplitude Phase Shift Keying) zur Anwendung. Für eine Bitfehlerhäufigkeit von BER < ![]() sollte der Träger-zu-Rausch-Abstand am Demodulator C/N > 26 dB sein. Der nachfolgende REED-SOLOMON-Decoder setzt die Bitfehlerhäufigkeit wieder auf BER
sollte der Träger-zu-Rausch-Abstand am Demodulator C/N > 26 dB sein. Der nachfolgende REED-SOLOMON-Decoder setzt die Bitfehlerhäufigkeit wieder auf BER ![]() herab.
herab.
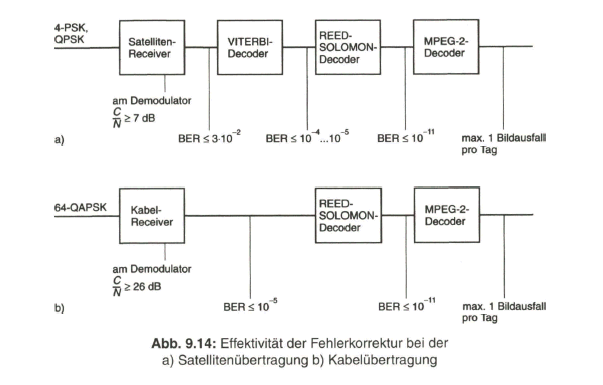
9.3 Trägermodulation
Die Verteilung des Programmsignals zum Fernsehteilnehmer erfolgt in vorgegebenen Funk- oder Kabel-Kanälen durch Aufbringen des MPEG-2-Transport-stroms auf eine hochfrequente Trägerschwingung. Es kommen Verfahren der digitalen Trägermodulation zur Anwendung, wo zwei orthogonale Komponenten der Trägerschwingung, eine Cosinus- bzw. In-Phase-Komponente (I) und eine Sinus- bzw. Quadratur-Komponente (Q), von jeweils einem Anteil des Datenstroms moduliert werden. Man spricht in diesem Fall generell von Quadraturmodulation (QAM) oder I-Q-Modulation. Das Modulationsprodukt kann dabei die Information nur in den Phasenzuständen der aus den beiden modulierten Komponenten zusammengesetzten Trägerschwingung enthalten sein. In diesem Fall liegt eine „digitale Phasenmodulation“ vor, die im Folgenden als Phasenumtastung (Phase Shift Keying, PSK) bezeichnet wird.
Entsprechend den n möglichen Phasenzuständen, die einem n-wertigen Symbol zugeordnet werden, das wiederum aus einem N-stelligen binären Codewort abgeleitet ist, mit der Beziehung n = 2N, spricht man von Bedeutung beim Digitalen Fernsehen im Satellitenkanal nach dem DVB- Standard ETS 300 421 ist die 4-stufige Phasenumtastung, 4-PSK. Vielfach wird dazu auch in der deutschen Literatur der englischsprachige Ausdruck Quadratur Phase Shift Keying, QPSK verwendet. Werden die beiden Komponenten der Trägerschwingung sowohl in der Phase mit den Zuständen 0° bzw. 180° bei der Cosinus-Komponente und 90° bzw. 270° bei der Sinus-Komponente als auch in diskreten Amplitudenzuständen von den n-wertigen Symbolen des Datensignals moduliert, dann liegt eine n-stufige Quadraturmodulation (n-QAM) oder n-stufige Amplituden-Phasen-Umtastung vor. Auch hier wird vielfach der englischsprachige Ausdruck verwendet: Quadratur Amplitude Phase Shift Keying (QAPSK).
Der DVB-Standard sieht die Anwendung von 16-QAPSK, 32-QAPSK oder 64- QAPSK bei der Kabelübertragung (ETS 300 429) bzw. von 16-QAPSK oder 64- QAPSK im Terrestrischen Funkkanal (ETS 300 744) vor. Nach den DVB-Festlegungen kommt im Kabelkanal die 64-QAPSK zur Anwendung, während im terrestrischen Funkkanal der Datenstrom mit der weniger störanfälligen 16-QAPSK übertragen wird, allerdings hier in Verbindung mit einer Mehrträgermodulation (OFDM). Die verschiedenen Modulationsarten lassen sich auf einen Funktionsblock „l-Q-Modulation“ zurückführen, dem die beiden modulierenden Codesignale I und Q zugeführt werden (Bild 9.15). Diese „entstammen“ aus dem Faltungscoder oder aus dem REED-SOLOMON-Coder mit dem nachfolgenden Interleaver, nach Serien-Parallel-Wandlung auf zwei Datenkanäle. In jedem Fall werden die Datensignale vor dem Modulator über eine Basisband-Tiefpass-Filterung impulsgeformt und damit in ihrem Spektrum begrenzt. Näheres dazu in Abschnitt 10.2.
Die Aufbereitung des Modulationsprodukts erfolgt vielfach über digitale Signalverarbeitung, womit auf einfache Weise über eine Software-Änderung eine Umschaltung auf verschiedene Modulationsarten möglich wäre. Die Entscheidung für ein Verfahren der digitalen Trägermodulation wird auf Grund folgender Vorgaben getroffen:
• zu übertragende Datenrate
• verfügbare Bandbreite des Übertragungskanals
• zu erwartender Störeinfluss.
Der Störeinfluss kann einerseits
• durch den Träger-zu-Rausch-Abstand am Empfängereingang und andererseits
• durch Interferenzstörungen, z. B. auf Grund von Reflexionen beim Kabelanschluss oder wegen Mehrwegeempfang oder Selektivschwund beim terrestrischen Fernsehen bedingt sein.
Letztgenannten Störeinflüssen begegnet man zusätzlich durch den Übergang von der Ein-Träger-Modulation auf die Mehr-Träger-Modulation und Anwendung des OFDM-Verfahrens (Orthogonal Frequency Division Multiplex).
Nähere Ausführungen zu den digitalen Modulationsverfahren folgen in Abschnitt 10.
10. Digitale Trägermodulation
Bei der „Modulation“ einer hochfrequenten Trägerschwingung mit einem Basisbandsignal besteht prinzipiell kein Unterschied zwischen dem Aufbringen eines analogen Informationssignals oder eines digitalen Datensignals. Beim analogen Signal kann im Allgemeinen von einem zeit- und wertkontinuierlichen Vorgang mit begrenztem Spektrum ausgegangen werden. Dagegen handelt es sich bei dem digitalen Signal um einen zeit- und wertdiskreten Ablauf, womit die Änderung des modulierten Parameters der Trägerschwingung in festen Zeitintervallen und mit vorgegebenen Stufen erfolgt. Der Ausdruck „Modulation“ wird deshalb bei digital modulierenden Signalen durch den Begriff „Tastung“ ersetzt.
10.1 Mögliche Trägertastverfahren
Ähnlich den bekannten analogen Modulationsverfahren wie
• Amplitudenmodulation (AM),
• Frequenzmodulation (FM),
• Phasenmodulation (PM) und
• Quadraturamplitudenmodulation (QAM), als Amplitudenmodulation mit unterdrücktem Träger auf einer Cosinus- und einer Sinus-Trägerkomponente
gibt es die entsprechenden Äquivalente bei den digitalen Modulationsverfahren, wobei man nun von „Tastung“ bzw. genauer ausgedrückt von einer „Umtastung“ des Trägerparameters spricht.
Man kommt so zur
• Amplitudenumtastung,
• Frequenzumtastung,
• Phasenumtastung und
• Quadratur-Amplituden-Phasenumtastung (Quadraturmodulation), als Amplitudenumtastung mit unterdrücktem Träger auf einer Cosinus- und einer Sinus-Trägerkomponente.
Die dazu gehörigen Kurzbezeichnungen fehlen, weil schon sehr bald die englischsprachigen Begriffe, zumindest mit ihren Kurzbezeichnungen, im deutschen Sprachgebrauch übernommen wurden. Deshalb sind die Bezeichnungen üblich.
• Amplitude Shift Keying (ASK),
• Frequency Shift Keying (FSK),
• Phase Shift Keying (PSK) und
• Quadratur Amplitude Phase Shift Keying (QAPSK).
Von Bedeutung beim Digitalen Fernsehen DVB in Europa sind die Verfahren der Phasenumtastung, insbesondere 4-PSK, und die Quadratur-Amplituden-Phasenumtastung mit 16-QAPSK und 64-QAPSK. Eine Amplitudenumtastung findet sich beim US-ATSC-Standard mit 8-ASK und Restseitenbandübertragung (8-VSB, Vestigial Sideband). Außerdem sieht der US-J.83/A/C-Standard bei Kabelübertragung auch 128- und 256-QAPSK vor [51].
10.2 Basisband-Filterung
Das modulierende, digitale Datensignal setzt sich aus einer Folge von „0“- und „1 Bits zusammen. Mehrere Bits können dabei zu einem Symbol zusammengefasst werden. So leiten sich aus zwei aufeinanderfolgenden Bits jeweils 4-wertige Symbole, vier aufeinanderfolgenden Bits jeweils 16-wertige Symbole und sechs aufeinanderfolgenden Bits jeweils 64-stufige Symbole ab. Das Spektrum der binären Datenfolge, wie auch der mehrstufigen Symbolfolgen, reicht theoretisch von der Frequenz Null (Gleichkomponente bei unipolaren Signalen) bis zu Unendlich. Wenn auch die Intensität der Spektralkomponenten im Groben mit einer 1/f-Funktion abklingt, so wird es aus frequenzökonomischen Gründen doch erforderlich sein, eine Begrenzung des Spektrums des Datensignals auf einen für die Auswertbarkeit mindest notwendigen Bereich vorzunehmen.
Das Spektrum eines zufälligen Datensignals erhält man über eine FOURIER-Transformation der Zeitfunktion des Codesignals c(t) in die Frequenzfunktion g(f). Es ist aber auch eine pragmatische Ableitung möglich. Bei dieser Herleitung wird von einem periodischen Rechtecksignal s(t) mit der Periodendauer ![]() und der Impulsdauer
und der Impulsdauer ![]() rausgegangen. An die Stelle der FOURIER-Transformation tritt bei periodischen Signalen die FOURIER-Reihenentwicklung zur Berechnung der Spektralkoeffizienten. Die Amplitude der Spektralkomponenten
rausgegangen. An die Stelle der FOURIER-Transformation tritt bei periodischen Signalen die FOURIER-Reihenentwicklung zur Berechnung der Spektralkoeffizienten. Die Amplitude der Spektralkomponenten ![]() und damit auch die Einhüllende zu den Spektralkomponenten wird durch den Betrag der si(x)-Funktion bestimmt, mit
und damit auch die Einhüllende zu den Spektralkomponenten wird durch den Betrag der si(x)-Funktion bestimmt, mit
si(x) = (sin x)/xund dem Argument ![]() wobei wertmäßig gilt
wobei wertmäßig gilt

Nullstellen im Spektrum treten bei den Frequenzen ![]() auf. An die Stelle der Impulsdauer tritt nun die Bitdauer
auf. An die Stelle der Impulsdauer tritt nun die Bitdauer ![]() .
.
Bild 10.1 a zeigt dazu als Erstes die Zeitfunktion eines periodischen 1-O-Datensignals und einen Ausschnitt des Amplitudenspektrums. Die erste Harmonische aus dem schnellstmöglichen Zustandswechsel, hier also aus einer Periode ![]() wird als NYQUIST-Frequenz fN bezeichnet. Die Nullstellen im Spektrum liegen bei
wird als NYQUIST-Frequenz fN bezeichnet. Die Nullstellen im Spektrum liegen bei ![]()
Nach dem 1. NYQUIST-Theorem muss für die eindeutige Erkennung der Symbolfolge das Spektrum eines Datensignals mindestens bis zur NYQUIST-Frequenz übertragen werden.
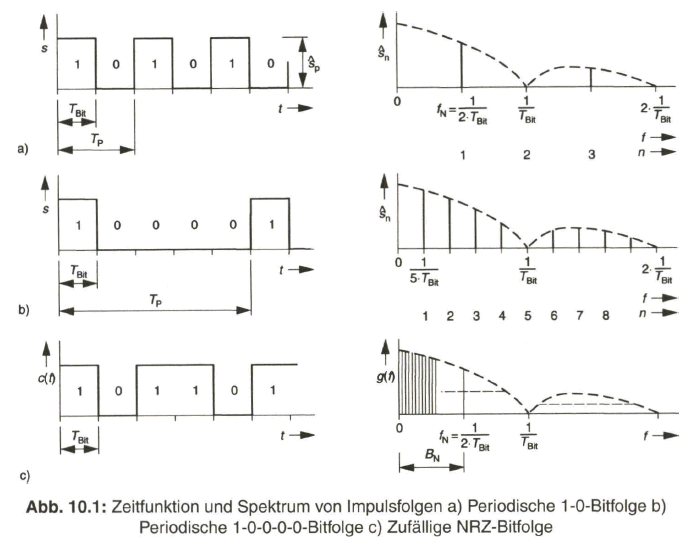
Als Nächstes gibt Bild 10.1b die Zeitfunktion und das Spektrum einer periodischen 1-0-0-0-0-Bitfolge wieder. Die Periodendauer beträgt nun ![]() und die erste Harmonische aus dieser Periode, die NYQUIST-Frequenz fN, liegt bei einer Frequenz f = 1/5 - TBit. Die Nullstellen im Spektrum bleiben aber weiter bei
und die erste Harmonische aus dieser Periode, die NYQUIST-Frequenz fN, liegt bei einer Frequenz f = 1/5 - TBit. Die Nullstellen im Spektrum bleiben aber weiter bei ![]() .
.
Schließlich wird in Bild 10.1c eine fortlaufend zufällige Bitfolge aus einem NRZ-Datensignal angenommen. Man könnte durch Variieren des Tastverhältnisses von periodischen Bitfolgen demonstrieren, dass letztendlich beim Übergang zu einer unendlichen Periodendauer ein kontinuierliches Spektrum mit den im Abstand gegen Null aufeinanderfolgenden Spektrallinien auftritt. Die Einhüllende zu den Spektralkomponenten bleibt weiterhin die Betrag-si(x)-Funktion mit Nullstellen bei fN = n ■ 1/TBit. Die NYQUIST-Frequenz des Datensignals liegt bei fN = 1/2 -TBit. Eine NYQUIST-Bandbreite BN erstreckt sich von f=0 bis fN.
Das Spektrum des Datensignals ändert sich nicht, außer dem Wegfall der Gleichspannungskomponente, wenn an Stelle des unipolaren NRZ-Signals ein bipolares NRZ-Signal angenommen wird. Nach dem 1. NYQUIST-Theorem kann eine Begrenzung des Spektrums auf die NYQUIST-Bandbreite vorgenommen werden. Die Bandbegrenzung hat aber eine Signalverzerrung in der Zeitfunktion zur Folge, wie in Bild 10.2 an einer simulierten Bitfolge zu erkennen ist. Trotzdem kann aus dem verzerrten Datensignal durch Abtasten der Momentanwerte jeweils in der Bitmitte eine eindeutige Schwellenentscheidung getroffen werden. Auf Grund der nicht mehr voll ausnutzbaren Amplitude wird bei Überlagerung eines Störsignals aber nun eher mit Bitfehlern zu rechnen sein.
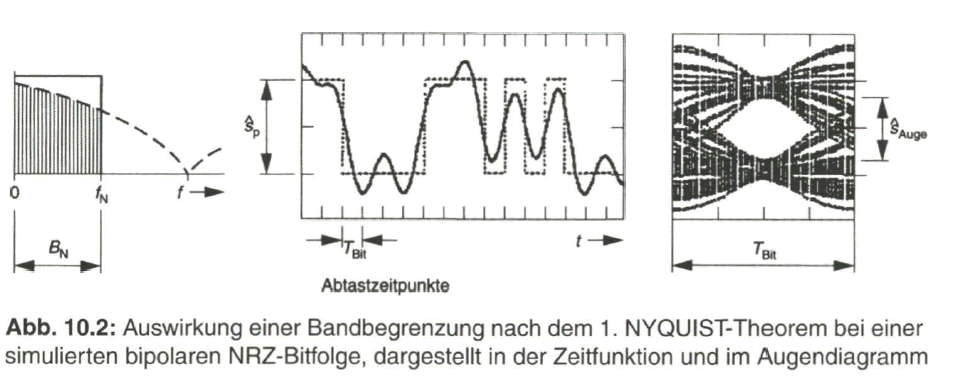
Eine sehr anschauliche Darstellung zur Auswertbarkeit des verzerrten Datensignals liefert das Augendiagramm. Man erhält dieses durch laufendes Übereinanderschreiben des Signalverlaufs während der Bitdauer ![]() mittels Oszilloskop. Das Oszilloskop wird dabei vom Bit-Takt getriggert. In Bild 10.2 ist das aus der simulierten Bitfolge abgeleitete Augendiagramm wiedergegeben. Man erkennt eine vertikale Augenöffnung sAuge und eine horizontale Augenöffnung
mittels Oszilloskop. Das Oszilloskop wird dabei vom Bit-Takt getriggert. In Bild 10.2 ist das aus der simulierten Bitfolge abgeleitete Augendiagramm wiedergegeben. Man erkennt eine vertikale Augenöffnung sAuge und eine horizontale Augenöffnung ![]() . Je näher die relative vertikale Augenöffnung
. Je näher die relative vertikale Augenöffnung ![]() gegen eins geht, umso eindeutiger wird die Schwellenentscheidung. Aber auch die horizontale Augenöffnung TAuge sollte möglichst groß sein, d. h. an
gegen eins geht, umso eindeutiger wird die Schwellenentscheidung. Aber auch die horizontale Augenöffnung TAuge sollte möglichst groß sein, d. h. an ![]() herankommen, um eine Sicherheit gegen Schwankungen beim Abtast-Takt zu gewährleisten.
herankommen, um eine Sicherheit gegen Schwankungen beim Abtast-Takt zu gewährleisten.
Nach der 1. NYQUIST-Bedingung kann das Spektrum des Datensignals „hart“, d. h. steil abfallend, auf den Bereich bis zur NYQUIST-Frequenz begrenzt werden. Eine starke Impulsverzerrung ist die Folge. Gemäß dem 2. NYQUIST-Theorem kann die Begrenzung des Spektrums aber auch flach erfolgen, wenn der Übertragungsfaktor H, d.h. der Betrag aus der Übertragungsfunktion ![]() , symmetrisch zu dem 50%-Wert bei der NYQUIST-Frequenz abfällt. Nachdem eine Übertragungsfunktion mit Knickstellen im Verlauf nicht möglich ist, führt das zu einem kontinuierlichen Übergang und man spricht von dem Roll-Off-Filter. Ein typischer und vielfach zur Anwendung kommender Verlauf des Übertragungsfaktors ist cosinus- bzw. cosinusquadratförmig, je nach Bezug auf das Argument der Funktion. Der Bereich des „Abrollens“, mit
, symmetrisch zu dem 50%-Wert bei der NYQUIST-Frequenz abfällt. Nachdem eine Übertragungsfunktion mit Knickstellen im Verlauf nicht möglich ist, führt das zu einem kontinuierlichen Übergang und man spricht von dem Roll-Off-Filter. Ein typischer und vielfach zur Anwendung kommender Verlauf des Übertragungsfaktors ist cosinus- bzw. cosinusquadratförmig, je nach Bezug auf das Argument der Funktion. Der Bereich des „Abrollens“, mit ![]() unterhalb und
unterhalb und ![]() oberhalb der NYQUIST-Frequenz fN wird über den Roll-Off-Faktor r mit
oberhalb der NYQUIST-Frequenz fN wird über den Roll-Off-Faktor r mit
![]()
angegeben.
Der Roll-Off-Faktor r liegt zwischen dem Wert Null (harte Bandbegrenzung) und eins (flacher Übergang). Der Übertragungsfaktor H(f) berechnet sich bei cosinusquadratförmigem Roll-Off mit dem Parameter ![]()

