
7. Datenreduktion beim digitalen Quellensignal
Das im Studio aufbereitete digitale Quellensignal weist eine Standard-Bitrate von 216 Mbit/s bzw. 270 Mbit/s für das 625-Zeilen-Videosignal oder, im Falle eines HDTV Signales, mindestens eine aktive Bitrate von etwa 664 Mbit/s auf. Zu der aktiven Videosignal-Bitrate kommen noch digitale Tonsignale und Synchronisation sowie Fehlerschutzdaten hinzu.
Die Übertragung solcher digitaler Quellensignale über herkömmliche terrestrische Rundfunk-TV-Kanäle mit 7 bzw. 8 MHz Bandbreite oder Satellitenkanäle mit Kanalbandbreiten von 26 bis 36 MHz ist mit den bisher angewandten Modulationsverfahren nicht möglich. Es wird somit notwendig, eine Reduktion der Datenraten beim digitalen Videosignal vorzunehmen.
7.1 Prinzipien der Datenreduktion
Eine Reduktion der Bitrate kann vorgenommen werden unter Ausnutzung der Redundanz und Irrelevanz im Bildsignal. Dazu ist es erforderlich, die redundante und irrelevante Information in dem Videosignal zu definieren und dem Datenstrom zu entnehmen.
Redundante Information verbirgt sich
— in den Austastlücken mit dem sich wiederholenden Synchronsignal und insbesondere darin, dass
— aufeinanderfolgende Bildpunkte und vor allem
— aufeinanderfolgende Teilbilder oft sehr ähnlich sind.
Darüber hinaus liegt Redundanz auch in der Tatsche, dass
— nicht alle Grau- und Farbabstufungen gleich häufig vorkommen.
Redundanzreduktion hat keinen Informationsverlust zur Folge. Man spricht in diesem Fall von verlustloser Codierung.
Irrelevanz im Bildsignal kann dadurch entfernt werden, dass
— das menschliche Auge gewisse Fehler im Bild, die z. B. durch Quantisierung hervorgerufen werden, nicht als störend wahrnimmt.
Eine Irrelevanzreduktion bedeutet einen Informationsverlust, entsprechend einer verlustbehafteten Codierung [105].
Als wesentliche „Werkzeuge" zur Redundanzreduktion dienen die Differenz-Pulscodemodulation (DPCM) und die Transformations-Codierung (TC), insbesondere die für Bildsignale optimale Discrete Cosine Transformation (DCT). Meistens kommt eine Kombination von DPCM und DCT im sogenannten Hybrid-DCT-Coder, in Verbindung mit einer Bewegungskompensation zur Anwendung.
Bei der Differenz-Pulscodemodulation liegt der Gedanke zugrunde, dass wegen der statistischen Abhängigkeit zwischen benachbarten Bildpunkten und einer verringerten Wahrnehmbarkeit von Fehlern an Helligkeits- oder Farbkanten eine hinreichende Vorhersage (Prädiktion) des Signalwertes eines Bildpunktes aus der vorangehend übertragenen Information von benachbarten Bildpunkten möglich ist. In einem Bildausschnitt mit konstanter Helligkeit stellt beispielsweise der dem zu codierenden Bildpunkt in der Zeile vorangehende Bildpunkt eine gute Vorhersage dar (eindimensionale Prädiktion). Berücksichtigt man auch noch einen oder mehrere benachbarte Bildpunkte in der vorangehenden Zeile desselben Halbbildes, so erhält man eine zweidimensionale Prädiktion (Innerbild- oder Intrafield-Prädiktion). In Bildbereichen ohne Bewegung erhält man die beste Vorhersage durch den Bildpunkt an der gleichen Stelle im vorangehenden Vollbild (Bild-zu-Bild- oder Interframe-Prädiktion).
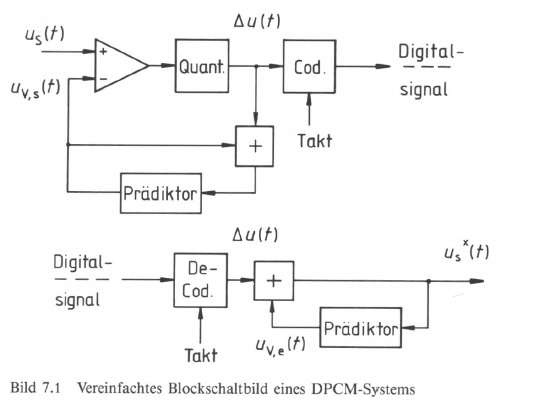
Bild 7.1 zeigt das Blockdiagramm eines DPCM-Systems. Der Prädiktionswert uV,S(t) wird vom tatsächlichen momentanen Signalwert uS(t) subtrahiert. Der Prädiktionsfehler Delta u(t) wird in wenigen Stufen quantisiert und durch Codewörter mit fester oder variabler Länge übertragen. Auf der Empfangsseite wird der Signalwert uS(t) durch Addition des Prädiktionsfehlers Delta u(t) zu einem empfangsseitigen Prädiktionswert uv,e (t) rekonstruiert. Der empfangsseitige Prädiktionswert soll möglichst genau dem sendeseitigen Prädiktionswert entsprechen, um einen größeren Fehler zu vermeiden. Man gewinnt deshalb sendeseitig den Vorhersagewert auf die gleiche Weise wie empfangsseitig, nämlich unter Einbeziehung der quantisierten Prädiktionswerte.
