
6. Datenreduktion beim digitalen Audiosignal
Die Aufbereitung des digitalen Audio-Quellensignals erfolgt nach dem Verfahren der Pulscodemodulation, wie in Abschnitt 4.1.1 beschrieben. Der Signalfrequenzbereich reicht von 20 Hz (30 Hz) bis 20 kHz (15 kHz). Standardisierte Werte für die Abtastfrequenz sind 32 kHz (>2-15 kHz), 44,1 kHz (Abtastfrequenz bei der MCD) und 48 kHz (Studio). Mit einer Abtastfrequenz von 48 kHz und einer Codierung mit üblicherweise 16 bit pro Codewort (im Studio auch mit 20 bit) beträgt die Bitrate pro Audiokanal
![]()
r ein Stereosignal beläuft sich die Bitrate dann auf 1,536 Mbit/s.
Obwohl die Datenrate des digitalen Audiosignals im Vergleich zum Videosignal wesentlich niedriger liegt, bietet sich auch hier eine Datenkompression über Verfahren der Irrelevanzreduktion und Redundanzreduktion an. Die Arbeiten an Verfahren zur Datenreduktion beim digitalen Audiosignal wurden in den achtziger Jahren entscheidend beeinflusst durch die beabsichtigte Einführung der digitalen Tonsignalübertragung im Rundfunkbereich mit dem Digital Audio Broadcasting (DAB). Es wurden dafür Datenreduktionsverfahren untersucht, die vornehmlich die Unzulänglichkeiten des menschlichen Gehörs ausnutzen.
Am Institut für Rundfunktechnik (IRT) in München wurde 1988 das sog. MAS-CAM-Verfahren vorgestellt, aus dem im Folgenden über die Zusammenarbeit mit Philips und Matsushita das MUSICAM-Verfahren (Masking Pattern Universal Subband Integrated Coding And Multiplexing) entstand. Basis dieses Verfahrens ist die Teilbandcodierung mit Herausnahme von nicht wahrnehmbarer Information. Es wird so eine Irrelevanzreduktion vorgenommen.
Parallel zu diesem Teilbandcodierungsverfahren wurde von der Fraunhofer-Gesellschaft und Thomson das ASPEC-Verfahren (Adaptive Spectral Perceptual Entropy Coding) entwickelt, das nach dem Prinzip der Transformationscodierung arbeitet. Das Audiosignal wird mittels DCT vom Zeitbereich in den Frequenzbereich transformiert, um in dieser Ebene irrelevante Signalanteile zu entfernen. Auf die zu übertragenden Codeworte und Steuerinformationen wird im Weiteren noch zusätzlich eine Redundanzreduktion eingebracht.
6.1 Psychoakustisches Modell des menschlichen Ohres
Die weitgreifende Irrelevanzreduktion bei den Tonsignalen basiert auf einem psychoakustischem Modell des menschlichen Ohres, das im Wesentlichen auf Untersuchungen von Prof. Zwicker an der TU München zurückgeht. Seit langer Zeit war bereits bekannt, dass die Empfindlichkeit des menschlichen Ohres für die Hörbarkeit von Tönen stark frequenzabhängig ist. Die höchste Empfindlichkeit weist das Ohr im Frequenzbereich von etwa 1 kHz bis 5 kHz auf, sehr tiefe Töne unter 30 Hz und sehr hohe Töne oberhalb 15 kHz werden praktisch nicht mehr wahrgenommen. Auch eine gewisse Mindestlautstärke ist Voraussetzung für die Wahrnehmbarkeit von akustischen Reizen.
Bild 6.1 gibt dazu die Ohrempfindlichkeitskurve für die Ruhehörschwelle wieder, womit der Schalldruckpegel L als physikalisches Maß für die Lautstärke angegeben wird, der notwendig ist für die Wahrnehmbarkeit eines Tones abhängig von seiner Frequenz. Zu höherer Lautstärke hin verschiebt sich die Kurve im Wesentlichen parallel zu höheren Werten des Schalldruckpegels.