Wegen der vom Wert Null aus um den Betrag 0,5 „angehobenen“ Cosinus-Funktion spricht man im Englischen vom Raised-Cosine-Filterverlauf.
Bild 10.3 gibt den Verlauf des Übertragungsfaktors H(f) bei cos2-Roll-Off mit r-0,5 und r= 1 sowie die Systemreaktion g (f) bei Anregung dieses Tiefpassfilters durch einen DIRAC-Impuls, mit konstanter spektraler Leistungsdichte bis ![]() , wieder. Das Überschwingen würde bei harter Bandbegrenzung (r= 0) maximal 22 % betragen, es geht bei vollkommen flachem Übergang (r - 1) auf etwa 1,5 % zurück.
, wieder. Das Überschwingen würde bei harter Bandbegrenzung (r= 0) maximal 22 % betragen, es geht bei vollkommen flachem Übergang (r - 1) auf etwa 1,5 % zurück.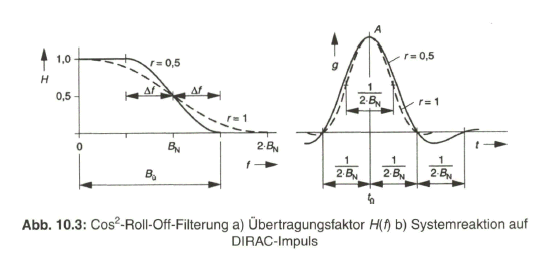
Die notwendige Übertragungsbandbreite ![]() für das begrenzte Spektrum ergibt sich zu
für das begrenzte Spektrum ergibt sich zu

Die Auswirkung der cos2-Roll-Off-Filterung auf den zeitlichen Verlauf der simulierten Bitfolge bzw. auf das daraus abgeleitete Augendiagramm gibt Bild 10.4 bei einem Roll-Off-Faktor von r= 0,5 wieder. Dabei wird von einer bipolaren DIRAC-Impulsfolge ausgegangen, die durch Abtasten des bipolaren NRZ-Signals (siehe Bild 10.2) gewonnen wird.
Im Augendiagramm ist zu erkennen, dass die vertikale Augenöffnung nun optimal ist, was auf die DIRAC-Impulsfolge zurückzuführen ist. Die horizontale Augenöffnung ist umso größer, je mehr der Wert des Roll-Off-Faktors an r=1 kommt.
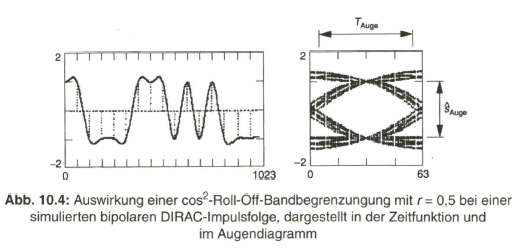
Die Roll-Off-Filterung bezieht sich auf den gesamten Übertragungskanal vom Eingang des Modulators auf der Sendeseite bis zum Ausgang des Demodulators auf der Empfangsseite. Nachdem sowohl auf der Sendeseite eine Tiefpass-Filterung zur Begrenzung des Spektrums am Ausgang des Modulators, als auch auf der Empfangsseite nach dem Demodulator ein Tiefpass zur Unterdrückung von unerwünschten Demodulationsprodukten und vor allem von Rauschen notwendig ist, bietet es sich an, die cos2-Übertragungsfunktion aufzuteilen in
• einen Tiefpass mit Wurzel-co2-Übertragungsfunktion ![]() vor dem Modulator und
vor dem Modulator und
• einen Tiefpass mit Wurzel-cos2-Übertragungsfunktion ![]() nach dem Demodulator.
nach dem Demodulator.
Die für das System gültige resultierende Übertragungsfunktion ist dann

Bild 10.5 zeigt dazu den Verlauf der ![]() -Roll-Off- und der Wurzel-
-Roll-Off- und der Wurzel-![]() -Roll-Off- Funktion bei einem Roll-Off-Faktor von r= 0,35. Dieser Wert liegt im Satellitenkanal vor [46].
-Roll-Off- Funktion bei einem Roll-Off-Faktor von r= 0,35. Dieser Wert liegt im Satellitenkanal vor [46].
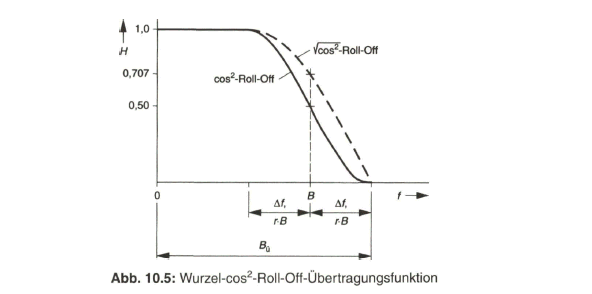
10.3 Phasenumtastung und Quadratur-Amplituden-Phasenumtastung
Im Folgenden werden die wichtigsten Verfahren der Phasenumtastung und der Quadratur-Amplituden-Phasenumtastung näher beschrieben mit der Aufbereitung und Demodulation des Modulationsprodukts sowie dem Bandbreitebedarf und der Empfindlichkeit gegenüber Rauschstörungen.
10.3.1 2-Phasenumtastung (2-PSK, BPSK)
Die 2-Phasenumtastung, engl. Binary Phase Shift Keying (BPSK), hat zwar keine direkte Bedeutung beim digitalen Fernsehen, sie bildet aber die Grundlage für die weiteren höhenwertigen Trägertastverfahren. Zur Erzeugung des Modulationsprodukts wird mittels eines Multiplizierers die Phase der Trägerschwingung, bezogen auf einen Ausgangswert 0°, von dem bipolaren Datensignal c(t) so eingestellt, dass z. B. bei Anliegen einer „0“ die Phasenlage 0° ![]() beibehalten wird und bei Anliegen einer „1“ die Phasenlage um 180° gedreht wird
beibehalten wird und bei Anliegen einer „1“ die Phasenlage um 180° gedreht wird ![]() . Man spricht in diesem Fall von Absolutphasencodierung. Bild 10.6a zeigt dies zusammen mit dem Vektor- oder Zeigerdiagramm.
. Man spricht in diesem Fall von Absolutphasencodierung. Bild 10.6a zeigt dies zusammen mit dem Vektor- oder Zeigerdiagramm.
Das Spektrum des Datensignals c(f) bzw. des über einen Roll-Off-Tiefpass begrenzten Spektrums wird durch die Multiplikation mit der Trägerschwingung aus der Frequenzlage um Null - im mathematischen Sinn mit positiven und negativen Frequenzen - in die Frequenzlage um die Trägerfrequenz fT umgesetzt (Bild 10.6b).
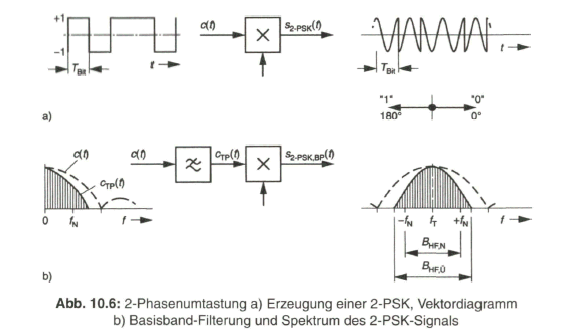
Die notwendige Übertragungsbandbreite im Trägerfrequenzbereich kann nun durch die mindest notwendige NYQUIST-Bandbreite ![]() bzw. mit der tatsächlich notwendigen Bandbreite
bzw. mit der tatsächlich notwendigen Bandbreite ![]() unter Bezugnahme auf die Bitfolgefrequenz
unter Bezugnahme auf die Bitfolgefrequenz ![]()

angegeben werden.
Die Trägerkomponente selbst ist unterdrückt, wenn davon ausgegangen werden kann, dass das Datensignal c(t) gleichspannungsfrei ist, d. h. im Mittel gleich viele „T‘- und „0“-Bits auftreten. Zur Rückgewinnung des übertragenen Datensignals auf der Empfängerseite ist eine Synchrondemodulation erforderlich. Das Modulationsprodukt ![]() muss dazu mit der Trägerschwingung mit dem ursprünglichen Phasenwinkel 0° multipliziert werden, die aber nicht übertragen wird. Es ist eine Trägerrückgewinnung notwendig. Dazu wird das Modulationsprodukt
muss dazu mit der Trägerschwingung mit dem ursprünglichen Phasenwinkel 0° multipliziert werden, die aber nicht übertragen wird. Es ist eine Trägerrückgewinnung notwendig. Dazu wird das Modulationsprodukt ![]() das als + cos
das als + cos ![]() oder - cos
oder - cos  erscheint, quadriert, d. h. mit sich selbst multipliziert. Man erhält eine durchlaufende Schwingung mit der 2-fachen Trägerfrequenz. Über eine Frequenzteilung 2:1 gewinnt man eine Rechteckschwingung mit der Trägerfrequenz
erscheint, quadriert, d. h. mit sich selbst multipliziert. Man erhält eine durchlaufende Schwingung mit der 2-fachen Trägerfrequenz. Über eine Frequenzteilung 2:1 gewinnt man eine Rechteckschwingung mit der Trägerfrequenz ![]() , allerdings mit einer nicht eindeutigen Phasenlage. Je nach Abgriff am I- oder Q-Ausgang des Untersetzers liegt die Phasenlage 0° oder 180° vor. Zur Synchrondemodulation ist aber die frequenz- und phasenrichtige Trägerschwingung erforderlich, um das Original-Datensignal zu erhalten. Bei falscher Referenzphase würde das übertragene Datensignal invertiert erscheinen. Bei der Absolutphasencodierung wird deshalb zusätzlich ein „Kennungssignal“ übertragen, das nach dem Frequenzteiler die korrekte Trägerphase einstellt (Bild 10.7).
, allerdings mit einer nicht eindeutigen Phasenlage. Je nach Abgriff am I- oder Q-Ausgang des Untersetzers liegt die Phasenlage 0° oder 180° vor. Zur Synchrondemodulation ist aber die frequenz- und phasenrichtige Trägerschwingung erforderlich, um das Original-Datensignal zu erhalten. Bei falscher Referenzphase würde das übertragene Datensignal invertiert erscheinen. Bei der Absolutphasencodierung wird deshalb zusätzlich ein „Kennungssignal“ übertragen, das nach dem Frequenzteiler die korrekte Trägerphase einstellt (Bild 10.7).
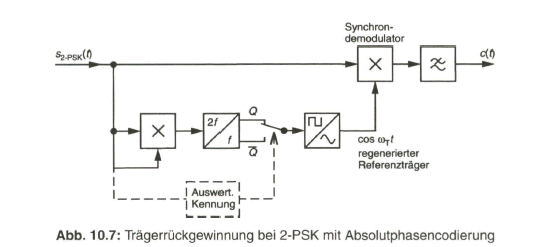
Bei der 2-Phasenumtastung wird die Absolutphasencodierung kaum angewandt. Vielmehr bietet sich über die Phasendifferenzcodierung die Möglichkeit, von der Absolutphase des Referenzträgers bei der Synchrondemodulation unabhängig zu sein. Das Datensignal c(f) wird dabei in einem Phasensummenrechner so aufbereitet, dass z. B. bei Vorliegen einer „1“ die momentane Phase der Trägerschwingung beibehalten wird und beim Auftreten einer „0“ ein Phasensprung um 180° erfolgt. Übertragen wird das phasendifferenzcodierte Signal ![]() in dem Modulationsprodukt der 2-DPSK oder Differential Binary Phase Shift Keying (DBPSK).
in dem Modulationsprodukt der 2-DPSK oder Differential Binary Phase Shift Keying (DBPSK).
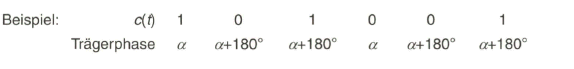
Zur Synchrondemodulation kann nun der regenerierte Referenzträger mit 0° oder 180° Phase zugeführt werden. Das demodulierte Signal ![]() , nicht invertiert oder invertiert, wird einem Phasendifferenzrechner zugeführt, an dessen Ausgang das ursprüngliche Datensignal c(t) anliegt (Bild 10.8).
, nicht invertiert oder invertiert, wird einem Phasendifferenzrechner zugeführt, an dessen Ausgang das ursprüngliche Datensignal c(t) anliegt (Bild 10.8).
10.3.2 4-Phasenumtastung (4-PSK, QPSK)
Durch Zusammenfassen von jeweils zwei aufeinanderfolgenden Bits gewinnt man 4-wertige Signalelemente, Symbole, deren vier mögliche Zustände in vier Phasenzustände der Trägerschwingung umgesetzt werden. Man erhält diese durch eine vektorielle Addition der Modulationsprodukte einer 2-PSK mit 0°-Phase der zugeführten Trägerschwingung und einer 2-PSK mit 90°-Phase der zugeführten Trägerschwingung. Dazu wird das binäre NRZ-Datensignal über eine Serien-Parallel-Wandlung in zwei parallele Dibit-Signale mit einer Schrittdauer von jeweils 2 ![]() aufgeteilt. Die Dibit-Signale werden nach Roll-Off-Tiefpass-Filterung als modulierende
aufgeteilt. Die Dibit-Signale werden nach Roll-Off-Tiefpass-Filterung als modulierende ![]() und
und ![]() Signale an die beiden 2-PSK-Modulatoren angelegt. Im Vektordiagramm werden den vier möglichen Phasenlagen bei der 4-PSK bzw. Quaternary Phase Shift Keying (QPSK) jeweils 2-Bit-Kombinationen zugeordnet. Vielfach gibt man, insbesondere bei höherwertigen Trägertastverfahren, nur noch die Vektorendpunkte in dem Zustandsdiagramm oder constellation diagram an. Siehe dazu Bild 10.9.
Signale an die beiden 2-PSK-Modulatoren angelegt. Im Vektordiagramm werden den vier möglichen Phasenlagen bei der 4-PSK bzw. Quaternary Phase Shift Keying (QPSK) jeweils 2-Bit-Kombinationen zugeordnet. Vielfach gibt man, insbesondere bei höherwertigen Trägertastverfahren, nur noch die Vektorendpunkte in dem Zustandsdiagramm oder constellation diagram an. Siehe dazu Bild 10.9.
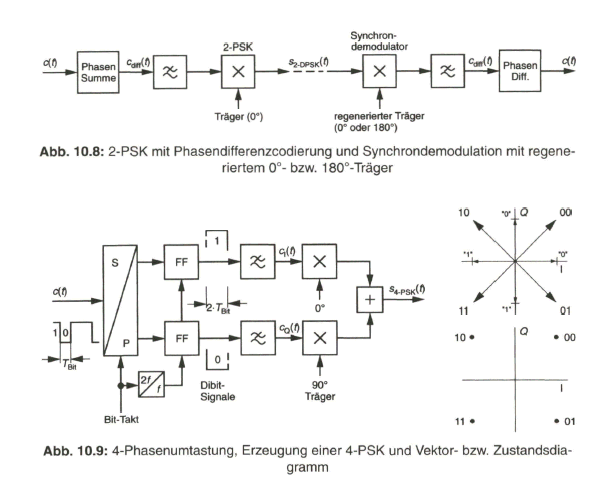
Das Spektrum des 4-PSK-Modulationsprodukts belegt nun wegen der gegenüber 2-PSK doppelten Schrittdauer nur noch den halben Frequenzbereich. Die für die Datenübertragung erforderliche Bandbreite ist
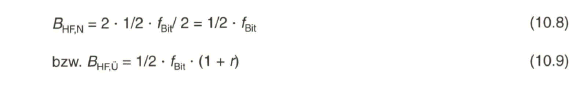
Zur Rückgewinnung des übertragenen Datensignals c(t) ist wieder Synchrondemodulation mit einem 0°- und einem 90°-Referenzträger notwendig. Die Trägerrückgewinnung erfordert nun ein zweimaliges Quadrieren des Modulationsprodukts, um die 90°-Phasensprünge zu beseitigen, und eine Frequenzteilung von 4:1. Dabei tritt erneut das Problem der Mehrdeutigkeit der Phase des Referenzträgers, hier mit n= 90°-Schritten, auf. Aus den demodulierten Dibit-Signalen wird über eine Parallel-Serien-Wandlung das übertragene Datensignal c(t) zurückgewonnen.
Bei der Trägerrückgewinnung und Synchrondemodulation kommt vielfach die so genannte COSTAS-Schleife zum Einsatz [51]. Die Vierdeutigkeit der Phase des zurückgewonnenen Referenzträgers kann wiederum über eine Phasendifferenzcodierung oder durch Übertragung einer Phasenkennung umgangen werden. Mit der Phasendifferenzcodierung ist eine etwas größere Störanfälligkeit gegenüber Rauschen im Vergleich zur Absolutphasencodierung verbunden, weil zwei zusammengehörige Bits gestört werden. Auf gleiche Bitfehlerhäufigkeit bezogen ist bei Phasendifferenzcodierung ein um etwa 0,5 dB höherer Signal-zu-Rausch-Abstand am Demodulator notwendig. Bei der Übertragung des MPEG-2-Transportstroms im Satellitenkanal durch 4-Phasenumtastung bietet sich an, das zu Beginn eines jeden Transportstrompakets übertragene SYNC-Byte mit bekanntem Bitmuster als Kennsignal zur Phaseneinstellung bei der Synchrondemodulation zu verwenden, womit die Absolutphasencodierung angewendet werden kann. Die zur Einstellung der richtigen Referenzträgerphase notwendigen Maßnahmen werden in [2] genauer beschrieben.
10.3.3 Quadratur-Amplituden-Phasenumtastung (QAPSK)
Die benötigte Übertragungsbandbreite kann durch Verlängern der Schrittdauer der übertragenen Daten-Symbole weiter reduziert werden. Mit dem Zusammenfassen von vier aufeinanderfolgenden Bits erhält man 16-wertige Symbole, sechs aufeinanderfolgende Bits liefern 64-wertige Symbole. Das Umsetzen der höherwertigen Symbole nur auf entsprechende Phasenzustände ist aus Gründen des Störeinflusses ab 16 Zuständen nicht mehr sinnvoll. Die n-wertigen Symbole, mit n= 16,32,64,128, 256,..., werden deshalb in Kombinationen von verschiedenen Amplituden- und Phasenzuständen umgesetzt. Beim europäischen DVB-System sind von Bedeutung.