An Kanten auftretende größere Abweichungen des Prädiktionssignales können mit einer gröberen Abstufung quantisiert werden. Eine selbständige Anpassung der Quantisierungsstufenhöhe erfolgt bei der Adaptiven Differenz-Pulscodemodulation [77].
Weitergehende Vorschläge von BOSTELMANN und VAN BUUL bezüglich der Quantisierungskennlinie führen zu einer reduzierten Fehlerfortpflanzung. Diese wirkt sich bei der Differenz-Pulscodemodulation umso weiter aus, je feiner die Quantisierung des Prädiktionswertes ist. Andererseits bewirkt eine grobe Quantisierung mit raschem Fehlerabbau ein im Bild bemerkbares Quantisierungsrauschen [94, 106, 107, 108].
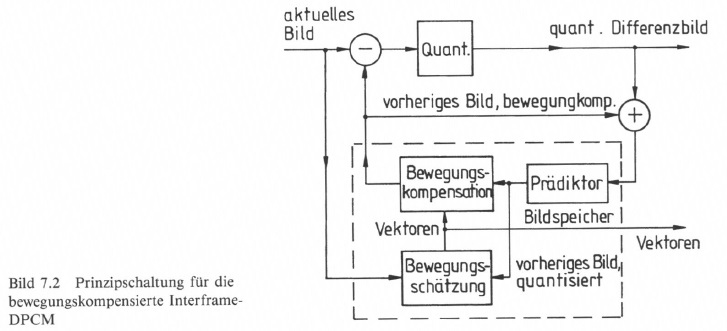
Allen Varianten der DPCM gemeinsam ist, dass nur noch die Differenz zwischen dem aktuellen Bildpunkt und einer möglichst guten Prädiktion übertragen wird. Die Prädiktion kann jedoch zu größeren Fehlern führen, wenn sich der Bildinhalt bei bewegten Vorlagen von Teilbild zu Teilbild ändert. Man führt deshalb eine Bewegungskompensation ein. Erforderlich ist dazu zunächst eine Bewegungsmessung oder Bewegungsschätzung durch Vergleich des rekonstruierten Bildes mit dem Originalbild. Selbstverständlich wird dieser Vergleich nur über kleine Bildpartien blockweise vorgenommen. Es werden dann Vektoren abgeleitet, die einerseits schon beim DPCM-Coder zur Bewegungskompensation dienen und andererseits zusammen mit dem Prädiktionswert zu dem DPCM-Decoder übertragen werden. Das Prinzip der bewegungskompensierten Interframe DPCM gibt Bild 7.2 wieder [105].
Bei der Transformationscodierung wird das digitale Videosignal einer linearen, umkehrbaren Transformation mit nachfolgender Quantisierung und Codierung unterzogen. Die Bildvorlage unterteilt man dazu in eine Anzahl von Blöcken mit M x N Bildpunkten (Pixel). Jeder Block wird dann durch eine gewichtete Summe von Basisbildern interpretiert, die codiert übertragen werden.
Die bei Videosignalen am häufigsten angewandte Transformationscodierung ist die Diskrete Kosinus-Transformation, Discrete Cosine Transformation (DCT). Diese wird im folgenden an einem Beispiel der zweidimensionalen DCT eines Blockes von Bildpunkten mit Quantisierung der Tansformations-Koeffizienten zur Irrelevanzreduktion erläutert.