Die Erzeugung des Modulationsprodukts erfolgt wieder über eine Phasenumtastung und nun zusätzlich über die Amplitudenumtastung einer 0°-Trägerkomponente (In-Phase) und einer 90°-Trägerkomponente (Quadratur-Phase), weshalb insbesondere hier, aber auch schon bei der 4-PSK oder QPSK, von I-Q-Modulation gesprochen wird. Bei der 16-QAPSK werden sowohl auf der 0°-Trägerachse als auch auf der 90°-Trägerachse jeweils vier Trägerzustände erzeugt, bei der 64-QAPSK sind dies jeweils acht Trägerzustände. Im Fall der 16-QAPSK werden dazu aus einer 4-Bit-Kombination durch eine Serien-Parallel-Wandlung das 1. und 3. Bit bzw. das 2. und 4. Bit jeweils zu einer 2-Bit-Kombination zusammengefasst. Über einen Digital-Analog-Wandler gewinnt man 4-stufige Signale mit der Schrittdauer ![]() . Die Codesignale
. Die Codesignale ![]() werden den Multiplizierern über bandbegrenzende Tiefpass-Filter zugeführt. Aus der vektoriellen Addition der Ausgangssignale der Multiplizierer ergibt sich das resultierende Modulationsprodukt mit den 16 möglichen Vektorzuständen, deren Endpunkte im Zustandsdiagramm markiert sind (Bild 10.10).
werden den Multiplizierern über bandbegrenzende Tiefpass-Filter zugeführt. Aus der vektoriellen Addition der Ausgangssignale der Multiplizierer ergibt sich das resultierende Modulationsprodukt mit den 16 möglichen Vektorzuständen, deren Endpunkte im Zustandsdiagramm markiert sind (Bild 10.10).
Zu beachten ist, dass die Vektoren in einem Quadranten jeweils mit der Kombination des ersten und des zweiten Bits aus der zusammengefassten 4-Bit-Folge verbunden sind. Dies ist notwendig, weil zum Zweck der Trägerrückgewinnung auf die Quadranten Bezug genommen wird, indem eine Phasendifferenzcodierung in den ersten beiden Bits erfolgt. Die beiden letzten Bits werden so zugeordnet, dass bei einem Drehen des I-Q-Achsenkreuzes um Vielfache von 90°, was bei der Synchrondemodulation mit Phasendifferenzcodierung in den beiden ersten Bits geschehen kann, die Zuordnung der beiden letzten Bits auf die I- und Q-Achse erhalten bleibt [52], Siehe dazu Bild 10.11.
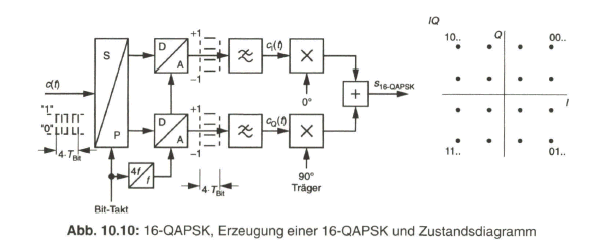
Zur Trägerrückgewinnung können nur die Vektoren herangezogen werden, die entsprechend einer 4-PSK als Winkelhalbierende in den Quadranten vorliegen. Um diese Vektoren zu selektieren, wird in der Zeitfunktion des 16-QAPSK-Signals eine Ausblendung der Trägerzustände vorgenommen, die mit den von n ■ 45° mit n= 1,3, 5 und 7 abweichenden Winkeln verbunden sind. Dies geschieht über die unterschiedlichen Amplituden, wie in Bild 10.12 gezeigt wird.
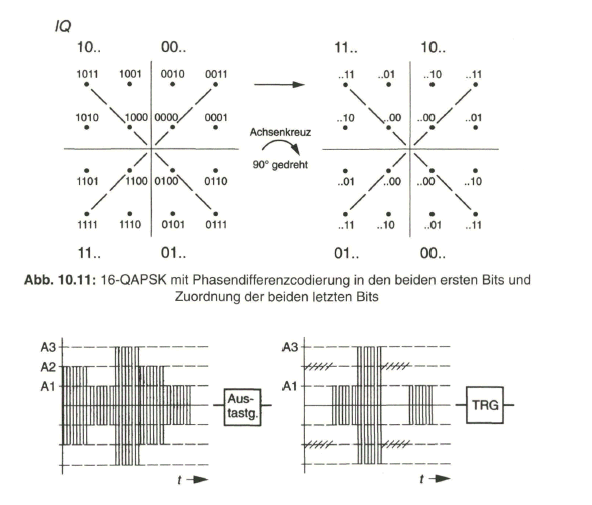
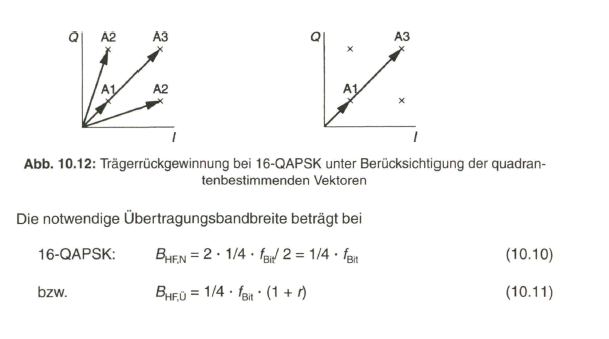
Zur Erzeugung einer 64-QAPSK werden jeweils 6 aufeinanderfolgende Bits zu einem Symbol zusammengefasst, das 64 Wertigkeiten aufweisen kann, mit Abbildung über 8 Zustände auf der 0°-(l-)Achse und über 8 Zustände auf der 90°-(Q-) Achse (Bild 10.13). Die Signalverarbeitung ist ähnlich wie bei der 16-QAPSK, nun mit Zuordnung von jeweils 3 Bits auf den I- und den Q-Zweig, was zu 8-stufigen Signalen führt. Die beiden ersten Bits aus der 6-Bit-Kombination bestimmen wieder den Quadranten. Sie werden differenzcodiert übertragen. Die Zuordnung der letzten vier Bits erfolgt ähnlich wie bereits bei der 16-QAPSK erläutert, so dass für jede der möglichen vier Phasenlagen der Referenzträgerschwingung die Trägerzustände auf der I- und Q-Achse richtig demoduliert werden.
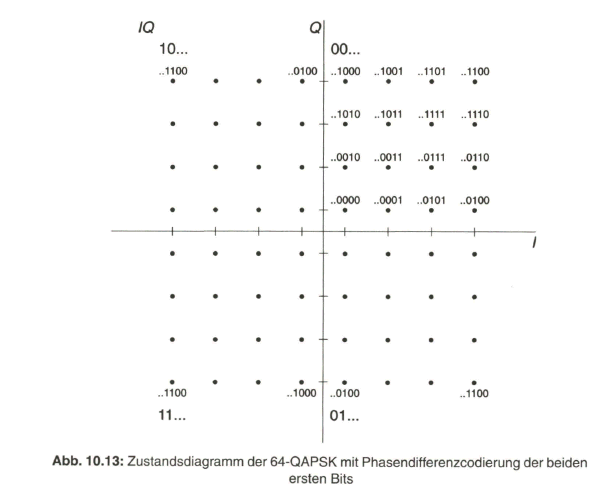
Zur Trägerrückgewinnung wird das 64-QAPSK-Signal zweimal quadriert. Damit tritt das Spektrum um die vierfache Trägerfrequenz auf, mit einer dominierenden Komponente bei der Frequenz ![]() . Diese wird über einen Bandpass ausgefiltert und zur Synchronisation in einen frequenz- und phasenselektiven Regelkreis (PLL) eingeführt. Dessen Oszillator (VCO) liefert die frequenz- und phasenrichtige Referenzträgerschwingung mit der Frequenz
. Diese wird über einen Bandpass ausgefiltert und zur Synchronisation in einen frequenz- und phasenselektiven Regelkreis (PLL) eingeführt. Dessen Oszillator (VCO) liefert die frequenz- und phasenrichtige Referenzträgerschwingung mit der Frequenz ![]() für die Synchrondemodulation [2].
für die Synchrondemodulation [2].
Die notwendige Übertragungsbandbreite reduziert sich nun nochmals gegenüber der 16-QAPSK. Sie beträgt, bezogen auf die Bitfolgefrequenz ![]() , bei
, bei
Zu berücksichtigen ist aber, dass die Störanfälligkeit mit zunehmender Wertigkeit des Modulationsprodukts zunimmt, was noch ausführlicher erläutert wird.
10.3.4 Vergleich der Trägertastverfahren nach Bandbreitebedarf
Durch das Zusammenfassen von jeweils zwei, vier oder sechs Bits zu mehrstufigen Symbolen wird die Schrittgeschwindigkeit des Datensignals entsprechend reduziert. Damit verringert sich die notwendige Übertragungsbandbreite, die einmal im Basisband durch die NYQUIST-Bandbreite ![]() und zum anderen im Trägerfrequenzbereich durch die mindest notwendige HF-Bandbreite
und zum anderen im Trägerfrequenzbereich durch die mindest notwendige HF-Bandbreite ![]() charakterisiert wird. Mit zunehmender Wertigkeit der Symbole rücken die Nullstellen im Spektrum näher zusammen. Für eine vorgegebene zu übertragende Bitrate rBit wird das zwischen den Nullstellen belegte Spektrum schrittweise geringer. Eine Übersichtsdarstellung in Bild 10.14 gibt dies im Vergleich der Spektren von 2- PSK, 4-PSK, 16-QAPSK und 64-QAPSK wieder.
charakterisiert wird. Mit zunehmender Wertigkeit der Symbole rücken die Nullstellen im Spektrum näher zusammen. Für eine vorgegebene zu übertragende Bitrate rBit wird das zwischen den Nullstellen belegte Spektrum schrittweise geringer. Eine Übersichtsdarstellung in Bild 10.14 gibt dies im Vergleich der Spektren von 2- PSK, 4-PSK, 16-QAPSK und 64-QAPSK wieder.
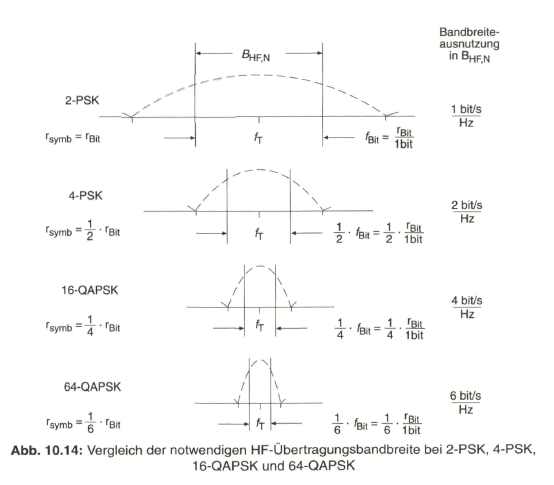
An Stelle der zu übertragenden Bitrate ![]() wird bei mehrstufiger Modulation vielfach die Symbolrate
wird bei mehrstufiger Modulation vielfach die Symbolrate ![]() angegeben, die sich gemäß den Angaben in Bild 10.14 berechnet. Ein weiteres Kriterium ist die Bandbreiteausnutzung in der HF-Bandbreite
angegeben, die sich gemäß den Angaben in Bild 10.14 berechnet. Ein weiteres Kriterium ist die Bandbreiteausnutzung in der HF-Bandbreite ![]() , die auch in Bild 10.14 angegeben ist. Man sieht deutlich, dass dieser Wert zahlenmäßig durch die Anzahl der Bits, die zu einem Symbol zusammengefasst werden, zum Ausdruck kommt. Die Dimension für diesen Wert beträgt bit/s pro Hz Bandbreite.
, die auch in Bild 10.14 angegeben ist. Man sieht deutlich, dass dieser Wert zahlenmäßig durch die Anzahl der Bits, die zu einem Symbol zusammengefasst werden, zum Ausdruck kommt. Die Dimension für diesen Wert beträgt bit/s pro Hz Bandbreite.
10.3.5 Einfluss von Rauschstörungen
Die Auswahl des Modulationsverfahrens wird bestimmt durch die in einem Verteilkanal mit vorgegebener Bandbreite zu übertragende Bitrate und durch den am Demodulatoreingang mindest notwendigen Träger-zu-Rausch-Abstand. Die für Fernsehsignalverteilung zugewiesenen Satellitenkanäle im Mikrowellenbereich weisen Kanalbandbreiten zwischen 25 und 50 MHz auf. Bei der DVB- Satellitenübertragung wird vornehmlich von einer Kanalbandbreite von ![]() = 33 MHz ausgegangen. Es kommen aber auch Transponder mit einer Kanalbandbreite von
= 33 MHz ausgegangen. Es kommen aber auch Transponder mit einer Kanalbandbreite von ![]() = 26 MHz für die Übertragung von digitalen Fernsehsignalen zum Einsatz. In Kabelverteilsystemen und beim terrestrischen Fernsehen erfolgt die Übertragung des DVB-Signals in den UHF-Kanälen mit einer Bandbreite von
= 26 MHz für die Übertragung von digitalen Fernsehsignalen zum Einsatz. In Kabelverteilsystemen und beim terrestrischen Fernsehen erfolgt die Übertragung des DVB-Signals in den UHF-Kanälen mit einer Bandbreite von ![]() = 8 MHz. Beim terrestrischen Fernsehen werden auch die von analoger Übertragung frei geschalteten 7-MHz-Kanäle verwendet.
= 8 MHz. Beim terrestrischen Fernsehen werden auch die von analoger Übertragung frei geschalteten 7-MHz-Kanäle verwendet.
Auf Grund der sendeseitigen Vorgaben, wie Transponderleistung und Antennengewinn beim Satelliten sowie Übertragungsdämpfung bis zur Empfangsantenne und realistischen Empfangsanlagen mit z. B. 60cm Parabolantenne, kann man im Satellitenübertragungskanal am Demodulatoreingang von einem Träger-zu-Rausch-Abstand mit etwa C/N= 10 dB ausgehen. Bei einer Bitfehlerhäufigkeit von BER ![]() (siehe Abschnitt 9.2.4) erfordert diese Situation, dass höchstens die 4-PSK als Modulationsverfahren in Frage kommen kann. Siehe dazu das Diagramm in Bild 10.15 mit den Werten von BER abhängig vom Träger-zu-Rausch-Abstand C/N für die beim digitalen Fernsehen relevanten Trägertastverfahren.
(siehe Abschnitt 9.2.4) erfordert diese Situation, dass höchstens die 4-PSK als Modulationsverfahren in Frage kommen kann. Siehe dazu das Diagramm in Bild 10.15 mit den Werten von BER abhängig vom Träger-zu-Rausch-Abstand C/N für die beim digitalen Fernsehen relevanten Trägertastverfahren.
Beim Kabelverteilsystem kann auf Grund der Planungsvorgaben von einem Träger-zu-Rausch-Abstand am Demodulator von etwa C/N - 30 dB ausgegangen werden. Mit der in diesem Fall geforderten Bitfehlerhäufigkeit von BER ![]() (siehe Abschnitt 9.2.4) kann 64-QAPSK zur Anwendung kommen.
(siehe Abschnitt 9.2.4) kann 64-QAPSK zur Anwendung kommen.
Beim Digitalen Terrestrischen Fernsehen muss neben dem Einfluss von Rauschstörungen noch sehr mit Interferenzstörungen durch Echosignale und Mehrwegeempfang gerechnet werden. Der Einfluss von Rauschstörungen ist damit nicht alleine für die Bitfehlerhäufigkeit verantwortlich.
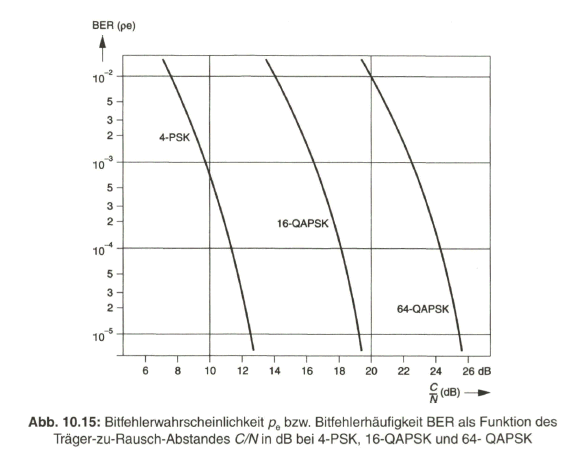
Das Diagramm in Bild 10.15 gibt eigentlich die zu erwartende theoretische Bitfehlerwahrscheinlichkeit ![]() als Funktion des Träger-zu-Rausch-Abstandes C/N in dB wieder. Die praktisch vorliegende Bitfehlerhäufigkeit BFH oder das „Verhältnis“, Bit Error Ratio BER, von falsch empfangenen zu den insgesamt übertragenen Bits, deckt sich meistens sehr gut mit dem Wert
als Funktion des Träger-zu-Rausch-Abstandes C/N in dB wieder. Die praktisch vorliegende Bitfehlerhäufigkeit BFH oder das „Verhältnis“, Bit Error Ratio BER, von falsch empfangenen zu den insgesamt übertragenen Bits, deckt sich meistens sehr gut mit dem Wert ![]() .
.
Bei dem mit C/N angegebenen Träger-zu-Rausch-Abstand, handelt es sich um eine logarithmierte Größe, die im Gegensatz zu dem linearen Verhältnis der Träger(C)- zu Rausch (N)-Leistung besonders gekennzeichnet werden sollte. Es gilt:
![]()
Im praktischen Gebrauch wird jedoch meist mit dem Begriff C/N der logarithmierte Wert zum Ausdruck gebracht. Vielfach erscheint auch der Begriff ![]() , womit das meist im logarithmischen Maß angegebene Verhältnis von Energie je übertragenes Bit zur Rauschleistungsdichte angegeben wird. Genauso wie der Wert C/N ist auch der Wert
, womit das meist im logarithmischen Maß angegebene Verhältnis von Energie je übertragenes Bit zur Rauschleistungsdichte angegeben wird. Genauso wie der Wert C/N ist auch der Wert ![]() auf den Eingang des Demodulators bezogen.
auf den Eingang des Demodulators bezogen.
Die Energie ![]() je Bit berechnet sich aus der Trägerleistung C multipliziert mit der Bitdauer
je Bit berechnet sich aus der Trägerleistung C multipliziert mit der Bitdauer ![]() .
.

Die Rauschleistungsdichte ![]() gibt die Rauschleistung in einem Frequenzintervall von 1 Hz an. Sie berechnet sich aus der gesamten Rauschleistung N innerhalb des Übertragungskanals mit der Rauschbandbreite
gibt die Rauschleistung in einem Frequenzintervall von 1 Hz an. Sie berechnet sich aus der gesamten Rauschleistung N innerhalb des Übertragungskanals mit der Rauschbandbreite ![]() zu.
zu.

Die Rauschbandbreite oder Leistungsbandbreite erhält man aus der quadrierten, normierten Spannungsübertragungsfunktion ![]() mit dem Maximalwert eins und Umwandlung der Fläche unterhalb
mit dem Maximalwert eins und Umwandlung der Fläche unterhalb ![]() in ein flächengleiches Rechteck mit der Höhe eins und der Breite gleich der Rauschbandbreite Br.
in ein flächengleiches Rechteck mit der Höhe eins und der Breite gleich der Rauschbandbreite Br.
Beim ![]() -Roll-Off-Tiefpass oder entsprechend auch auf den symmetrischen Bandpass übertragen berechnet sich die Rauschbandbreite zu
-Roll-Off-Tiefpass oder entsprechend auch auf den symmetrischen Bandpass übertragen berechnet sich die Rauschbandbreite zu
 Der Zusammenhang zwischen den logarithmierten Größen
Der Zusammenhang zwischen den logarithmierten Größen
![]()
ergibt sich mit dem Wert von m Bits pro Symbol zu

10.3.6 Hierarchische Modulation
Bei der Überlagerung von Rauschen auf das Modulationsprodukt zeigt sich im Zustandsdiagramm eine „Rauschwolke“ um den eigentlichen Vektorendpunkt. Es ist zu berücksichtigen, dass „Rauschen“ ein statistischer Schwankungsvorgang ist und theoretisch alle Momentanwerte zwischen Null und Unendlich auftreten können. Abgesehen von der praktischen Begrenzung des Spannungsbereiches gilt die GAUSS’sche Wahrscheinlichkeitsverteilung für Momentanwerte des Rauschens, wonach die Wahrscheinlichkeit für höhere Momentanwerte exponentiell absinkt. Maßgeblich für die Rauschstörung ist die Rauschleistung ![]() innerhalb des Übertragungskanals und der daraus abgeleitete Effektivwert der Rauschspannung
innerhalb des Übertragungskanals und der daraus abgeleitete Effektivwert der Rauschspannung ![]() . Das überlagerte Rauschen wird im Zustandsdiagramm im Wesentlichen bis zum Effektivwert sichtbar werden. Bild 10.16 zeigt dazu das Zustandsdiagramm bei 16-QAPSK und 64-QAPSK mit überlagertem Rauschen bei einem Signal-zu-Rausch-Abstand von „C/N“ = 20 dB bzw. 25 dB. Eingetragen sind darin auch die Entscheidungsgrenzen zu den einzelnen Vektorendpunkten [61].
. Das überlagerte Rauschen wird im Zustandsdiagramm im Wesentlichen bis zum Effektivwert sichtbar werden. Bild 10.16 zeigt dazu das Zustandsdiagramm bei 16-QAPSK und 64-QAPSK mit überlagertem Rauschen bei einem Signal-zu-Rausch-Abstand von „C/N“ = 20 dB bzw. 25 dB. Eingetragen sind darin auch die Entscheidungsgrenzen zu den einzelnen Vektorendpunkten [61].
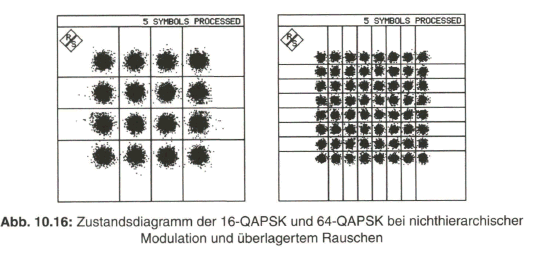
In dem angenommen weißen Rauschen mit der GAUSS'schen Wahrscheinlichkeitsverteilung kommt der Effektivwert UR mit einer Wahrscheinlichkeit von ![]() = 0,24 vor, während für den zweifachen Effektivwert die Wahrscheinlichkeit bei
= 0,24 vor, während für den zweifachen Effektivwert die Wahrscheinlichkeit bei ![]() = 0,06 und die Wahrscheinlichkeit für das Überschreiten des fünffachen Effektivwerts nur noch bei
= 0,06 und die Wahrscheinlichkeit für das Überschreiten des fünffachen Effektivwerts nur noch bei ![]() liegt.
liegt.
Der bei DVB übertragene Transportstrom beinhaltet im Allgemeinen mehrere Programme mit den gleichen Grundparametern (Zeilenzahl, Bildpunktauflösung u. a.). Es wäre aber auch möglich, ein HDTV-Programm zu übertragen mit dem Basis-SDTV-Anteil und zusätzlich einem ergänzenden HDTV-Anteil. Des Weiteren gibt schon MPEG-2 mit den „Skalierbaren Profilen“ die Möglichkeit, einen Datenstrom in Anteile mit unterschiedlicher Priorität aufzuteilen [33, 43].
Die Umsetzung in das Modulationsprodukt erfolgt dann über eine sog. hierarchische Modulation. Dabei werden die Vektorendpunkte auf einen kleineren Bereich im Quadranten zusammengefasst mit dem Ziel, dass bei einer überlagerten Rauschstörung aus den empfangenen Symbolen zumindest der Quadrant (in den ersten beiden Bits codiert) einwandfrei erkannt wird. Damit ist in einer 16-QAPSK ein resistenter 4-PSK-Anteil enthalten. Bild 10.17 gibt dazu das Zustandsdiagramm bei hierarchischer Modulation mit 16-QAPSK und 64-QAPSK wieder, bei einem Träger-zu-Rausch-Abstand von „C/N“ = 26 dB bzw. 28 dB. Eine Kenngröße a charakterisiert den Grad der „unsymmetrischen“ Verteilung der Vektorendpunkte in einem Quadranten. In den Beispielen nach Bild 10.17 ist a = 4 [2].
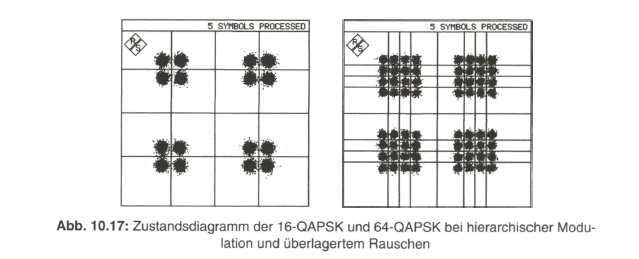
Mit der hierarchischen Modulation, die eigentlich nur in einem Übertragungskanal mit zeitlich schwankenden Parametern wie beim terrestrischen Fernsehen angebracht ist, könnte die „graceful degradation“auch so ausgenutzt werden, dass ein TV-Programm aus der Grundversorgung in dem „high priority“-Anteil des Datenstroms übertragen wird und ein weiteres Programm in dem ,,low priority“-Anteil. Oder es wird unter Ausnutzung des skalierbaren MPEG-2-Profils ein TV-Programm mit nur bescheidener Bild- und Tonqualität im robusten 4-PSK-Anteil übertragen und in dem verbleibendem Anteil des 16-QAPSK-Datenstroms ein qualitätserhöhender Beitrag zum Video- und Audiosignal.
Die hierarchische Modulation beim digitalen terrestrischen Fernsehen hat bislang nur wenig Beachtung gefunden. Untersuchungen haben jedoch ergeben, dass mit der Übertragung von zwei unabhängigen Multiplex-Transportströmen auf einer Frequenz mit unterschiedlichen Qualitätsansprüchen, d. h. als „high priority”- und „low priority”- Anteil des Gesamtdatenstroms, ein höheres Gesamtversorgungspotential erreicht wird.
Dieses wird definiert entweder über die erreichbare Bevölkerung durch ein
• Datenversorgungsteilnehmerpotential als Produkt der Anzahl der versorgten Bevölkerung und der übertragenen Datenrate
• beziehungsweise durch ein Datenversorgungsflächenpotential als Produkt der versorgten Fläche und der übertragenen Datenrate.
Ausführliche Ergebnisse dazu werden am Beispiel des DVB-T-Senders Alexanderplatz in Berlin dargestellt [79].
10.4 Orthogonal Frequency Division Multiplex (OFDM)
Die bisher beschriebenen digitalen Trägermodulationsverfahren kommen in einem Übertragungskanal zur Anwendung, der ein nahezu optimales Empfangssignal liefert, das von einer Richtantenne aufgenommen oder am Kabelanschluss abgenommen wird, und das nur wenig oder in tragbarem Maß durch Rauschen gestört ist. Man spricht in diesem Fall von einem „GAUSS'schen Kanal“ oder von dem AWGN-Kanal (Additive White GAUSSian Noise). Es trifft für den Satellitenübertragungskanal und im Wesentlichen auch für den Kabelkanal zu. Beim terrestrischen Funkkanal können durch Richtempfangsantennen zwar Echosignale stark unterdrückt und der Träger-zu-Rausch-Abstand beachtlich verbessert werden, aber dies führt u. U. zu sehr umfangreichen Antennengebilden. Mit der Einführung des digitalen terrestrischen Fernsehens sollte deshalb an Stelle der Richtempfangsantenne eine kurze Stabantenne treten, die zudem portablen Empfang auch innerhalb von Gebäuden ermöglicht. Damit aber entfallen die Richtwirkung und das Ausblenden von Echo- oder Mehrwegesignalen. Man hat es nun mit einem so genannten „RICE-Kanal“ zu tun.
Eine weitere Forderung war, digitales terrestrisches Fernsehen in Gleichwellennetzen mit einer Senderkette auszustrahlen, bei der jeder Sender synchron auf der gleichen Sendefrequenz einen zu den anderen Sendern absolut identischen Datenstrom ausstrahlt. Damit unterstützen sich benachbarte Sender in einem gewissen Versorgungsgebiet. Es gibt nun keinen eindeutigen direkten Signalpfad mehr, das heißt es liefern mehrere Empfangssignale einen Beitrag zum Gesamtempfangssignal. Durch Interferenzen können starke Signaleinbrüche bei bestimmten Frequenzen im Empfangsband auftreten, die zudem zeitlichen Schwankungen unterworfen sind.
Bild 10.18 gibt eine mögliche Situation beim Mehrwegeempfang wieder, die insbesondere bei der Benutzung einer einfachen Stabantenne ohne Richtwirkung zu starken Interferenzen im Empfangssignal führen kann. Eine Modellierung dieser Situation repräsentiert der „RALEIGH-Kanal [2].
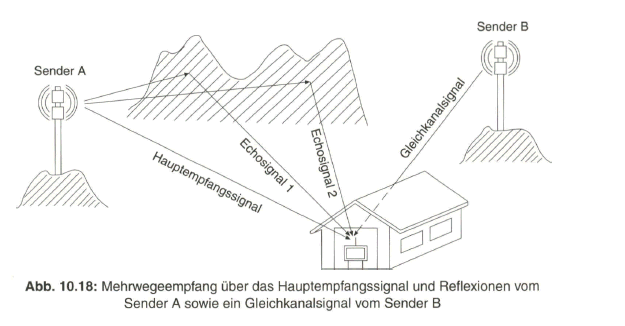
Die Übertragungsfunktion des Mehrwegekanals weist starke Dämpfungs- und Phasenverzerrungen auf, die noch dazu temporären Schwankungen unterworfen sind. Mittels geeigneter, jedoch sehr aufwendiger Entzerrerfilter könnten gegebenenfalls die entstandenen Verzerrungen im Frequenzbereich wieder ausgeglichen werden. Das Spektrum bei Einträgermodulation würde in einem breiten Frequenzbereich durch die stark schwankende Übertragungsfunktion sehr störend beeinflusst werden. An einem Beispiel ist dies in Bild 10.19 an Hand des Dämpfungsfrequenzgangs des Übertragungskanals dargestellt.
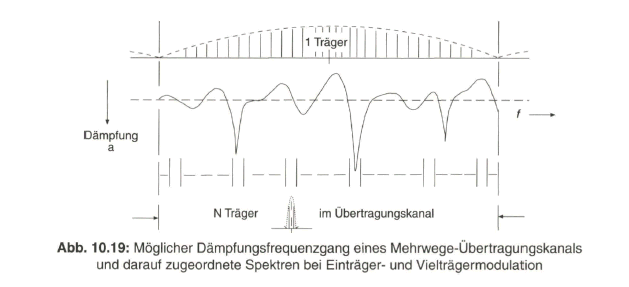
Bei Aufteilung des Datenstroms auf eine Vielzahl von N Trägern mit jeweils nur anteiliger Datenrate verringert sich der Einfluss der schwankenden Übertragungsfunktion innerhalb des Spektrums eines der N Träger. Dies trifft umso mehr zu, je höher die Anzahl N der einzelnen Träger innerhalb des gesamten Übertragungskanals ist. Eine schematische Erzeugung des resultierenden Vielträgersignals, ausgehend vom zu übertragenden Datenstrom mit der Bitrate ![]() beziehungsweise der Symbolrate
beziehungsweise der Symbolrate ![]() und die nachfolgende Zuordnung auf N Träger zeigt Bild 10.20. Die tatsächliche praktische Realisierung der Vielträgermodulation erfolgt jedoch über das Verfahren der Diskreten Inversen FOURIER-Transformation im Software-Bereich, wie im Folgenden noch ausführlich erläutert wird.
und die nachfolgende Zuordnung auf N Träger zeigt Bild 10.20. Die tatsächliche praktische Realisierung der Vielträgermodulation erfolgt jedoch über das Verfahren der Diskreten Inversen FOURIER-Transformation im Software-Bereich, wie im Folgenden noch ausführlich erläutert wird.
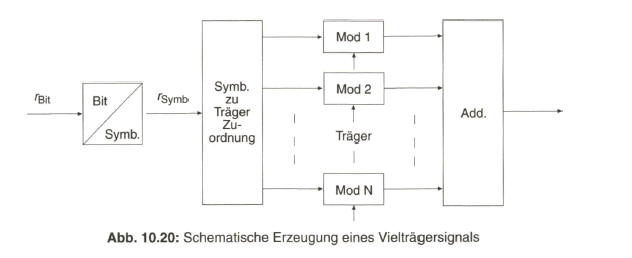
10.4.1 Prinzip der OFDM
Eine Anwendung fand die Vielträgermodulation bei der digitalen Tonsignalübertragung mit besonderer Berücksichtigung des mobilen Rundfunkempfangs. Bei dem DAB-System (Digital Audio Broadcasting) ist das OFDM-Verfahren (Orthogonal Frequency Division Multiplex) erstmals zum praktischen Einsatz gekommen. Der zu übertragende Datenstrom mit der Bitrate ![]() bzw. bei mehrstufiger Modulation mit der Symbolrate
bzw. bei mehrstufiger Modulation mit der Symbolrate ![]() wird auf eine Vielzahl von N einzelnen Trägern aufgeteilt, womit auf jedem Einzelträger ein Datenstrom mit
wird auf eine Vielzahl von N einzelnen Trägern aufgeteilt, womit auf jedem Einzelträger ein Datenstrom mit ![]() / N übertragen wird. Selektiv auftretende Einbrüche in der Übertragungsfunktion des Kanals betreffen damit nur einzelne Träger, was durch geeignete Kanalcodierung ausgeglichen werden kann. Man spricht dann von Coded Orthogonal Frequency Division Multiplex (COFDM). Der Frequenzabstand
/ N übertragen wird. Selektiv auftretende Einbrüche in der Übertragungsfunktion des Kanals betreffen damit nur einzelne Träger, was durch geeignete Kanalcodierung ausgeglichen werden kann. Man spricht dann von Coded Orthogonal Frequency Division Multiplex (COFDM). Der Frequenzabstand ![]() zwischen den Einzelträgern ergibt sich nach der Orthogonalitätsbeziehung (Gl. 10.18) aus dem reziproken Wert der Symboldauer des Teildatenstromes:
zwischen den Einzelträgern ergibt sich nach der Orthogonalitätsbeziehung (Gl. 10.18) aus dem reziproken Wert der Symboldauer des Teildatenstromes:

Die Symboldauer ist hier maßgeblich, weil jeder Einzelträger in sich nach einem Verfahren der 4-PSK, 16-QAPSK o. a. moduliert wird, selbstverständlich alle Einzelträger zunächst mit dem gleichen Verfahren. Die Symboldauer beträgt bei
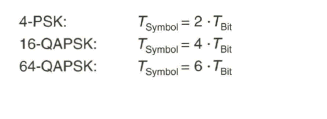
Eine Gegenüberstellung des Spektrums bei der Einträgermodulation und bei der Mehrträgermodulation zeigt Bild 10.21, wobei das Spektrum des oder der modulierten Träger ohne Basisbandbegrenzung und einschließlich der Phasenbeziehung in dem Frequenzbereich über die erste Nullstelle hinaus dargestellt ist.
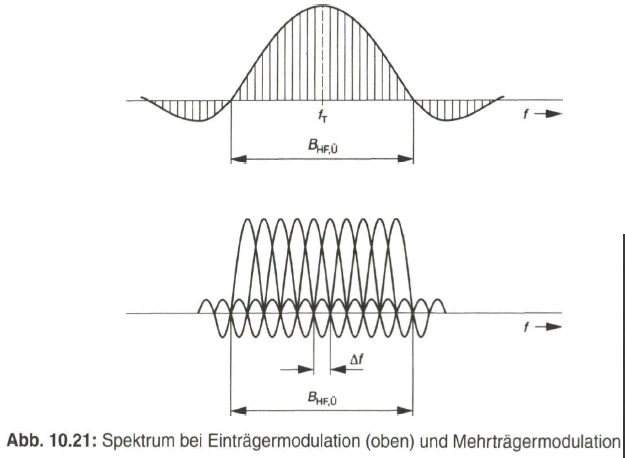
Unter Zugrundelegung der Orthogonalitätsbeziehung überlappen sich die Teilspektren so, dass Maxima und Nullstellen der benachbarten Spektren aufeinander fallen. Damit kommt keine gegenseitige Störung zustande. Das belegte Frequenzband ![]() zwischen den ersten Nullstellen im Spektrum bei der Einträgermodulation und zwischen den ersten äußersten Nullstellen bei der Mehrträgermodulation ist, mit der Annahme von N» 1, annähernd gleich. Es berechnet sich bei der Einträgermodulation bezogen auf den Gesamtdatenstrom
zwischen den ersten Nullstellen im Spektrum bei der Einträgermodulation und zwischen den ersten äußersten Nullstellen bei der Mehrträgermodulation ist, mit der Annahme von N» 1, annähernd gleich. Es berechnet sich bei der Einträgermodulation bezogen auf den Gesamtdatenstrom ![]() zu.
zu.

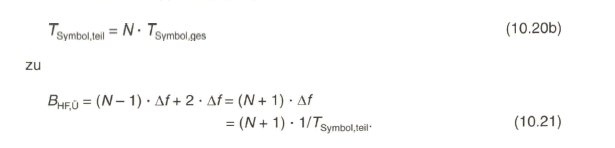
(siehe dazu Bild 10.21, unten)
Die Frequenz f der Einzelträger mit der laufenden Ordnungszahl k erhält man, bezogen auf die unterste Frequenz f0, wie folgt:

Eine zweidimensionale Darstellung gibt Bild 10.22 ausschnittsweise in der Frequenz-Zeit-Ebene wieder. Die angegebenen Vektoren beziehen sich auf eine 4-PSK der einzelnen Träger, wobei der Vektorzustand über jeweils die Symboldauer ![]() beibehalten wird. Die Schrittgeschwindigkeit oder die Symbolrate der Teildatenströme beträgt nur ein N-tel der Symbolrate des Gesamtdatenstroms, womit auch von jedem Einzelträger nur ein N-tel der Gesamtbandbreite im Spektrum belegt wird.
beibehalten wird. Die Schrittgeschwindigkeit oder die Symbolrate der Teildatenströme beträgt nur ein N-tel der Symbolrate des Gesamtdatenstroms, womit auch von jedem Einzelträger nur ein N-tel der Gesamtbandbreite im Spektrum belegt wird.
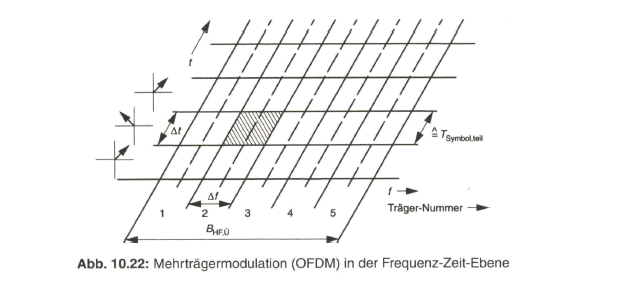
10.4.2 Einfügung eines Schutzintervalls
Die Praxis unter realen Empfangsbedingungen ergibt eine Überlagerung der auf Umwegen am Empfangsort eintreffenden Signale mit dem direkt empfangenen Signal mit der Folge, dass die Orthogonalitätsbeziehung gestört und dadurch eine Intersymbolinterferenz mit der Folge von Symbolfehlern verursacht wird. Dieses Problem kann umgangen werden, indem bei der Signalübertragung ein so genanntes Schutzintervall (guard intervall) der Dauer Tg vor der eigentlichen Symboldauer ![]() eingefügt wird, innerhalb dessen die verzögerten Signalanteile beim Empfänger eintreffen. Das Einfügen des Schutzintervalls ist gleichbedeutend mit der Verlängerung der Symboldauer. Die Dauer des übertragenen Symbols erhöht sich damit auf
eingefügt wird, innerhalb dessen die verzögerten Signalanteile beim Empfänger eintreffen. Das Einfügen des Schutzintervalls ist gleichbedeutend mit der Verlängerung der Symboldauer. Die Dauer des übertragenen Symbols erhöht sich damit auf