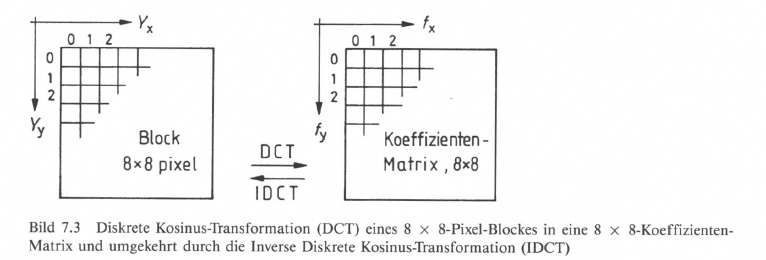
Ausgegangen wird von einem Block mit 8 x 8 Pixel, deren Helligkeitsverteilung Y(x, y) mit 8 bit/Pixel codiert vorliegt (Bild 7.3). Die Helligkeitsverteilung Y(x, y) wird durch eine gewichtete Überlagerung der DCT-Basisfunktionen angegeben, die wiederum die Spektralkoeffizientenf(x, y) repräsentieren, die in einer Koeffizientenmatrix angeordnet werden. Die Spektralkoeffizienten wiederum werden mit 12 bit/Koeffizient codiert. Der Vorgang ist reversibel und läuft auf der Decoderseite als Inverse Diskrete Kosinus-Transformation, Inverse Discrete Cosine Transformation (IDCT) ab [109, 112, 121].
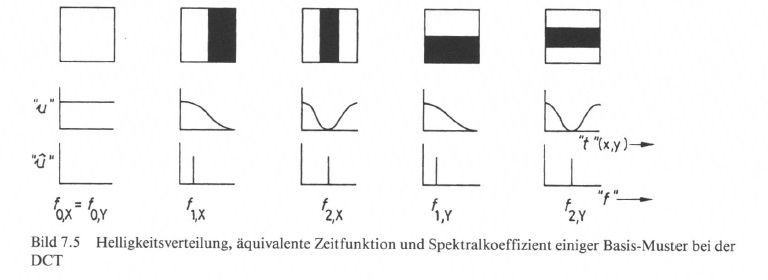
Es werden 8 x 8 DCT-Basisfunktionen zur Transformation der Helligkeitsverteilung eines Blockes verwendet. Diese sind ausschnittsweise als „Muster" in Bild 7.4 abgebildet, wobei jedes „Muster" auf den 8 x 8-Pixel-Block zu beziehen ist.

Diese Grundmuster werden nach Abtastung in x- und y-Richtung als Helligkeitsverlauf, entsprechend einem Spannungsverlauf u(t), bzw. als „Spektralkomponenten" mit Angabe der „Frequenz" fx,y und der zunächst vollen „Intensität" dargestellt (Bild 7.5). Beim Abtastvorgang ergibt sich ein kosinusförmiger Funktionsverlauf, worauf der Begriff „Kosinus-Transformation" zurückzuführen ist.
Die Koeffizientenmatrix setzt sich aus 8 x 8 = 64 Basisfunktionen zusammen, deren Ort in der Matrix mit 6 bit codiert wird. Jede Basisfunktion kann mit 64 Intensitätsstufen gewichtet werden, was zur Codierung nochmals 6 bit erfordert. Das ergibt zusammen 12 bit/Koeffizient. Für den gesamten Block ergibt sich eine Datenmenge von
64 Koeffizienten/Block x 12 bit/Koeffizient = 768 bit/Block.
Die DCT-Koeffizienten können als Spektralkomponenten der Blöcke interpretiert werden. In strukturlosen Bildbereichen liegt praktisch nur ein Gleichanteil (DC) vor, während bei feinen Bilddetails auch die hochfrequenten Spektralkomponenten zu berücksichtigen sind.
Im nächsten Schritt wird eine Quantisierung der DCT-Koeffizienten F(x,y) mit einer spektralen Gewichtung vorgenommen. Man benutzt dazu eine Quantisierungstabelle Q(x,y), die bei der Rücktransformation auch wieder berücksichtigt werden muss. Die qnaitsierten DCT-Koeffizienten werden noch einer Rundung unterzogen. Die Helligkeitswerte Y(x, y) aus dem 8 x 8-Pixel-Block, im Wertebereich von 0 bis 255 (8-bitCodierung), werden vor der Transformations-Codierung durch Subtraktion noch auf den Mittelwert (128) bezogen. Der eigentliche Helligkeitsmittelwert im Block wird als DC-Koeffizient F(x=y=0) ausgegeben.
Am folgenden Zahlenbeispiel sei der Ablauf der Transformations-Codierung erläutert [121].

Die quantisierten und gerundeten DCT-Koeffizienten werden dann nacheinander abgetastet und stehen somit als eine Folge von 64 Zahlenwerten an. Es wird eine Zick-Zack-Abtastung (angepasst auf Vollbild- oder Halbbildabtastung) (Bild 7.6) vorgenommen, die der spektralen Verteilung und der subjektiven Bedeutung der Koeffizienten angepasst ist. Damit bewirkt man eine weitere Datenreduktion, weil die abgetasteten Koeffizienten schon sehr bald zu Null werden. Der Gleichspannungswert (Helligkeitsmittelwert) wird davon unabhängig selbständig übertragen.