Auch das Spektrum wird beeinflusst, weil Maxima und Nullstellen nicht mehr genau aufeinander fallen. Dies ist aber mit der weiteren Signalverarbeitung bedeutungslos. Die Auswertung des empfangenen Symbols geschieht erst nach Ablauf der Schutzintervalldauer im Bereich der eigentlichen Symboldauer und dort gilt wieder die Orthogonalitätsbeziehung. Die neben einem Direktempfangssignal einfallenden Echosignale und Nachbarstandortsignale aus einem Gleichwellennetz bilden zusammen ein resultierendes Empfangssignal, das nun durch die Mehrfachsignalanteile sogar noch verstärkt wird. Siehe dazu Bild 10.23 [2]. Die effektiv übertragbare Datenrate wird allerdings durch das zusätzlich eingefügte Schutzintervall reduziert. Man erhält einen Reduktionsfaktor ![]() mit
mit
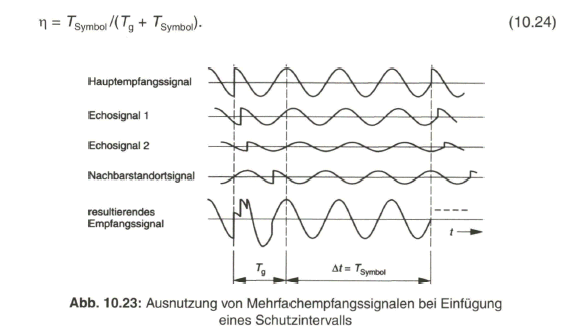
Die Dauer des Schutzintervalls wird üblicherweise auf die Symboldauer bezogen. Werte von 1/4, 1/8, 1/16 und 1/32 der Symboldauer sind nach dem DVB-T-Standard vorgesehen.
Bild 10.24 erläutert am Beispiel mit ![]() die Reduzierung der effektiv übertragbaren Datenrate auf
die Reduzierung der effektiv übertragbaren Datenrate auf ![]() , mit der Beziehung
, mit der Beziehung
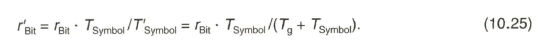
Die Dauer des Schutzintervalls wird durch die mögliche Umweglaufzeit und durch den Abstand zu Nachbarsendern bei Gleichwellennetzen bestimmt. Bei einer auf dem Funkweg zurückgelegten Strecke von 300 m pro Mikrosekunde und einem Abstand des Nachbarsenders von 60 km zu dem nahe des direkt empfangenen Senders angenommenen Empfangsort trifft das Nachbarkanalsignal um 180 ![]() verzögert ein. Bei einer Symboldauer
verzögert ein. Bei einer Symboldauer ![]() von 1 ms (siehe dazu eine Erläuterung und genaue Zahlenangaben im Abschnitt 11.3) erfordert dies ein Schutzintervall von > 180
von 1 ms (siehe dazu eine Erläuterung und genaue Zahlenangaben im Abschnitt 11.3) erfordert dies ein Schutzintervall von > 180 ![]() , d. h. es wird ein Wert Tg
, d. h. es wird ein Wert Tg ![]() .
.
Längere Schutzintervalle sind für Gleichwellennetze mit Sendern höherer Leistung und Abständen über 30 km vorgesehen. Je kleiner der Abstand zwischen den Senderstandorten ist, umso kürzer kann das Schutzintervall ![]() sein. Dies betrifft regionale oder lokale Netzwerke mit Sendern kleiner Leistung. Der Betrieb eines Gleichwellennetzes (Single Frequency Network, SFN) erfordert die zeitsynchrone Abstrahlung der Datensymbole von den verschiedenen Senderstandorten. Die Zuführung des Modulationssignals zu den Gleichwellensendern erfolgt meistens über einen geostationären Satelliten auf der Äquatorposition. An den einzelnen Senderstandorten muss dennoch ein „Feinabgleich“ der Signallaufzeit vorgenommen werden, der die geringfügig unterschiedliche Entfernung der Senderstandorte zum Satelliten berücksichtigt.
sein. Dies betrifft regionale oder lokale Netzwerke mit Sendern kleiner Leistung. Der Betrieb eines Gleichwellennetzes (Single Frequency Network, SFN) erfordert die zeitsynchrone Abstrahlung der Datensymbole von den verschiedenen Senderstandorten. Die Zuführung des Modulationssignals zu den Gleichwellensendern erfolgt meistens über einen geostationären Satelliten auf der Äquatorposition. An den einzelnen Senderstandorten muss dennoch ein „Feinabgleich“ der Signallaufzeit vorgenommen werden, der die geringfügig unterschiedliche Entfernung der Senderstandorte zum Satelliten berücksichtigt.
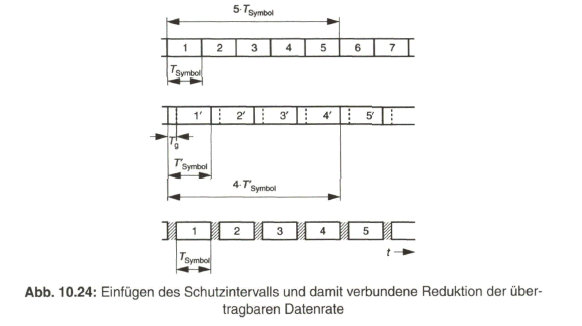
10.4.3 Technische Realisierung der OFDM
Zur technischen Realisierung der OFDM sind folgende Maßnahmen notwendig:
• Die zyklische Symbolzuordnung der ankommenden Daten auf die N Einzelträger, ein numerischer Vorgang, der mit „Nummern“ für die Trägerfrequenzen dem Frequenzbereich zuzuordnen ist.
• Die Transformation aus dem Frequenzbereich in den Zeitbereich zur Gewinnung des OFDM-Signals.
Eine Transformation vom Frequenzbereich in den Zeitbereich wird bei digitaler Signalverarbeitung über die Discrete Inverse FOURIER-Transformation (DIFT) vorgenommen, das heißt mittels des Algorithmus der Discrete Inverse Fast Fourier Transformation (DIFFT). Eine kurze, bildliche Erläuterung der FOURIER-Transformation (FT) sei zunächst vorangestellt. Es wird von einer periodischen Zeitfunktion f(t) ausgegangen, die z. B. als Sinusschwingung mit den Parametern Amplitude u, Periodendauer T und Nullphasenwinkel ![]() angenommen wird (Bild 10.25, links). Nach den Gesetzen der Wechselstromlehre wird im Zeitbereich diese phasenverschobene Sinusschwingung durch die Addition einer Sinus- und einer Cosinuskomponente gebildet (gestrichelt gezeichnet). Im Frequenzbereich (Bild 10.25, rechts) wird die phasenverschobene Sinusschwingung durch eine Cosinuskomponente (Realteil Re) und durch eine Sinuskomponente (Imaginärteil Im) repräsentiert (gestrichelt gezeichnet), bzw. durch den Vektor u(f) bei der Frequenz
angenommen wird (Bild 10.25, links). Nach den Gesetzen der Wechselstromlehre wird im Zeitbereich diese phasenverschobene Sinusschwingung durch die Addition einer Sinus- und einer Cosinuskomponente gebildet (gestrichelt gezeichnet). Im Frequenzbereich (Bild 10.25, rechts) wird die phasenverschobene Sinusschwingung durch eine Cosinuskomponente (Realteil Re) und durch eine Sinuskomponente (Imaginärteil Im) repräsentiert (gestrichelt gezeichnet), bzw. durch den Vektor u(f) bei der Frequenz ![]() mit der Amplitude u und dem auf die Realteil-Achse bezogenen Phasenwinkel
mit der Amplitude u und dem auf die Realteil-Achse bezogenen Phasenwinkel ![]() .
.
Bei der inversen FOURIER-Transformation (IFT) erfolgt die Umsetzung einer oder mehrerer Spektralkomponenten der Funktion F(f) aus dem Frequenzbereich in den Zeitbereich, wie an einem Beispiel in Bild 10.26 gezeigt wird.
Die FOURIER-Transformation der Funktion f(t) vom Zeitbereich in den Frequenzbereich mit der Funktion F(f) erfolgt nach der mathematischen Beziehung

Für die inverse FOURIER-Transformation der Funktion F(f) aus dem Frequenzbereich in den Zeitbereich mit f(f) gilt