In der Folge von Zahlenwerten, am Beispiel von Bild 7.6, treten immer wieder längere Nullfolgen auf, die abgekürzt durch ihren Faktor angegeben werden, man spricht in diesem Fall von einer Entropie-Codierung [105]:
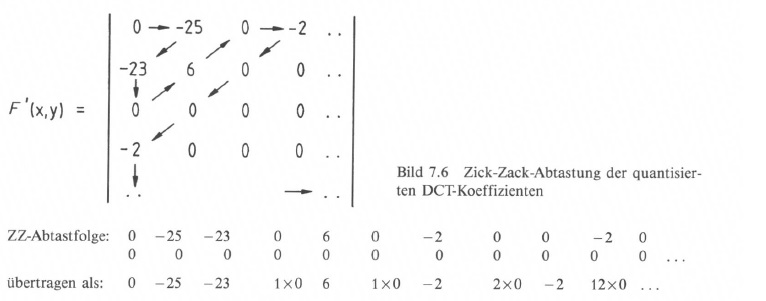
Aus einer Code-Tabelle, die z. B. mit dem Algorithmus von HUFFMANN entworfen wird [105], entnimmt man verkürzte Codeworte für die Kombination aus bestimmten Nullfolgen („Run") mit nachfolgendem Zahlenwert („Level") und für die entsprechend der Statistik verteilten Amplitudenwerte.
Es zeigt sich nämlich, daß hohe Amplituden seltener auftreten als niedrige Amplituden. Den selten auftretenden hohen Amplitudenwerten werden dann längere Codeworte und den häufig auftretenden niedrigen Amplitudenwerten kürzere Codeworte zugeordnet. Das Ergebnis ist eine Lauflängencodierung oder Variable Length Coding (VLC), die im Mittel zu einer niedrigeren Datenrate führt. Eine dadurch bedingte variable Datenrate muß im System in einem nachfolgenden Pufferspeicher ausgeglichen werden.
Das Ergebnis der spatialen Codierung eines Blockes mit DCT, VLC und Run-Level-VLC ergibt dann insgesamt, daß für einen Block mit ursprünglich
8 bit/Pixel x 64 Pixel/Block = 512 bit/Block
nun nur noch etwa 40 bit/Block benötigt werden, was einer Datenkompression mit etwa dem Faktor 12 entspricht.
7.2 Videosignalcodierung nach dem MPEG-2-Standard
Eine internationale Standardisierung der Codier-Algorithmen wurde in den letzten Jahren ausgearbeitet durch die Moving Pictures Expert Group (MPEG) als einer Arbeitsgruppe (Working Group, WG) des Joint Technical Committees (JTC) der International Standards Organization (ISO) sowie der International Electrotechnical Commission (IEC) und als Ergebnis festgehalten in dem
MPEG-1-Standard bzw. MPEG-2-Standard.
Die Standardisierung bezieht sich auf die „Werkzeuge" zur Codierung eines Videosignales und auch des begleitenden Audiosignales und vor allem auf die Multiplex-Struktur des Datenstromes [109, 110, 111, 112, 113, 114, 115, 116, 117, 118].
Der MPEG-1-Standard wurde im Wesentlichen definiert für die Datenreduktion zur Speicherung von digitalen Bild- und Tondaten aus Datenbanken und Multimedia-Systemen. Die Datenrate ist auf etwa 1,5 Mbit/s beschränkt. Der MPEG-1-Standard basiert auf einer Vollbild-Verarbeitung und lässt drei Tonqualitätsstufen für Mono- und StereoTon zu.
Der MPEG-2-Standard baut auf dem MPEG-I -Standard auf, ist aber für ein wesentlich breiteres Anwendungsgebiet vorgesehen. So fallen darunter Standard-TV-Signale mit reduzierten Datenraten von etwa 3 bis 15 Mbit/s und HDTV-Signale mit Datenraten von etwa 16 bis 40 Mbit/s. Der MPEG-2-Standard verarbeitet Signale sowohl im Vollbildals auch im Halbbild-Format. Die Audio-Codierung wurde auf Mehrkanal-Ton bis zu 5 Kanälen erweitert.
Der MPEG-Datenstrom ist durch zwei Schichten gekennzeichnet:
Die Systemschicht enthält den Zeitablauf und andere Informationen, die notwendig sind, um den Audio- und Video-Datenstrom zu demultiplexen und Ton und Bild während der Wiedergabe zu synchronisieren.
Die Kompressionsschicht enthält den komprimierten Audio- und Video-Datenstrom.
Die Systemschicht kann hier nicht ausführlich beschrieben werden. Neben den zusammenfassenden Veröffentlichungen, auf die oben bereits hingewiesen wurde, finden sich Details zur Multiplex-Spezifikation besonders in [117].