Bei der digitalen Signalverarbeitung bezieht man sich auf diskrete Abtastwerte, die als binäre Codeworte vorliegen. Die Grenzen im Zeitbereich werden jetzt mit endlichen Werten definiert. Über einen bestimmten Bereich mit N Abtastwerten, der wegen der „schnellen“ FOURIER-Transformation (FFT) in Zweierpotenzen festgelegt wird mit z. B. N= ... 1024, 2048 (= 2k), ... , 8192 (= 8k) erfolgt die Berechnung der Funktion nach Gleichung (10.26) bzw. (10.27), wobei die Integration jetzt durch eine Aufsummierung von Teilflächen ersetzt wird.
Bei der OFDM ist eine Transformation vom Frequenzbereich in den Zeitbereich vorzunehmen. Es kommt die Discrete Inverse Fast Fourier Transformation (DIFFT) zur Anwendung. Die Zuordnung der Datensymbole auf die einzelnen Träger mit der Nummer /c = 0 bis k = N-1 und Festlegung ihres Vektorzustandes über die Werte von Realteil und Imaginärteil, je nach dem gewählten Modulationsverfahren, bezeichnet man als „Mapping“. Wegen der mit digitaler Signalverarbeitung am Ende des Prozesses notwendigen Digital-Analog-Wandlung und der damit verbundenen Tiefpass-Filterung werden nicht alle bei der Transformation möglichen Einzelträger aktiviert, sondern jeweils im unteren und im oberen Bereich eine bestimmte Anzahl von Träger auf „Null“ gesetzt, d. h. beim Mapping mit Null multipliziert.
Die Zusammenstellung in Bild 10.27 gibt schematisiert den Signalablauf beim Mapping mit angenommener 4-PSK und Ausnutzung von 1536 Trägern aus den bei einer 2k-Transformation möglichen 2048 Trägern wieder und zeigt schließlich das einer komplexen Zeitfunktion (komplexe Hüllkurve) zugeordnete Spektrum des OFDM-Signals im Basisband um die Frequenz Null sowie nach Umsetzung auf eine Trägerfrequenz als „Mittenfrequenz“ des OFDM-Spektrums.
Das in Bild 10.27 zugrunde liegende Beispiel basiert auf den Parametern des DAB-Systems, wo 1536 Träger mit Daten belegt sind. Die aus der 2k-Transformation resultierenden weiteren Träger an den äußeren Grenzen des Basisbandes werden auf Null gesetzt, damit im umgesetzten Trägersignal das Spektrum ohne aufwändige Bandpassfilterung auf die vorgegebene Kanalbandbreite begrenzt wird.
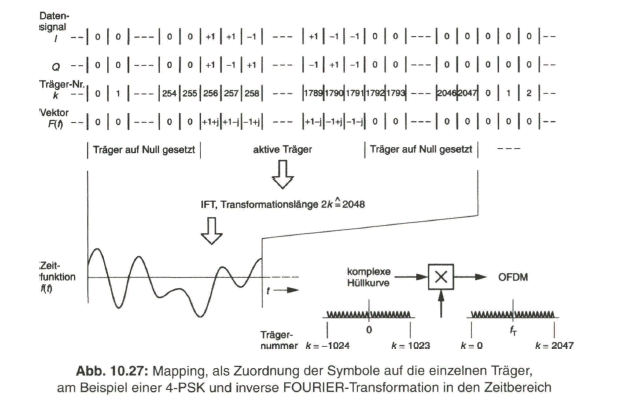
Mit Berücksichtigung eines Schutzintervalls, das über eine Zwischenspeicherung der Realteil- und Imaginärteil-Sequenzen der transformierten Zeitfunktion f(t) und langsameres Auslesen des Speichers entsteht, erhält man das vereinfachte Blockschaltbild zur Erzeugung eines OFDM-Signals, mit hier z. B. 16-QAPSK der Einzelträger, nach Bild 10.28. Auch bei dieser Anwendung der 16-QAPSK erfolgt eine Differenzcodierung der ersten beiden Bits in den Symbolen und für die weiteren Bits eine Zuordnung nach einer GRAY-Mapping-Vorschrift, wie bereits bei 16-QAPSK erläutert wurde.
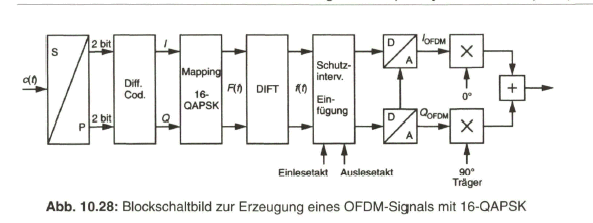
Sowohl die Zeitfunktion als auch das Spektrum eines OFDM-Signals erinnern an ein rauschartiges Signal. Bild 10.29 zeigt dazu das Spektrum eines OFDM-Signals mit 800 Einzelträgern innerhalb eines Frequenzbandes von 8 MHz (oben), d. h. mit einem Trägerabstand von 10 kHz, und eine „Momentanaufnahme“ eines Spektrumausschnitts mit 10 Einzelträgern (unten), bei 64-QAPSK der Einzelträger, aufgenommen mit einem Spektrumanalysator FSEA der Firma Rohde & Schwarz. Der mittlere Träger ist zur „Markierung“ um mehr als 20 dB unterdrückt. Man erkennt, dass der Pegel der Einzelträger je nach der Amplitude des Vektors bis zu 17 dB unterschiedlich sein kann.
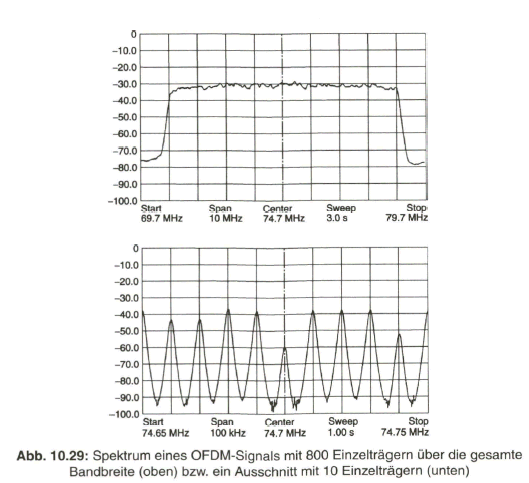
Zur Demodulation des OFDM-Signals wird nach Umsetzung des Empfangssignals in den Zwischenfrequenzbereich eine Analog-Digital-Wandlung vorgenommen, aus der zwei Datenströme hervorgehen, die dem I- und Q-Zweig zugeordnet werden. Es folgt eine Discrete Fast Fourier Transformation (DFFT) und entsprechendes De-Mapping zur Rückgewinnung des übertragenen Datenstroms [24].
11. Übertragung des DVB-Signals
Nach den Vorarbeiten der am europäischen DVB-Projekt beteiligten Institutionen wurden die Ergebnisse von der ETSI (European Telecommunications Standards Institute) als Standards des Digitalen Fernsehens in Europa festgeschrieben in den European Telecommunication Standards
• ETS300 421: Digital broadcasting systems for television, sound and data
services; Framing structure, channel coding and modulation for 11/12 GHz satellite services (Januar 1995).
• ETS 300 429: Digital broadcasting systems for television, sound and data
services; Framing structure, channel coding and modulation for cable systems (November 1994).
• ETS 300 744: Digital broadcasting systems for television, sound and data
services; Framing structure, channel coding and modulation for digital terrestrial television (März 1997) [2, 54].
Im Folgenden werden die Übertragungssysteme unter Bezugnahme auf die bereits in den Abschnitten 9 und 10 beschriebenen Funktionseinheiten mit ihren Leistungsmerkmalen ausführlicher erläutert.
11.1 Satellitenkanal (DVB-S)
Für die großflächige Verteilung von Fernsehsignalen werden „Relaisstellen im AH“ eingesetzt. Die Satelliten befinden sich im geostationären Orbit, d. h. auf einer Umlaufbahn etwa 36.000 km über dem Äquator. Über eine Up-Link-Strecke werden die Signale dem Transponder im Satelliten zugeführt, in eine andere Frequenzlage umgesetzt und in dem für Rundfunksatelliten zugewiesenen Frequenzbereich von 10,7 bis 12,75 GHz zur Erde abgestrahlt. Betreibergesellschaften wie ASTRA oder EUTELSAT stellen die Transponderkanäle den Rundfunkanstalten für die Ausstrahlung von analogen oder digitalen Fernsehsignalen zur Verfügung. Der gesamte Frequenzbereich ist in Teilbänder aufgespaltet. Für die ASTRA-Transponder zur Übertragung von digitalen Fernsehsignalen im so genannten „High Band“ gilt folgende Zuordnung [55]:
• E-Band 11,7 bis 12,1 GHz, Belegung mit 20 Transponderkanälen
• F-Band 12,1 bis 12,5 GHz, Belegung mit 20 Transponderkanälen
• G-Band 12,5 bis 12,75 GHz, Belegung mit 16 Transponderkanälen
Die Transponderkanäle weisen im E- und F-Band eine Bandbreite des Satellitenkanals von 33 MHz auf und eine Bandbreite von 26 MHz im G-Band, bezogen auf einen 1-dB-Abfall [46]. Es wird auf der Frequenzachse abwechselnd mit horizontaler (H) und vertikaler (V) Polarisation abgestrahlt, so dass sich die Transponderkanäle überlappen können. Bild 11.1 zeigt dies am Beispiel der Frequenzbelegung im E-Band [55, 56]. Siehe dazu auch Bild 3.13 mit der Frequenzbänder- und Transponder-Zuordnung im 10/12-GHz-Satellitenband für die Fernsehsignalverteilung.
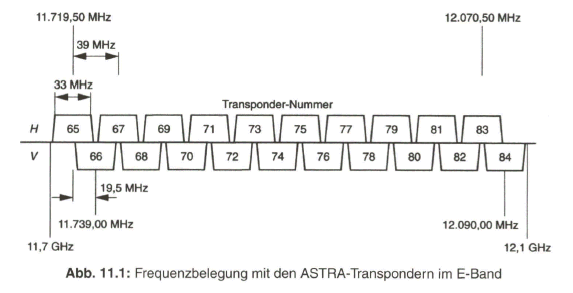
Es werden zusätzlich auch noch Transponderkanäle im B-Band für die Übertragung von digitalen Fernsehsignalen benutzt. Die Bandbreite der Transponder im A-, B-, C- und D-Band beträgt gemäß den früheren Festlegungen zur Übertragung von analogen Fernsehsignalen nur 26 MHz gegenüber 33 MHz im E- und F- Band. Die übertragbare Datenrate ist bei einem 26-MHz-Transponder gegenüber einem 33-MHz-Transponder entsprechend geringer.
Die übertragbare Datenrate berechnet sich bei einem 33 MHz Transponder mit einer resultierenden Modulator-Demodulator-Übertragungsfunktion (Betrag) nach Bild 11.2, mit einer HF-NYQUIST-Bandbreite von ![]() = 27,5 MHz und Roll-Off-Filterung mit einem Roll-Off-Faktor r-0,35, bei 4-PSK-Übertragung als Symbolrate zu
= 27,5 MHz und Roll-Off-Filterung mit einem Roll-Off-Faktor r-0,35, bei 4-PSK-Übertragung als Symbolrate zu
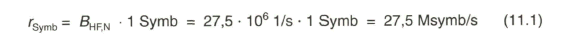
bzw. als Bitrate zu
![]()
Bei einem 26-MHz-Transponder wäre dies mit ![]() = 22 MHz eine übertragbare Datenrate von
= 22 MHz eine übertragbare Datenrate von ![]() = 22 MSymb/s bzw.
= 22 MSymb/s bzw. ![]() = 44 Mbit/s.
= 44 Mbit/s.
Mit Berücksichtigung des REED-SOLOMON-Fehlerschutzes RS (204,188) und einer Coderate der Faltungscodierung R = 3/4 über den 33-MHz-Transponder bzw. R = 5/6 über den 26-MHz-Transponder ergibt das eine Nutz-Bitrate von
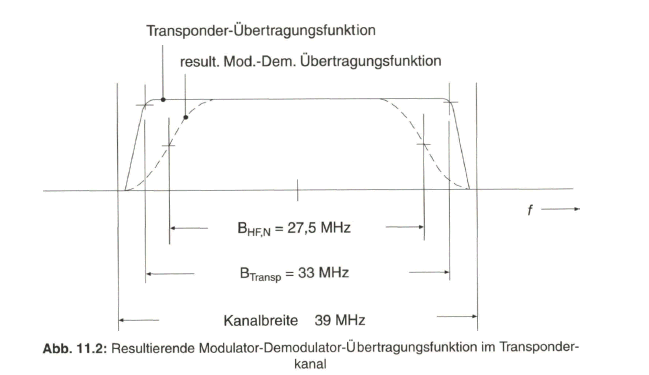
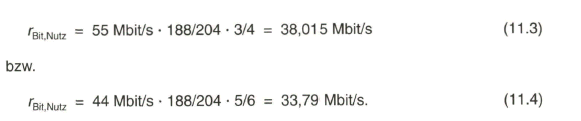
Die Up-Link-Verbindung zu den Satelliten erfolgt in den dafür zugewiesenen RF-Frequenzbändern von 14,0 bis 14,8 GHz und von 17,3 bis 18,3 GHz. Die Aufbereitung des Up-Link-Signals wird zunächst in einem ZF-Modulator bei einer Zwischenfrequenz von 70 MHz oder 140 MHz vorgenommen. Dann folgt die Umsetzung des ZF-Signals in den RF-Bereich. Bild 11.3 gibt das Blockschaltbild der senderseitigen Aufbereitung des digitalen Satellitensignals wieder [56].
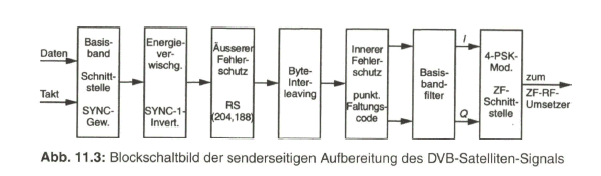
Der ankommende MPEG-2-Transportstrom wird über eine Basisbandschnittstelle mit SYNC-Gewinnung dem Funktionsblock Energieverwischung und SYNC-1-Invertierung zugeführt. Es folgt das Einbringen des äußeren Fehlerschutzes über REED-SOLOMON-Codierung RS (204,188) und anschließend das Byte-Interleaving. Der innere Fehlerschutz wird mit einer Faltungscodierung vorgenommen, wobei durch Punktierung eine Coderate von R= 3/4 bzw. 5/6 eingestellt wird. Die I- und Q-Signale werden über eine Basisbandfilterung mit Wurzel-cos2-Charakteristik und einem Roll-Off-Faktor von r= 0,35 auf die 1,35-fache NYQUIST-Bandbreite begrenzt und dem 4-PSK-Modulator zugeführt. Das Modulationsprodukt wird schließlich über einen ZF-RF-Umsetzer in die Frequenzlage des Up-Link-Kanals gebracht.
Es erfolgt eine Absolutphasencodierung bei der 4-PSK mit dem SYNC-Byte als Referenzsymbol. Das Phasenzustandsdiagramm zeigt Bild 11.4 mit den vier den Dibit-Kombinationen aus dem SYNC-Byte zugeordneten Vektorzuständen. Auf der Empfangsseite wird über Synchrondemodulation das SYNC-Byte zurückgewonnen und mit dem bekannten Wert der Bitfolge 01000111 verglichen. Das SYNC-Byte wird nur dann richtig demoduliert, wenn die Referenzträgerphase identisch ist mit der Phase des Sendesignals. Bei einer Phasenabweichung des zurückgewonnenen Trägers von
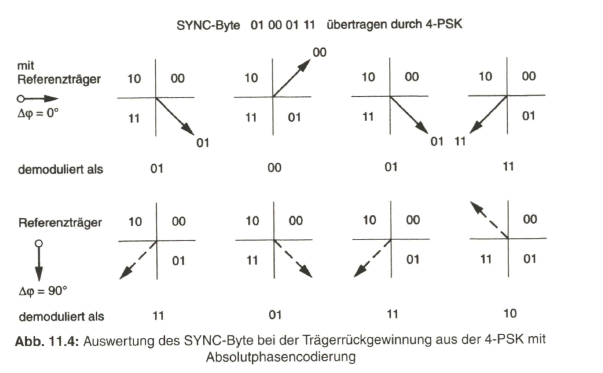
Beim Empfänger wird schrittweise die Phase des Referenzträgers verändert, bis das SYNC-Byte richtig demoduliert wird. Die empfängerseitige Signalverarbeitung zeigt Bild 11.5 im Blockschaltbild [57, 58]. Es läuft im Wesentlichen die Umkehrung der sendeseitigen Signalverarbeitung ab. Das Empfangssignal wird von einem LNC (Low Noise Converter) im Frequenzbereich von 950 bis 2150 MHz dem Satellitenreceiver zugeführt, wo eine weitere Frequenzumsetzung des ausgewählten Kanals auf eine Zwischenfrequenz von 480 MHz erfolgt. Auf dieser Frequenz erfolgt die Synchrondemodulation der I- und Q-Komponenten, wobei die frequenz- und phasenrichtige Referenzträgerschwingung wie oben beschrieben unter Bezugnahme auf das korrekt demodulierte SYNC-Byte gewonnen wird. Am Demodulator muss für den Fall einer Coderate von R- 3/4 des punktierten Faltungscodes ein Träger-zu-Rausch-Abstand von mindestens 7 dB vorliegen.
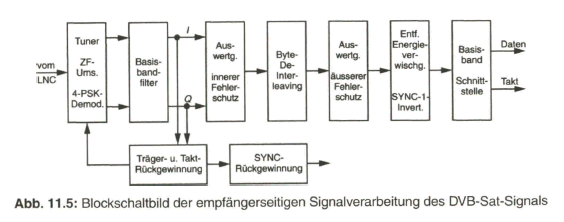
Es folgt das Aufheben der Punktierung und die Auswertung des inneren Fehlerschutzes mittels VITERBI-Decoder. Im Weiteren wird das De-Interleaving und die REED-SOLOMON-Fehlerkorrektur vorgenommen und das SYNC-1-Byte wieder zurückinvertiert. Von der Basisband-Schnittstelle wird der MPEG-2-Transportstrom dem MPEG-Decoder zugeführt [59]. Die Übertragung von digitalen Fernsehsignalen nach dem DVB-S-Standard ist weit verbreitet und hat sich vielfach bewährt. Es liegt nun seit 2003 ein Entwurf für ein neues, verbessertes System DVB-S2 vor, das auf dem bewährten DVB-S-System aufbaut und einen wesentlich erweiterten Anwendungsbereich bietet. DVB-S2 wurde nach dem Entwurf ETSI EN 302 307 entwickelt, um mit Einbeziehung von fortschrittlichen Techniken den höheren Anforderungen des heutigen Satelliten-Fernsehens zu genügen. So ermöglicht DVB-S2 neben Breitband-Übertragungen für Rundfunk-Fernsehdienste mit SDTV und HDTV auch interaktive Dienste einschließlich Internetzugang sowie die kommerzielle Contribution (Verbindungen zwischen Fernsehstudios) und Satellite News Gathering (SNG). Durch die Anwendung von höherstufiger Modulation, 8-PSK, 16- und 32-QAPSK, in Verbindung mit einem wirksameren Fehlerschutz durch eine Verkettung von BCH (BOSE-CHAUDHURI-HOCQUENGHEM)-Code mit LDPC (Low Density Parity Check) erreicht man eine um etwa 30 % höhere Effizienz gegenüber DVB-S.
In Verbindung mit einer effizienteren Videosignalcodierung nach MPEG-4/H.264 bietet DVB-S2 zukünftig die Möglichkeit, über einen herkömmlichen Satellitenkanal zwei bis drei HDTV-Programme zu übertragen. Set-Top-Boxen zum Empfang von HDTV-Signalen sind mittlerweile verfügbar. Neben Test-Ausstrahlungen werden einige verschlüsselte und auch frei empfangbare HDTV-Programme angeboten. Zumindest während einer Übergangsphase von mehreren Jahren werden HDTV-Programme aber auch mit MPEG-2-Codierung übertragen [94].
Die Aufbereitung des DVB-S2-Signals erfolgt in ähnlicher Weise wie bei DVB-S. Bezogen auf das Blockschaltbild in Bild 11.3 tritt beim äußeren Fehlerschutz an Stelle des RS-Codes nun eine BCH-Codierung. Es folgt die innere Codierung mit LDCP Das Byte-Interleaving wird ersetzt durch ein Bit-Interleaving. Überdas Bit- Mapping wird ein I-Q-Datenstrom für das gewählte Modulationsverfahren, QPSK, 8-PSK, 16-QAPSK oder 32-QAPSK, konfiguriert. Die Basisband-Filterung sieht neben einem von DVB-S festgelegten Roll-Off-Faktor des Wurzel-cos2-Filters von r = 0,35 auch noch die Werte von 0,25 oder 0,20 vor.
Die Wahl der FEC (Forward Error Correction)-Parameter hängt von den System-Anforderungen ab. Für Rundfunk-Fernsehdienste kann sowohl mit CCM (Constant Coding and Modulation) als auch mit VCM (Variable Coding and Modulation) gearbeitet werden, um zum Beispiel für SDTV-Programme einen robusten Fehlerschutz und für zusätzlich übertragene HDTV-Programme einen weniger robusten Fehlerschutz zu gewährleisten.
Der nichtlinearen Transponder-Übertragungskennlinie, mit Betrieb nahe der Sättigung, passt man sich bei mehrstufiger Modulation durch Verteilung der Vektor-Endpunkte bei einem Amplitudenwert auf acht Phasenzustände (8-PSK), auf zwei Amplitudenwerte mit darauf 4 bzw. 12 gleichmäßig verteilten Phasenwerten (16-QAPSK) oder auf drei Amplitudenwerte mit 4, 12 und 16 gleichmäßig verteilten Phasenwerten bei der 32-QAPSK an. Das Verhältnis der Amplitudenwerte hängt von der Coderate nach den Vorgaben in der DVB-S2-Spezifikation ab. Bild 11.6 zeigt die Zustandsdiagramme für die 8-PSK und die 16-QAPSK, wie sie bei DVB-S2 definiert sind, mit den zugeordneten Bit-Kombinationen. Die 32-QAPSK ist nur für spezielle Anwendungen vorgesehen [80].
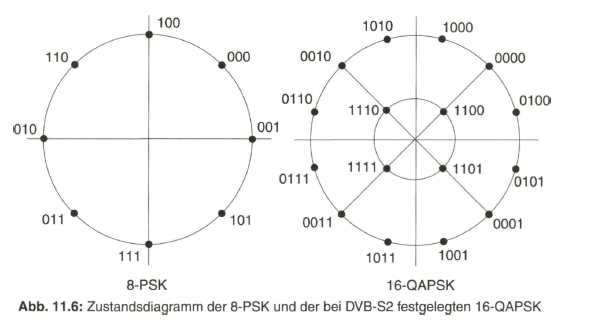
11.2 Kabelkanal (DVB-C)
Zur Übertragung von digitalen Fernsehsignalen im Breitbandkabelnetz werden 8-MHz-Kanäle im UHF-Band ausgenutzt. Der Träger-zu-Rausch-Abstand an der Kabelanschlussdose beim TV-Teilnehmer weist bei analogen Fernsehsignalen üblicherweise einen Wert von etwa 40 dB auf. Wegen möglicher Störungen von analogen Kabelkanälen wird die Trägerleistung des digitalen Fernsehsignals abgesenkt. Mit einem Träger-zu-Rausch-Abstand von 30 dB ist trotzdem noch genügend Sicherheit für die Anwendung der 64-QAPSK vorhanden.
Wie schon früher erwähnt, kommen beim Kabelverteilsystem zu dem Rauscheinfluss noch Störungen durch Reflexionen auf der Kabelstrecke in den Abzweigern hinzu. Für die im Breitband-Kabelnetz verwendeten Komponenten ist eine Rückflussdämpfung frequenzabhängig von 15 bis 20 dB vorgeschrieben. Die durch Reflexionen bedingten Echosignale bleiben so im Wesentlichen mindestens 30 dB unter dem Nutzsignal, was bei 64-QAPSK noch tolerierbar ist. Bei stärkeren Interferenzstörungen müssten diese beim Kabel-Receiver durch einen adaptiven Entzerrer beseitigt werden [2].
Die sendeseitige Aufbereitung des 64-QAPSK-Signals für die Kabeleinspeisung ist in den ersten Stufen identisch mit der beim Satellitenkanal (Bild 11.7). Es entfällt allerdings dann die Faltungscodierung, weil auf Grund des günstigeren Träger-zu-Rausch-Abstandes der äußere Fehlerschutz alleine ausreichend ist.
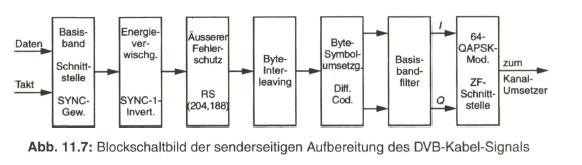
Das byte-weise ausgerichtete Signal aus dem Interleaver wird in einer Byte-Symbol-Umsetzung bei 64-QAPSK auf 6-bit-Symbole aufgeteilt (Bild 11.8), mit jeweils 3 bit im I- und Q-Kanal. Die beiden höchstwertigen Bits werden einer Differenzcodierung unterzogen. Nach Basisbandfilterung über einen Wurzel-cos2-Tiefpass mit dem Roll-Off-Faktor von r= 0,15 gelangen die I- und Q-Signale an den 64-QAPSK-Modulator, wo das Modulationsprodukt wieder in einem Zwischenfrequenzbereich bei 36 MHz aufbereitet wird [2, 59].
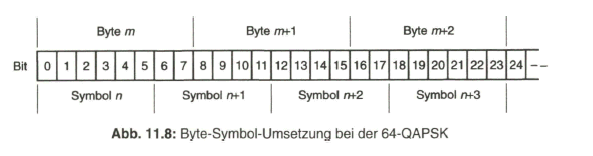
Für das Basisband-Filter gibt der Kabel-Standard nach ETS 300 429 [53] eine sehr geringe Schwankung von nur maximal 0,4 dB und eine Mindestsperrdämpfung wegen der Trennung zum Nachbarkanal von 43 dB vor. Bei voller Ausnutzung eines 8-MHz-Übertragungskanals berechnet sich über
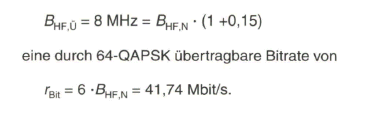
Tatsächlich sieht die ETSI-Empfehlung vor, eine Brutto-Bitrate von 41,34 Mbit/s zu übertragen, womit im 8-MHz-Kanal ein Bereich von ![]() = 7,92 MHz belegt wird. Nach Entfernung des REED-SOLOMON-Fehlerschutzes verbleibt eine Nutz-Bitrate von 38,1 Mbit/s, also nahezu der gleiche Wert wie beim Satellitenkanal mit 38,015 Mbit/s. Damit wird es möglich, das im Satellitenkanal übertragene Programm-Bouquet in das Kabelverteilsystem einzuspeisen. Vielfach findet aber eine Rekonfiguration statt, das heißt ein Neuzusammenstellen des Programmpakets. Dann ist allerdings, wie im Abschnitt 8.2.2 beschrieben, ein Restamping, ein Erneuern der PCR-Zeitmarken erforderlich.
= 7,92 MHz belegt wird. Nach Entfernung des REED-SOLOMON-Fehlerschutzes verbleibt eine Nutz-Bitrate von 38,1 Mbit/s, also nahezu der gleiche Wert wie beim Satellitenkanal mit 38,015 Mbit/s. Damit wird es möglich, das im Satellitenkanal übertragene Programm-Bouquet in das Kabelverteilsystem einzuspeisen. Vielfach findet aber eine Rekonfiguration statt, das heißt ein Neuzusammenstellen des Programmpakets. Dann ist allerdings, wie im Abschnitt 8.2.2 beschrieben, ein Restamping, ein Erneuern der PCR-Zeitmarken erforderlich.
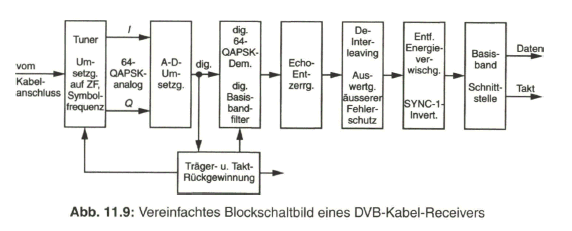
Das vereinfachte Blockschaltbild eines Kabel-Receivers gibt Bild 11.9 wieder. Das Eingangssignal aus dem Hyperband (302 bis 446 MHz) oder aus dem UHF-Band-IV-Bereich (470 bis 606 MHz) wird im Tuner auf eine Zwischenfrequenz um 36,15 MHz gebracht. Es folgt dann eine Umsetzung in den Symbolfrequenz-Bereich über eine Oszillatorfrequenz von 36,15 MHz + 6,89 MHz = 43,04 MHz. Die Symbolfrequenz von 6,89 MHz ergibt sich aus der übertragenen Bitrate von 41,34 Mbit/s und 6 bit/Symbol bei 64-QAPSK. Das analoge 64-QAPSK-Signal um 6,89 MHz wird mit der vierfachen Symbolfrequenz aus einer Taktrückgewinnungsschaltung abgetastet und mit 8 bit pro Codewort analog-digital-gewandelt. Es erfolgt eine digitale Synchrondemodulation und Tiefpass-Filterung. Weiterhin wird eine Echo-Entzerrung bei den I- und Q-Signalen vorgenommen, bevor die Signale dann an die Fehlerkorrektur und die Entfernung der Energieverwischung gelangen [2, 8, 81].