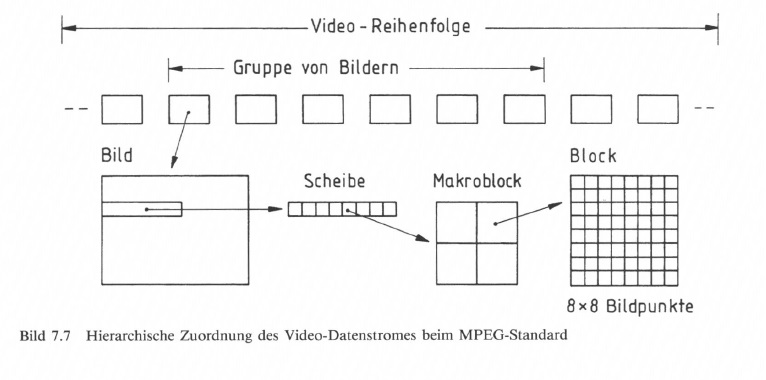
Der MPEG-Standard definiert eine Hierarchie des Video-Datenstromes nach
- Video-Reihenfolge (Video sequence)
- Gruppe von Bildern (group of pictures)
- Bild (picture)
- Scheibe (slice)
- Makroblock (macroblock)
- Block (block) mit 8 mal 8 Bildpunkten (pixels).
Die Zuordnung ist aus Bild 7.7 zu ersehen.
Bei der Videosignal-Codierung kommt die Hybride Diskrete Kosinus-Transformation zur Anwendung. Das Verfahren besteht hauptsächlich aus einer bewegungskompensierten DPCM. Die bewegungskompensierte Differenz wird dann einer DCT unterzogen [105]. Bei der Prädiktion muss unterschieden werden, ob diese für Vollbilder oder für Halbbilder gilt. Dazu werden
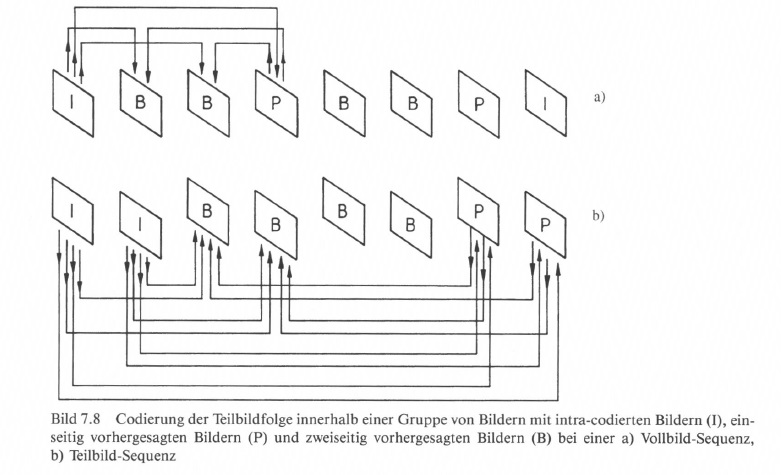
- intra-codierte Bilder (I-Pictures), die ganz ohne Prädiktion im Vollbild oder im Halbbild codiert werden,
- einseitig vorhergesagte Bilder (P-Pictures), die über Bezug auf ein vorangehendes intra-codiertes Bild, mit Bewegungskompensation, codiert werden, und
- zweiseitig (bidirektional) vorhergesagte Bilder (B-Pictures), die über Bezug auf ein vorangehendes und ein folgendes Bild als Referenz gewonnen werden, definiert.
Für die zweiseitige Prädiktion ist eine größere Anzahl von Bildspeichern notwendig, weil das nachfolgende Bild ja für die Codierung vorgezogen werden muss.
In gewissen Zeitabständen, etwa alle 0,5 s, muss ein I-Bild übertragen werden, damit ein „Neustart" des Decodiervorganges bei Einschalten des Decoders bzw. bei Übertragungsstörungen möglich ist. Zwischen den I-Bildern befinden sich nach einer definierten Reihenfolge abwechselnd P- und B-Bilder. Siehe dazu Bild 7.8.
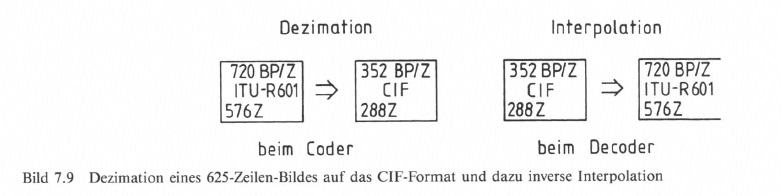
Um die Korrelationen im Bild zur Datenreduktion auszunutzen, wird das Bild unterteilt in Scheiben, Makroblöcke und Blöcke. Dies geschieht im „vorverarbeiteten" Bild, wo man, z. B. im MPEG-I -Standard beim 625-Zeilen-Bild aus dem digitalen Studiostandard nach ITU-R (CCIR) 601 in einem ersten Schritt auf das CIF-(SIF)-Format (Common Interchange bzw. Standard Interchange) als Codierungsformat geht. Beim Decoder wird durch Interpolation der Vorgang rückgängig gemacht (Bild 7.9).
Schon die MPEG-1-Videocodierung deckt einen weiten Bereich der Codierungsparameter ab, wie z. B. Bildgröße und -auflösung, Bildfrequenz und Datenrate. Dazu wurde ein sogenannter Constrained Systems Parameter Stream (CSPS) definiert mit u. a. den in Tabelle 7.1 angegebenen Parametern [113].

Die Begrenzung der Anzahl von Makroblöcken auf 396 bei 25 Vollbildern pro Sekunde läßt allerdings nicht die Ausnutzung der vollen Bildauflösung von 768 x 576 Pixel zu. Ausgehend von 704 Bildpunkten pro aktive Zeile (beim Dl-MAZ-Format) wird um den Faktor 2 reduziert auf das CIF-Format mit 352 Pixel horizontal und 288 Pixel vertikal, womit, bei 16 x 16 Bildpunkten pro Makroblock, die maximale Anzahl von 352/16 x 288/16 — 396 Makroblöcke im Codier-Format (CIF) eingehalten wird.
Der MPEG-2-Standard lässt eine höhere Auflösung, bis HDTV mit 1920 Pixel horizontal und 1152 Pixel vertikal, bei verschiedenen Qualitätsstufen („Levels") zu, näheres dazu im Abschnitt 7.3.
Die Entscheidung, ob eine Prädiktion und, ob diese im Vollbild oder im Halbbild erfolgen soll, wird makroblockweise getroffen. Dabei darf in I-Bildern keine Prädiktion stattfinden, in P-Bildern darf eine Prädiktion aus vorangehenden Bildern erfolgen oder der Makroblock wird ohne Prädiktion codiert. In B-Bildern kann die Prädiktion aus vorangehenden oder nachfolgenden Bildern oder durch Mittelwertbildung aus beiden vorgenommen werden oder es erfolgt keine Prädiktion im Makroblock. Die Auswahl bleibt dem Coder überlassen [110].
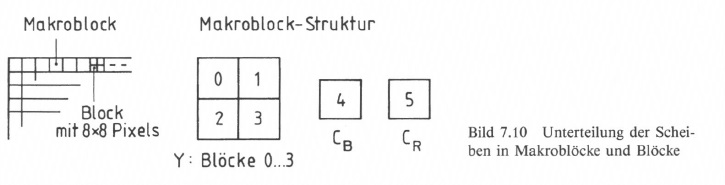
Die Bilder (Pictures) werden in Scheiben (Slices) unterteilt, die beliebige Länge zwischen einem Makroblock und maximale Bildbreite aufweisen können. Makroblöcke wiederum setzen sich bei der Codierung von Bildsignalen in dem z. B. für MP@ML (s. Tabelle 7.2) geforderten 4:2:0-Format jeweils aus vier Blöcken mit dem Leuchtdichtesignal Y (Blöcke 0 bis 3) und je einem Block für jedes Farbdifferenzsignal CB und CR (Blöcke 4 und 5) zusammen (Bild 7.10). Beim 4:2 : 0-Abtastformat werden gegenüber den Festlegungen für den 4:2:2-Standard bei CCIR 601 (s. Abschn. 5.2) Chrominanzsignale CB und CR nur aus jeweils zwei aufeinanderfolgend zusammengefassten Zeilen gewonnen. Die Makroblöcke sind für die Ausnutzung der zeitlichen Korrelation (DPCM mit Bewegungskompensation) geeignet. In den Blöcken mit je 8 x 8 Bildpunkten wird die räumliche Korrelation zur Datenreduktion mit der DCT ausgenutzt.
Die zeitliche Verarbeitung der Blöcke und Makroblöcke erfolgt über die Prädiktion von Teilbildern. Es werden nur in gewissen Abständen die Originalbilder (I-Bilder) übertragen und dann im wesentlichen nur Differenzbilder als P-Bilder oder B-Bilder. Zur Codierung der Differenzbilder wird wesentlich weniger Datenrate benötigt als für die Originalbilder.