Durch die Anwendung der 64-QAPSK sind DVB-C-Signale sehr empfindlich gegenüber Amplituden- und Gruppenlaufzeitänderungen. Bei 64-QAPSK wird am Demodulatoreingang mindestens ein Träger-zu-Rausch-Abstand von C/N > 26 dB gefordert, um mit der Fehlerkorrektur durch Auswertung des REED-SOLO-MON-Fehlerschutzes eine Bitfehlerhäufigkeit von BER < 10'11 zu erreichen. Siehe dazu auch Bild 9.14. Kritisch sind vor allem Unterbrechungen oder Fehlanpassungen in der Zuführung von der Kabelanschlussdose zum Kabel-Receiver. Die in den digitalen Kabelkanälen übertragenen Programmsignale werden vielfach als ganze „Programmpakete” aus der digitalen Satellitenübertragung übernommen. So z. B. die beiden „ARD-Digital”-Programmpakete über die Transponder 71 und 85 sowie das „ZDF-Vision”-Programmpaket über den Transponder 77, mit jeweils acht oder neun Fernsehprogrammen, auf dem Satelliten ASTRA 1-H.
Die Brutto-Bitrate des vom Satelliten empfangenen Sende-Transportstroms beträgt einschließlich Fehlerschutz 55 Mbit/s. Nach Auswertung des Fehlerschutzes verbleiben als Netto-Bitrate 38,015 Mbit/s. Die ETSI-Empfehlung für den Kabel-Standard sieht für einen 8-MHz-Kabelkanal bei 64-QAPSK die Übertragung einer Netto-Bitrate von 38,1 Mbit/s vor. Das bedeutet, dass eine Anpassung der Datenrate erfolgen muss. Dies geschieht über das Einbringen von so genannten „Stopf-Bits" (als Null-Bits). Der damit verursachte mögliche Jitter im Datenstrom muss innerhalb sehr enger Grenzen bleiben, um eine sichere Taktrückgewinnung auf der Empfängerseite zu gewährleisten. Siehe dazu auch 8.2.2, Seite 134.
Bei der Einspeisung von Satellitensignalen in das Kabelverteilnetz werden zunächst aus dem MPEG-2-Transportstrom vom Satelliten-Receiver die gewünschten Programme über deren PCR ausgewählt. Dann erfolgt ein Re-Multiplexing mit den Programmströmen bei gleichzeitiger Neubildung der jeweiligen Program Clock Reference. Siehe dazu auch die Zusammensetzung des Sende-MPEG-2-Transportstroms nach Bild 8.5. Der DVB-Kabel-Standard nach EN 300 429 sieht neben der 64-stufigen Quadratur-Amplitudenmodulation (64-QAPSK) auch eine 16- oder 32-stufige Modulation vor sowie die höherstufigen Varianten 128-QAPSK oder 256-QAPSK. Bei der 128-QAPSK werden 7 Bits zu einem Symbol und bei der 256-QAPSK werden 8 Bits zu einem Symbol zusammengefasst. Je höherstufiger das Modulationsverfahren ist, umso höher werden die Anforderungen an die Störsicherheit im Übertragungskanal. Die 256-QAPSK könnte später auch in Europa für die Übertragung von HDTV-Signalen im Kabelnetz zur Anwendung kommen mit einem entsprechend wirksameren Fehlerschutz. In den USA findet die Übertragung von digitalen Fernsehsignalen im Kabelnetz bereits mit 256-QAPSK statt.
11.3 Terrestrischer Funkkanal (DVB-T)
Die Umstellung der terrestrischen Fernsehsignalverteilung von analogem auf digitales Fernsehen vollzieht sich in Europa und weltweit mit unterschiedlichem Fortschritt. Während in Großbritannien schon seit dem Jahr 2000 und seit 2002 auch in Spanien flächendeckend digitales terrestrisches Fernsehen in Gleichwellennetzen eingeführt ist, vollzog sich in Deutschland ab 2003 eine inselweise Einführung von DVB-T, oder wie werbewirksam als „Das Überall Fernsehen“ bezeichnet, ausgehend von Berlin und Potsdam über weitere Ballungszentren in Nord- und Westdeutschland bis zum DVB-T-Start Ende Mai 2005 in den Räumen München und Nürnberg sowie in Südbayern. Nach und nach werden weitere Regionen von Analog-TV auf DVB-T umgestellt. Es kommt weitgehend 8k-OFDM mit 16-QAPSK zur Anwendung mit einer Coderate des Faltungscodes von R= 2/3. Die Dauer des Schutzintervalls wird abhängig von der Netz-Struktur in den Versorgungsgebieten mit 1/4 oder 1/8 der Symboldauer gewählt.
Bei der 8k-Transformation werden theoretisch 8192 Einzelträger generiert. Mit einer Symboldauer von ![]() = 896
= 896 ![]() , die sich aus der Abtastperiodendauer von
, die sich aus der Abtastperiodendauer von ![]() = 7/64
= 7/64 ![]() = 0,109375
= 0,109375 ![]() (Abtastfrequenz
(Abtastfrequenz ![]() = 9,143 MHz) und den 8192 Abtastwerten pro Zeitfenster der FOURIER-Transformation ergibt, folgt für den Frequenzabstand der Einzelträger ein Wert von
= 9,143 MHz) und den 8192 Abtastwerten pro Zeitfenster der FOURIER-Transformation ergibt, folgt für den Frequenzabstand der Einzelträger ein Wert von ![]() = 1,116 kHz. Das gesamte Spektrum der 8192 Einzelträger würde nun einen Frequenzbereich von 9,142... MHz belegen. Für die Übertragung des DVB-T-Signals in 8-MHz-UHF-Kanälen wird die Anzahl der ausgenutzten Träger auf 6817 begrenzt, womit ein Frequenzband von 7,611 MHz belegt wird. Die außerhalb der Bandgrenzen liegenden Träger werden unterdrückt.
= 1,116 kHz. Das gesamte Spektrum der 8192 Einzelträger würde nun einen Frequenzbereich von 9,142... MHz belegen. Für die Übertragung des DVB-T-Signals in 8-MHz-UHF-Kanälen wird die Anzahl der ausgenutzten Träger auf 6817 begrenzt, womit ein Frequenzband von 7,611 MHz belegt wird. Die außerhalb der Bandgrenzen liegenden Träger werden unterdrückt.
Bei der Übertragung des DVB-T-Signals in 7-MHz-VHF-Kanälen wird die Abtastfrequenz auf ![]() = 8,000 MHz geändert. Bei weiterhin 8192 Abtastwerten pro Zeitfenster erhält man eine Symboldauer von
= 8,000 MHz geändert. Bei weiterhin 8192 Abtastwerten pro Zeitfenster erhält man eine Symboldauer von ![]() = 1024
= 1024 ![]() und damit einen Abstand der Einzelträger von
und damit einen Abstand der Einzelträger von ![]() = 0,976... kHz. Mit den auch im 7-MHz-Kanal verwendeten 6817 Nutzträgern wird damit ein Frequenzband von 6,657... MHz belegt. Der größte Teil der Subträger, nämlich 6048, dient zur Übertragung der eigentlichen Nutzinformation. Die restlichen 769 Subträger übernehmen die Funktion von Pilotträgem zur Übertragung von Synchronisierungs- und Signalisierungsinformationen. Wie schon im Abschnitt 10.4.2 erläutert, wird zur Unterdrückung von Effekten eines ungewollten oder gewollten Mehrfachempfangs bei der Auswertung der empfangenen Datensymbole in deren Anfangsbereich ein Schutzintervall eingefügt. Die Dauer des Schutzintervalls beträgt üblicherweise 1/4 oder 1/8 der Symboldauer, wie eingangs schon beschrieben.
= 0,976... kHz. Mit den auch im 7-MHz-Kanal verwendeten 6817 Nutzträgern wird damit ein Frequenzband von 6,657... MHz belegt. Der größte Teil der Subträger, nämlich 6048, dient zur Übertragung der eigentlichen Nutzinformation. Die restlichen 769 Subträger übernehmen die Funktion von Pilotträgem zur Übertragung von Synchronisierungs- und Signalisierungsinformationen. Wie schon im Abschnitt 10.4.2 erläutert, wird zur Unterdrückung von Effekten eines ungewollten oder gewollten Mehrfachempfangs bei der Auswertung der empfangenen Datensymbole in deren Anfangsbereich ein Schutzintervall eingefügt. Die Dauer des Schutzintervalls beträgt üblicherweise 1/4 oder 1/8 der Symboldauer, wie eingangs schon beschrieben.
Die technische Realisierung des digitalen terrestrischen Fernsehens sowohl auf der Sende- als auch auf der Empfangsseite ist im Vergleich zu dem digitalen Fernsehen im Satellitenkanal und im Kabelkanal wesentlich komplexer. Der Aufwand an Hardware und Software ist beachtlich, schon alleine durch die implementierte FOURIER-Transformation mit z. B. 8k Transformationslänge, die in weniger als einer Millisekunde ablaufen muss. Die sendeseitige Signalverarbeitung ist im Blockschaltbild in Bild 11.10 dargestellt [2, 24, 58], Zugrunde liegt eine nichthierarchische Modulation. In den ersten Funktionsstufen ist die Signalverarbeitung wieder identisch mit der beim Satellitenkanal.
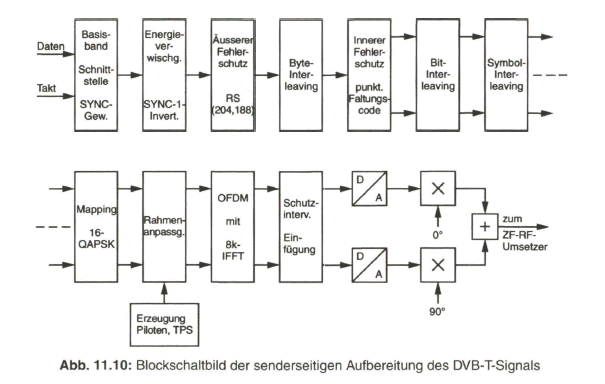
Neben dem Byte-Interleaving kommt jetzt, nach dem inneren Fehlerschutz, noch ein Bit-Interleaving und ein Symbol-Interleaving hinzu. Im Bit-Interleaver werden jeweils Blöcke von 126 Bits systematisch umsortiert und dann, bei Anwendung der 16-QAPSK, auf vier parallele Ausgänge verteilt, die mit dem Symbol-Interleaver verbunden sind. Sinn des Bit-Interleaving ist es, zeitlich aufeinanderfolgende Nutzbits auf weit auseinanderliegende Träger zu verteilen, so dass selbst bei einer Störung mehrerer nebeneinander liegender Träger (siehe dazu Bild 10.19) eine Korrektur von Bitfehlern über den VITERBI-Decoder möglich ist. Durch das Symbol-Interleaving erfolgt eine Umsortierung innerhalb von neu gebildeten Blöcken. Außerdem wird dabei der ausgehende Nutz-Datenstrom immer dann unterbrochen, wenn ein Pilot eingefügt werden soll [72].
In dem nachfolgenden Mapping erfolgt die Zuordnung der einzelnen Bits auf die I- bzw. Q-Achse im Konstellationsdiagramm. Es wird nach einer GRAY-Codierung vorgenommen, wobei direkt benachbarte Konstellationspunkte sich jeweils in nur einem Bit unterscheiden. Nach dem Mapping werden Daten-Rahmen gebildet, in denen die Pilotträger eingebracht werden, die zur Kanalschätzung und -korrektur sowie zur Übermittlung von Übertragungsparametern dienen. Es folgen dann die eigentliche OFDM, mit der Inverse Fast FOURIER Transformation (IFFT), die Einfügung des Schutzintervalls und nach einer Filterung die Digital-Analog-Wandlung sowie die Aufbereitung im Zwischenfrequenzbereich.
Das OFDM-Signal wird in den Rahmen (frames) organisiert. Jeder Rahmen enthält 68 OFDM-Symbole (siehe dazu Bild 10.21,68-mal ![]() auf der Zeitachse) und jedes OFDM-Symbol wieder 6817 Träger (siehe dazu in Bild 10.21, Träger auf der Frequenzachse) im 8k-Modus bzw. 1705 Träger im 2k-Modus. Für die Symboldauer ist nun der Wert
auf der Zeitachse) und jedes OFDM-Symbol wieder 6817 Träger (siehe dazu in Bild 10.21, Träger auf der Frequenzachse) im 8k-Modus bzw. 1705 Träger im 2k-Modus. Für die Symboldauer ist nun der Wert ![]() einschließlich des Schutzintervalls einzusetzen.
einschließlich des Schutzintervalls einzusetzen.
Die Pilotträger weisen eine definierte Amplitude und eine Phasenlage von 0° oder 180° auf. Sie werden unterschieden in Continual Pilots, notwendig zur Frequenzsynchronisation beim Empfänger, und Scattered Pilots zur Kanalschätzung, das heißt zur Ermittlung der aktuellen Übertragungsfunktion H(f) des Kanals. Dazu kommen die Transmission Parameter Signalling (TPS)-Träger zur Übermittlung verschiedener Übertragungsparameter.
Die „ständigen Piloten“, die Continual Pilots, sind festen Trägerpositionen zugeordnet und damit auch dem Empfänger bekannt. Ihre Verteilung ist so gewählt, dass keine Periodizitäten vorliegen. Der Empfänger sucht das Spektrum nach den Continual Pilots ab und stellt sich dann über die Automatic Frequency Control (AFC) auf die ausgewählte Senderfrequenz ein. Voraussetzung ist allerdings, dass sich der Empfänger mit Hilfe eines Autokorrelations-Algorithmus bereits auf die richtige Position des FFT-Abtastfensters, also nach dem Schutzintervall, innerhalb der übertragenen Symbole eingestellt hat.
Die „verstreuten Piloten“, Scattered Pilots, wechseln ihre Position über drei Träger hinweg im Symboltakt über den gesamten Bereich der Einzelträger. Somit wird jeder dritte Träger in gewissem Rhythmus vom Nutzträger zum Pilotträger. Innerhalb eines Symbols hat jeder zwölfte Träger die Funktion eines Scattered Pilot (Bild 11.11). Die Amplitude und Phase der Scattered Pilots sind fest definiert. Ihre Auswertung liefert dem Empfänger Kriterien für eine auf jeden Unterträger bezogene Korrektur, über eine komplexe Multiplikation desselben mit dem Korrekturwert. Man könnte diesen Vorgang mit einer frequenzselektiven automatischen Verstärkungs- und Phasenregelung mittels eines schrittweisen Wobbelsignals vergleichen.
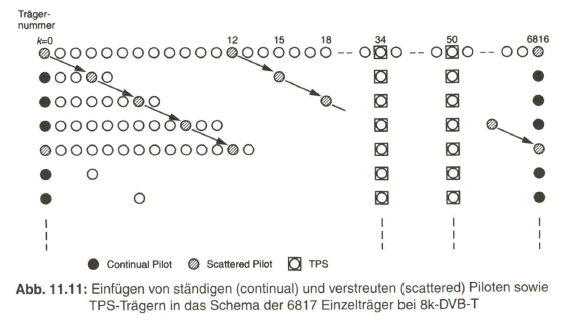
Continual Pilots und Scattered Pilots sind im Pegel um 2,5 dB gegenüber dem Maximalpegel auf der I-Achse (bei 16- oder 64-QAPSK) angehoben.
In Bild 11.12 sind im Konstellationsdiagramm der 16-QAPSK die Vektorpositionen der Continual oder Scattered Pilots sowie der TPS-Träger zu erkennen [61 ].
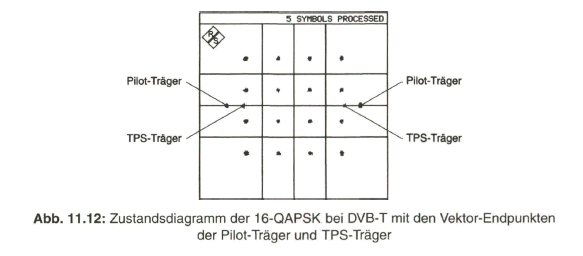
Mittels der Träger für Transmission Parameter Signalling (TPS) werden an den Empfänger die relevanten Eigenschaften des Übertragungsverfahrens weitergegeben, wie
• Modulationsverfahren (QPSK, 16-QAPSK, 64-QAPSK)
• nichthierarchische oder hierarchische Modulation (a = 1,2, 4)
• Coderate des Faltungscoders (R = 1/2, 2/3, 3/4, 5/6, 7/8)
• Schutzintervall (1/32, 1/16, 1/8, 1/4)
• Transformationslänge (2k oder 8k).
Die TPS-lnformation besteht aus 68 Bits. Das erste Bit („0“) dient zur Initialisierung. Es folgt ein 16-bit-Synchronisationswort. Die letzten 16 bit beinhalten einen Fehlerschutz. Die Signalübertragung auf den TPS-Trägern erfolgt mittels einer störsicheren 2-PSK und Phasendifferenzcodierung (DBPSK). Der Empfänger kann sich damit auch bei ungünstigen Empfangsbedingungen auf die richtigen Übertragungsparameter einstellen [24]. Ausschnittsweise werden im Folgenden die Positionen der Continual Pilots und der Transmission Parameter Signalling-Trägertür den 8k-Modus im Bereich der Einzelträger von k = 0 bis k = 6816 angegeben [60].
Tab. 11.1: Continual Pilots, insgesamt 177
0 48 54 87 141 156 192 201 255 279 282 333 432 ...
6249 6252 6258 6318 6381 6435 6489 6603 6795 6816
Tab. 11.2: TPS - Träger, insgesamt 68
34 50 209 346 413 569 595 688 790 901 1073 1219 ...
5800 5902 6013 6185 6331 6374 6398 6581 6706 6799
Tabelle 11.3 zeigt abschließend eine Zusammenstellung der wesentlichen Parameter und der übertragbaren Bitraten bei der Anwendung des OFDM-Verfahrens beim digitalen terrestrischen Fernsehen DVB-T [60].
Tab. 11.3: Parameter und Bitraten bei DVB-T nach ETS 300 744 für einen 8-MHz-Kanal [60], Bei DVB-T in Deutschland übertragene Werte für Brutto-Bitrate und Netto- Bitrate sind unterstrichen.
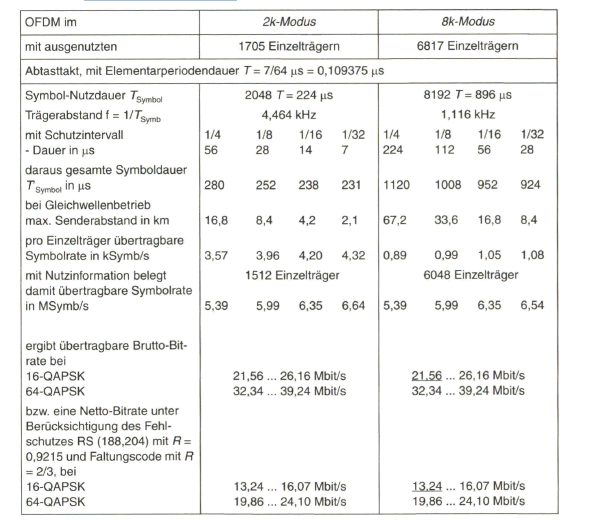
Für einen 7-MHz-Kanal (VHF) ändert sich die Symbol-Nutzdauer auf ![]() = 256 liS im 2k-Modus bzw.
= 256 liS im 2k-Modus bzw. ![]() = 1024 jus im 8k-Modus. Die mit 16-QAPSK übertragbare Nettobitrate beträgt abhängig vom Schutzintervall nun 9,95 ... 12,06 Mbit/s im Vergleich zu 13,24 ... 16,07 Mbit/s in einem 8-MHz-Kanal (UFIF).
= 1024 jus im 8k-Modus. Die mit 16-QAPSK übertragbare Nettobitrate beträgt abhängig vom Schutzintervall nun 9,95 ... 12,06 Mbit/s im Vergleich zu 13,24 ... 16,07 Mbit/s in einem 8-MHz-Kanal (UFIF).
Unter üblichen Bedingungen können damit in einem VHF-Kanal mindesten 3 SDTV-Programme und in einem UHF-Kanal mindestens 4 SDTV-Programme übertragen werden. Wegen der geringeren Störempfindlichkeit im VHF-Bereich gegenüber dem UHF-Bereich wird in den 7-MHz-Kanälen der Faltungscode mit einer Coderate von R = 3/4 eingebracht, was wiederum die Übertragung einer Nettobitrate von mindestens 13,06 Mbit/s für 4 SDTV-Programme erlaubt. Ergänzend dazu ist es möglich, Datendienste oder spezielle Service-Angebote im Rahmen von DVB-H zu übertragen.
11.4 Versorgung von tragbaren Empfangsgeräten (DVB-H)
Der geschaffene Standard DVB-H (Digital Video Broadcasting-Transmission System for Handheld Terminals) [82] ist ein Ableger des DVB-T Standards mit Berücksichtigung der speziellen Situation bei kleinen batteriebetriebenen Geräten zum Empfang von Rundfunk-Fernseh-Diensten. Der Systemstart erfolgte in einigen europäischen Ländern, so auch in Deutschland, in den Jahren 2005 und 2006 in den regulären UHF-Kanälen (theoretisch möglich auch in VHF-Kanälen). Interessiert sind neben den Fernsehprogrammanbietern vor allem die Mobilfunkbetreiber wegen der möglichen hohen Übertragungskapazität. Die vorgesehenen Datenraten sind bei DVB-H mit bis zu 15 Mbit/s deutlich höher als bei den Mobilfunksystemen. Wegen der geringen Abmessung der Geräteantennen ist das Empfangssignal sehr störanfällig. Zu dem Mehrwegeempfang kommen Störungen von analogen und digitalen Fernsehsendern sowie vom Mobilfunk im benachbarten GSM-Band, wie auch Störspektren von Elektrogeräten und Kfz-Zündanlagen hinzu.
Mit der Vorgabe, dass bei DVB-H dieselbe Schnittstelle für den Transportstrom gilt wie bei DVB-T, kann die Ausstrahlung über bereits bestehende DVB-T-Sender erfolgen. Die Unterscheidung des DVB-H-Transportstroms vom DVB-T-Transport-strom wird durch eine zusätzliche Signalisierung von bestimmten Parametern der DVB-H-Elementarströme vorgenommen. Wesentlich neu beim DVB-H-Transport- strom sind das Zeitschlitzverfahren (Time Slicing) und der erweiterte Fehlerschutz (Multi Protocol Encapsulation Forward Error Correction MPE-FEC). Das Hauptproblem bei den Handheld-Empfangsgeräten liegt in der begrenzten Energie der Stromversorgung. Ein portabler DVB-T-Empfänger mit HF-Tuner, Demodulator und Decoder für höhere Datenraten benötigt bisher eine Leistung von etwa 500 bis 600 mW aus den Akkus. Für einen DVB-H-Empfänger werden maximal 100 mW zugestanden.
Bei einem DVB-T-Empfänger muss zunächst der gesamte Datenstrom decodiert werden, bevor der Zugriff zu einem bestimmten Programm oder Dienst möglich ist. Weniger Leistung wird verbraucht, wenn nur der Teil des gesamten Datenstroms im Empfangsteil und Decoder verarbeitet werden muss, der die Daten des gewünschten Dienstes enthält. Dies ist möglich durch eine Umstrukturierung des Datenstroms, indem nach dem Zeitschlitzverfahren die Daten eines jeden Dienstes periodisch in komprimierten Datenpaketen, den Bursts, gesendet werden.
Ein einzelner Dienst wird zeitweise mit hoher Datenrate übertragen, zwischenzeitlich überhaupt nicht (Time Slicing). Durch den Zeitmultiplex von mehreren Diensten entsteht ein kontinuierlicher Datenstrom mit konstanter Datenrate. Das ausgestrahlte Sendesignal kann vom Empfänger zeitselektiv empfangen und decodiert werden, wenn die genaue Lage des zum ausgewählten Dienst gehörigen Bursts bekannt ist. Lediglich beim Erstzugriff muss der Empfänger noch einige Sekunden den gesamten kontinuierlichen Datenstrom auswerten. Nach der Synchronisierung auf den gewünschten Dienst kann der Empfangsteil zwischendurch abgeschaltet werden. Die ausgewählten Datenbursts werden in einen Speicher eingelesen und mit der eigentlichen konstanten Datenrate des betreffenden Dienstes ausgelesen. Die Dauer eines Datenbursts beträgt einige 100 ms. Für Einschaltverzögerung und Synchronisation kann von etwa 250 ms ausgegangen werden. Bei einer Abschaltzeit von mehreren Sekunden ergibt sich je nach dem Verhältnis von Einschalt-zu-Ausschaltzeit eine Reduzierung des mittleren Leistungsverbrauchs aus den Akkus auf etwa 10 %.
Der aus den Bursts von verschiedenen Diensten zusammengesetzte DVB-H-Datenstrom kann wiederum mit anderen zeitkontinuierlichen Datenströmen z. B. von DVB-T-Transportströmen gemultiplext werden. Nach einem Beispiel in [83] werden in einem DVB-T-Kanal mit einer Nutzbitrate von 13,27 Mbit/s drei Fernsehprogramme mit je 3,35 Mbit/s und an Stelle eines vierten TV-Programms in den verbleibenden 3,2 Mbit/s acht DVB-H-Dienste mit je 400 kbit/s übertragen. Mit einer Burstdauer von etwa 600 ms bei einer Zykluszeit von 5 s enthält jeder Burst eine Datenmenge von 2 Mbit. Siehe dazu Bild 11.13.

Die relativ lange Zykluszeit von 5 s erweist sich auch als vorteilhaft beim so genannten „Handover“, wo am Übergang in eine neue Funkzelle bei der Suche nach einem Burst mit dem gleichen Dienst ein für den Benutzer unmerklicher Kanalwechsel erfolgt. Im DVB-H-System werden die Daten der einzelnen Dienste auf der Basis des Internet Protocol (IP) übertragen. Das Einbringen der IP-Daten in den MPEG-2 Sende-Transportstrom wird mit Hilfe eines Anpassungsprotokolls, der Multi Protocol Encapsulation (MPE) vorgenommen. Im DVB-T-Transportstrom ist der zweistufige Fehlerschutz mit dem äußeren RS-Code und dem inneren Faltungscode implementiert. Wegen der Vorgabe von Mobilempfang mit sehr kleinen Antennen ist bei DVB-H ein zusätzlicher Fehlerschutz auf der Ebene des IP-Datenstroms vor dem Transportstrom-Multiplexer notwendig. Man spricht in diesem Fall von der Multi Protocol Encapsulation Forward Error Correction (MPE-FEC).
Der zusätzliche Fehlerschutz besteht aus einem REED-SOLOMON-Code (RS 255,191) in Verbindung mit einem umfangreichen Block-Interleaving. Der MPE-FEC wird getrennt für jeden IP-Elementarstrom berechnet und den eigentlichen Nutzdaten hinzugefügt. In der Multi Protocol Encapsulation (MPE) werden die Datenströme der einzelnen Dienste in einem Multiplex zusammengefasst und anschließend im Time Slicing den periodisch sich wiederholenden Bursts zugeordnet. Im DVB-Transportstrom-Multiplexer wird der resultierende DVB-T-Transportstrom gebildet und dem OFDM-Modulator zugeführt. Bild 11.14 zeigt dies in einem Blockschema [83].
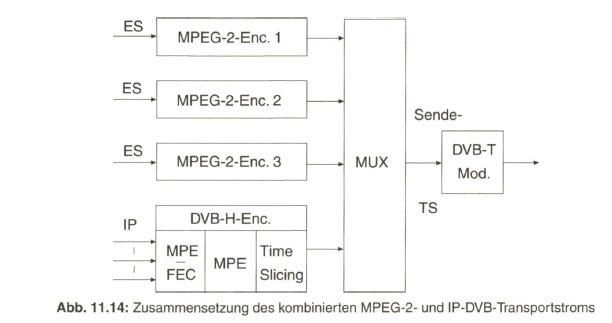
Die Übermittlung von Übertragungsparametern der im kombinierten Multiplex enthaltenen DVB-H-Elementarströme erfolgt im TPS-Kanal (Transmission Parameter Signalling). Darin werden bei DVB-T zunächst nur Informationen übertragen, die der Empfänger für die Kanalabstimmung und die Einstellung des Demodulators benötigt. Die nun ergänzenden Informationen teilen dem Empfänger das Vorhandensein von IP-Elementarströmen in Time-Slicing-Betrieb und eines MPE-FEC sowie weitere notwendige Informationen über neu definierte Übertragungsmodi mit. Dazu zählt insbesondere ein weiterer OFDM-Modus. Neben den im DVB-T-Standard festgelegten 2k- und 8k-Modi lässt der DVB-H-Standard auch einen 4k-Modus zu. Der 4k-Modus ist allerdings nur bei reinem DVB-H-Betrieb zulässig. Er stellt einen Kompromiss dar zwischen dem nur für kleinen Senderabstand in Gleichwellennetzen geeigneten 2k-Modus und dem beim Mobilempfang störanfälligen DOPPLER-Spektrum beim 8k-Modus mit gegenüber dem 2k-Modus vierfachem möglichen Senderabstand.
Die Spezifikation des DVB-H-Standards lässt neben den bislang weltweit genutzten Kanal-Bandbreiten im VHF- und UHF-Bereich mit 6, 7 und 8 MHz auch eine Kanalbandbreite von 5 MHz zu. Damit wird der Einsatz von DVB-H auch außerhalb der für terrestrische Fernsehsignalverteilung zugewiesenen Frequenzbänder möglich [83]
.
11.5 Digital Multimedia Broadcasting (DMB)
Im Gegensatz zu DVB-H ist Digital Multimedia Broadcasting (DMB) eine auf dem DAB-System (Digital Audio Broadcasting) basierende Technologie. DMB ist speziell für den mobilen Empfang von Videodiensten auf Handhelds oder Mobiltelefonen ausgelegt. Ein Vorteil von DMB gegenüber DVB-T und DVB-H ist die Möglichkeit des mobilen Empfangs auch bei hohen Geschwindigkeiten. Während DVB-T- Empfang schon bei etwas mehr als 100 km/h starke Aussetzer aufweist, soll DMB auch bei Geschwindigkeiten von 200 km/h noch einwandfrei funktionieren.
Die Aufbereitung des zu übertragenden MPEG-4-Videosignals mit AVC-Codierung erfolgt mit einem speziellen DMB-Prozessor, der zur Zeit von zwei koreanischen Firmen hergestellt wird. In Südkorea ist das DMB-System bereits fest eingeführt, wobei die Übertragung über den Satellitenkanal (S-DMB) erfolgt. Das terrestrische System (T-DMB) ist in Korea bereits als digitales Rundfunksystem in Betrieb. Ein DMB-fähiges Gerät kann auch die in Europa übertragenen DAB-Programme empfangen, so wie auch der Ton von DMB-Ausstrahlungen mit normalen DAB-Radios empfangen werden kann. DMB-Videoübertragungen benötigen nur eine Datenrate von einigen hundert kbit/s. Dies ist mit der hohen Datenreduktion durch AVC und der für kleine Bildschirme geringeren Anzahl von Pixeln möglich. Vom Institut für Rundfunktechnik (IRT) wird ein DMB-Dienst mit der Datenrate von 496 kbit/s über zwei Sender in München ausgestrahlt. Neben Programmübernahmen von ARD-EinsExtra und ZDF-Infokanal werden Videoclips von weiteren Programmen eingefügt. Die Inhalte sind dem Konzept des Mobiltelefons, wie kleiner Bildschirm und kurze Nutzungsdauer, angepasst [95].
Die Übertragung von DAB- und damit auch DMB-Programmen erfolgt über HF- Kanäle mit 1,5 MHz Bandbreite im VHF-Bereich, Band III im ursprünglichen Fernsehkanal 12 sowie zukünftig auch im Fernsehkanal 11 (siehe dazu Bild 3.12) mit jeweils 4 Blöcken (11 A - D und 12 A - D) und im UFIF-Bereich im L-Band mit 9 Blöcken (L A -1). Beim DAB-System kommt OFDM mit 1536 aktiven Trägern (Mode I) mit 4-PSK zur Anwendung. Ein Schutzintervall mit einem Viertel der Symboldauer von ![]() - 1024
- 1024 ![]() wird eingefügt. Die übertragbare Brutto-Datenrate beträgt 2,4 Mbit/s. Bei einem hohen Fehlerschutz beträgt die Netto-Datenrate etwa 1,2 Mbit/s [96].
wird eingefügt. Die übertragbare Brutto-Datenrate beträgt 2,4 Mbit/s. Bei einem hohen Fehlerschutz beträgt die Netto-Datenrate etwa 1,2 Mbit/s [96].
11Fernsehtechnik.pdf
12. Vergleich der Signalaufbereitung und Signalverteilung
12.1 Analoges Fernsehen
Wie in den Abschnitten 2 und 3 ausführlich beschrieben wird beim analogen Fernsehen aus den Farbwertsignalen R, G, B sowie dem Austast- und Synchronsignal ein PAL-FBAS-Signal aufbereitet, das aus dem Frequenzbereich von 0...5 MHz dem hochfrequenten Kanalträger aufmoduliert wird. Dies geschieht bei der terrestrischen Funkübertragung und bei der Breitband-Kabelverteilung durch Restseitenband-Amplitudenmodulation. Parallel zum amplitudenmodulierten Bildträger wird im Fernsehkanal mit 7 MHz (VHF) bzw. 8 MHz (UHF) Bandbreite einem Tonträger 5,5 MHz oberhalb des Bildträgers das analoge Tonsignal durch Frequenzmodulation aufgebracht. Im Falle der Zweitonübertragung wird zusätzlich ein zweiter Tonträger etwa 250 kHz oberhalb des ersten Tonträgers mit dem zweiten Tonsignal frequenzmoduliert.
Bei der Übertragung im Satellitenkanal mit 26 MHz Bandbreite wird im Basisband neben dem PAL-FBAS-Signal ein Tonträger bei 6,5 MHz vom analogen Mono-Tonsignal frequenzmoduliert. Daneben kommen bei Stereo-Tonübertragung noch eigene FM-Unterträger bei 7,02 und 7,20 MHz hinzu sowie gegebenenfalls zusätzlich weitere digital modulierte Unterträger. Das gesamte Basisband, das nun von 0...8,4 MHz reicht, wird dem hochfrequenten Kanalträger für die Aufwärtsstrecke zum Satelliten durch Frequenzmodulation aufgebracht. Bild 12.1 gibt dies in einem vereinfachten Blockschaltbild wieder.
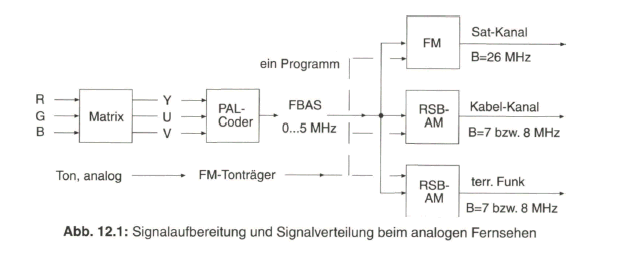
12.2 Digitales Fernsehen
Die Aufbereitung des beim digitalen Fernsehen übertragenen Video- und Audiosignals muss in mehreren Stufen betrachtet werden. Ausgangspunkt sind zunächst wieder die analogen Farbwertsignale R, G, B, verbunden mit dem Austastsignal, sowie das analoge Mono-, Stereo- oder Mehrkanal-Tonsignal. Die Farbwertsignale werden in die Komponentensignale Y sowie (B-Y) und (R-Y) matriziert, wobei die reduzierten Farbdifferenzsignale als Digitalsignale nun mit CB und CR bezeichnet werden. Nach Analog-Digital-Wandlung der Komponentenvideosignale sowie der analogen Tonsignale wird nach dem Zeitmultiplex-Verfahren in einem Multiplexer ein serielles DSC-270 Mbit/s-Studiosignal gebildet, das nun über die Zeitreferenzsignale die digitale Synchronisierinformation enthält, sowie einen oder mehrere Tonkanäle.
Die Bitrate von 270 Mbit/s ist zu hoch, um dieses Signal über die herkömmlichen Verteilwege dem Fernsehteilnehmer zuzuführen. Es wird deshalb in dem MPEG-2-Video- und Audio-Encoder über Redundanz- und Irrelevanzreduktion eine wesentliche Datenreduktion vorgenommen. Ein gemeinsamer 27-MHz-Takt (System Time Clock STC) bedient den Video- und Audio-Encoder. Es wird jeweils ein Video- und ein Audio-Elementarstrom gebildet.
Die Elementarströme werden in Datenpakete mit maximal etwa 65 kbyte zerlegt, die den einzelnen Videoteilbildern oder kurzen Audioabschnitten zugeordnet sind. Aus den paketierten Elementarstromdaten (PES) wird ein Programmstrom (PS) gebildet, der nun Zeitmarken in der System Clock Reference (SCR) enthält, die den absoluten Zeitbezug für die komprimierten Video- und Audiodaten gewährleisten. Siehe dazu Bild 12.2.
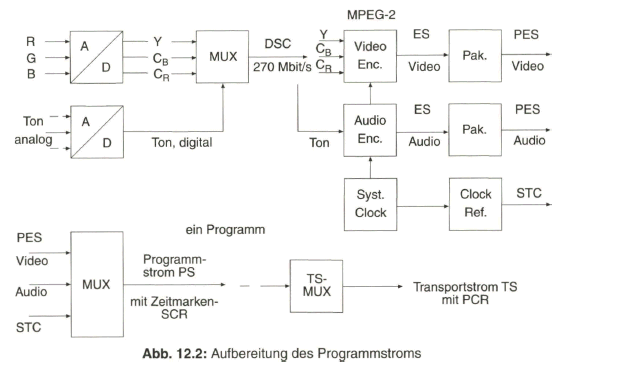
Die relativ langen Datenpakete sind nicht geeignet für die Übertragung in einem mit Störungen behafteten Kanal. Es wird deshalb im Transportstrom-Multiplexer der Programmstrom auf kurze Pakete mit einer festen Länge von 188 byte, davon 4 byte für den Header und 184 byte für die Nutzinformation, im Transportstrom (TS) aufgeteilt, der nun den Zeitbezug in der Program Clock Reference (PCR) enthält.
Die üblichen Fernsehverteilkanäle erlauben die Übertragung von gleichzeitig mehreren Programm-Transportströmen. Es werden deshalb in einem System-Multiplexer mehrere Programm-Transportströme zu einem Sende-Transportstrom zusammengefasst. Dies kann über statisches oder statistisches Multiplexen erfolgen. Für den terrestrischen Funkkanal werden bis zu vier Programme, beim Kabelkanal und beim Satellitenkanal bis zu zehn Programme in einem Multiplex zusammengefasst. Eine neue Aufbereitung der Program Clock Reference ist erforderlich, um selbst geringe zeitliche Verschiebungen beim Multiplex zu eliminieren.
Der Sende- Transportstrom mit einer Datenrate von etwa 13 Mbit/s beim terrestrischen Funkkanal bzw. etwa 38 Mbit/s beim Kabelkanal oder Satellitenkanal wird nun einem pseudo-zufälligen Umsortieren der Bits unterworfen, um ein gleichverteiltes Spektrum ohne Gleichanteil zu erhalten. Im Weiteren folgt ein verketteter Fehlerschutz, der in jedem Fall den äußeren Fehlerschutz (RS 204,188) und ein Byte-Interleaving enthält. Im Satellitenkanal und beim terrestrischen Funkkanal folgt noch der innere Fehlerschutz mit einem punktierten Faltungscode. Die zu übertragende Brutto-Datenrate wird so auf 55 Mbit/s im Satellitenkanal (R = 3/4) bzw. auf etwa 21,5 Mbit/s (8-MHz-Kanal, R = 2/3) oder 18,8 Mbit/s (7-MHz-Kanal, R = 3/4) im terrestrischen Funkkanal erhöht. Bild 12.3 gibt in einem vereinfachten Blockschaltbild die Übertragung des Sende-Transportstroms wieder.