Bild 7.11 gibt nur das Prinzipschaltbild eines MPEG-2-Video-Coders wieder. In einer Eingangsstufe erfolgt zunächst eine Filterung und Dezimation auf das Codierformat. Die Verarbeitung von Leuchtdichtesignal und den beiden Farbdifferenzsignalen wird parallel vorgenommen, wobei die Bewegungskompensation im Wesentlichen nur im Leuchtdichtekanal abläuft. Die Farbdifferenzsignale werden in der Auflösung stärker dezimiert als das Leuchtdichtesignal. Die nachfolgende Blocksortierung ist notwendig, weil z. B. erst acht Zeilen ablaufen müssen, um einen Block bilden zu können. In die zeitliche Vorhersageschleife wird als Referenz das Eingangsbild zur Ableitung der Bewegungsvektoren eingebracht. Das Differenzbild wird einer diskreten Kosinus-Transformation mit nachfolgender Quantisierung der DCT-Koeffizienten unterzogen. Nach ZickZack-Abtastung der Koeffizienten und deren Entropie-Codierung werden die Daten über einen Multiplexer in einen Daten-Puffer eingelesen.
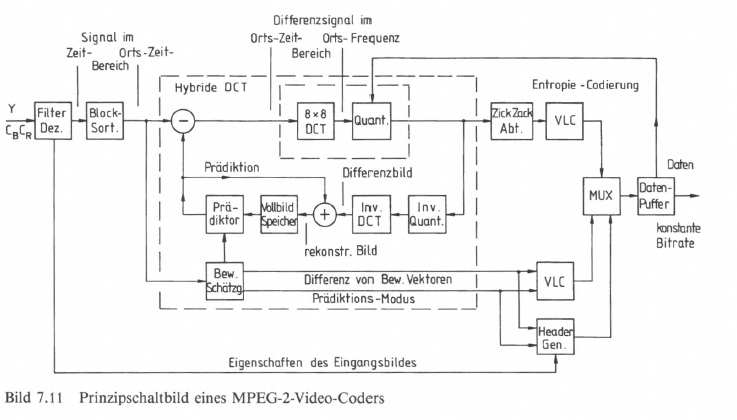
Abhängig von dessen Inhalt wird die Quantisierung der DCT-Koeffzienten beeinflusst. So wird gewährleistet, dass nach dem Daten-Puffer eine konstante Bitrate eingehalten wird. Aus der Bewegungskompensation werden die Bewegungsvektoren bzw. deren Differenz nach Lauflängen Codierung über den Multiplexer in den Ausgangsdatenstrom eingespeist, genauso wie die Information über die Eigenschaften des Eingangsbildes und den jeweiligen Prädiktionsmodus. Das Ausgangsdatensignal ist paketweise zusammengefasst und enthält jeweils im Paket-Kopf (Header) die Betriebsinformation.
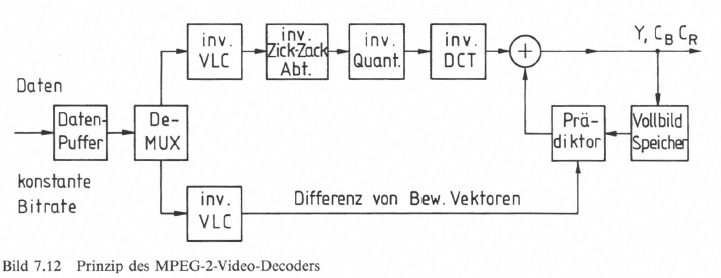
Im MPEG-2-Video-Decoder (Bild 7.12) erfolgt eine Abarbeitung der übertragenen Daten. Nach Auswertung des Paket-Kopfes werden die Daten in einem Daten-Puffer aufgefangen und von dort über den Demultiplexer verteilt. Die Vorgänge aus dem Coder laufen nun invers ab. Das rekonstruierte Differenzbild wird dann mit dem Prädiktionsbild zusammengefasst und nach entsprechender Signal-Nachverarbeitung in Form der Komponentensignale ausgegeben.
7.3 Qualitätsstufen für digitale Fernsehsignale
Der MPEG-2-Standard bietet die Möglichkeit der hierarchischen Codierung. Sie basiert auf räumlicher und zeitlicher Filterung (Spatial bzw. Temporal Scalability) und auf Techniken der Koeffizientenaufspaltung (SNR Scalability). Es lassen sich daraus verschiedenene Qualitätsstufen ableiten, die vom Studio dem Fernsehteilnehmer angeboten werden oder die eine den Übertragungsbedingungen angepaßte Bildwiedergabe ermögliChen. So kann z. B. bei Absinken des Signal/Rauschabstandes im Übertragungskanal beim Empfänger auf eine niedrigere Qualitätsstufe übergegangen werden, wo sich die Störungen nicht mehr so stark bemerkbar machen. Man spricht dann von Graceful Degradation.
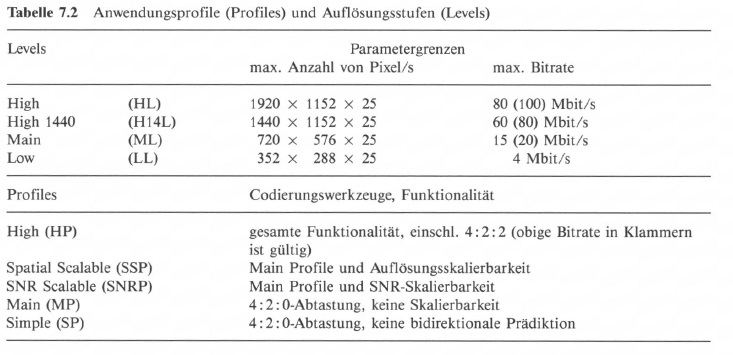
Der MPEG-2-Standard ist im Prinzip ein „generisches" Verfahren, das nur die Codiersynthax und damit hauptsächlich den Decodierprozeß beschreibt. Es werden aber Anwendungsprofile (Profiles) und Auflösungsstufen (Levels) definiert, deren Funktionieren auch nachgewiesen ist, siehe dazu Tabelle 7.2.
Bisher definiert wurden folgende Kombinationen von „Levels" und „Profiles":

Die „Profile-" und „Level- "Zuordnung wird durch Identifikationsbits im Datenstrom übertragen. Der Decoder kann damit erkennen, ob er den Videodatenstrom decodieren kann. Dabei gilt, dass ein Decoder immer auch die unter seinem „Profile" oder „Level" liegenden Qualitätsstufen decodieren kann, z. B. ein (MP & ML)-Decoder die (MP & LL)- bzw. (SP & ML)-Kombination [113, 114].
Über die hierarchische Codierung ist es z. B. möglich, aus einem von einer HDTV-Quelle kommenden Datenstrom durch entsprechende Aufbereitung Teil-Datenströme zu übertragen, die je nach verwendetem Decoder zu einer Wiedergabequalität zwischen „high quality HDTV" und „Iow quality SDTV" führen. in Bild 7.13 erfolgt die Aufbereitung des Datensignales in dem skalierbaren Coder, wo einerseits durch
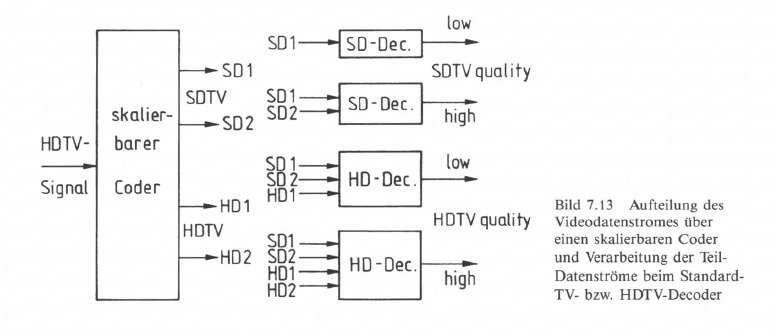 spatiale Skalierung aus dem HDTV-Signal ein SDTV-(SDI +SD2)- und ein HDTV(HDI + HD2)-Datenstrom und durch
spatiale Skalierung aus dem HDTV-Signal ein SDTV-(SDI +SD2)- und ein HDTV(HDI + HD2)-Datenstrom und durch- SNR-Skalierung aus dem Eingangssignal zwei Datenströme abgeleitet werden, die Bilder gleicher örtlicher Auflösung aber unterschiedlicher Qualität (Quantisierung) entsprechen.
Von der innerhalb der European Launching Group für Digital Television Broadcasting (ELG) eingesetzten Working Group für Digital Television Broadcasting (WGDTVB), neuerdings Technik-Modul des DVB-Projektes (TM-DBV), wurden verschiedene Qualitätsebenen für zukünftige Fernsehdienste definiert, mit:
- HDTV-Studioqua1ität
- CCIR-601-Qualität (dig. Komponentenstudio)
- PAL-Qualität (heutiger Maßstab)
- VHS-Qualität
mit entsprechender Anzahl und Qualität von Tonkanälen, bzw. unter Verwendung von international eingeführten Begriffen
- HDTV (High Definition Television), entspr. HD-1440-Ref. Standard
- EDTV (Enhanced Definition Television), entspr. CCIR-601-Standard
- SDTV (Standard Definition Television), entspr. PAL-Standard
- LDTV (Limited Definition Television), entspr. MPEG-1-Standard
(MPEG-1-Standard mit einer Auflösung von etwa ein Viertel von CCIR 601).
Charakteristische Werte für diese Qualitätsstufen siehe Tabelle 7.3.

Bei der HDTV-Qualitätsstufe liegt selbstverständlich ein 16: 9-Bildformat vor, bei der EDTV-Qualitätsstufe ist ein 4:3- oder 16:9-Bildformat möglich.
Ergänzende Literatur zu dem Abschnitt 7.3 und zum Kapitel 8: [122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132 und 133].