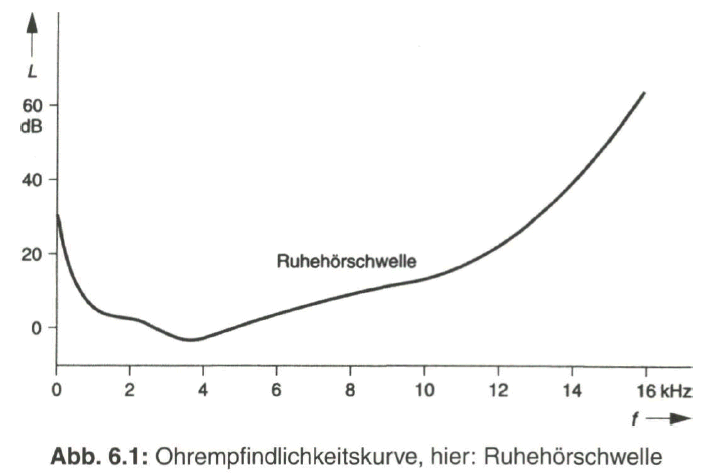
Die Untersuchungen am menschlichen Hörorgan haben zu der Entdeckung von Maskierungseffekten geführt. Beim Auftreten eines starken Tonsignals werden weitere frequenzbenachbarte und über der Ruhehörschwelle liegende Töne durch die Maskierung im Frequenzbereich nicht mehr wahrgenommen. Im Gegensatz zur statischen Ruhehörschwelle tritt nun eine dynamische Mithörschwelle oder Maskierungsschwelle (Masking Threshold) auf. Deren Verlauf hängt von der Frequenz des maskierenden Tones ab. Der beeinflusste Frequenzbereich ist umso breiter je höher die Frequenz des dominierenden Signals ist (Bild 6.2). Die überdeckten und vom Ohr nicht mehr wahrgenommenen Tonsignale müssen nicht übertragen werden. Es erschließt sich damit auch die Möglichkeit, sowohl den Bereich unterhalb der statischen Ruhehörschwelle als auch den Bereich unterhalb der sich ständig ändernden dynamischen Mithörschwelle für das Quantisierungsgeräusch auszunutzen.
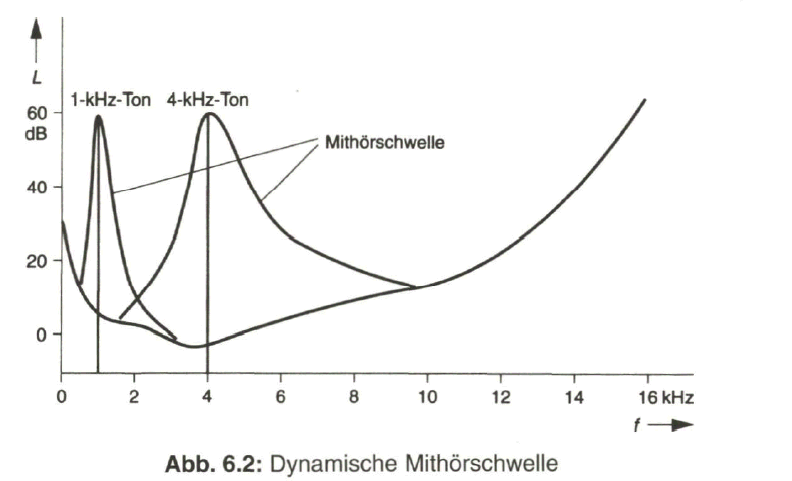
Ein weiterer Maskierungseffekt tritt im Zeitbereich auf. Beim Auftreten eines starken, impulsartigen Signals werden Töne unter einer bestimmten Schwelle sowohl vor, aber insbesondere nach dem maskierenden Signal überdeckt. Bei den bisher technisch realisierten Audio-Datenkompressionsverfahren wird dieser Effekt jedoch noch nicht berücksichtigt.
6.2 Prinzip der Teilbandcodierung
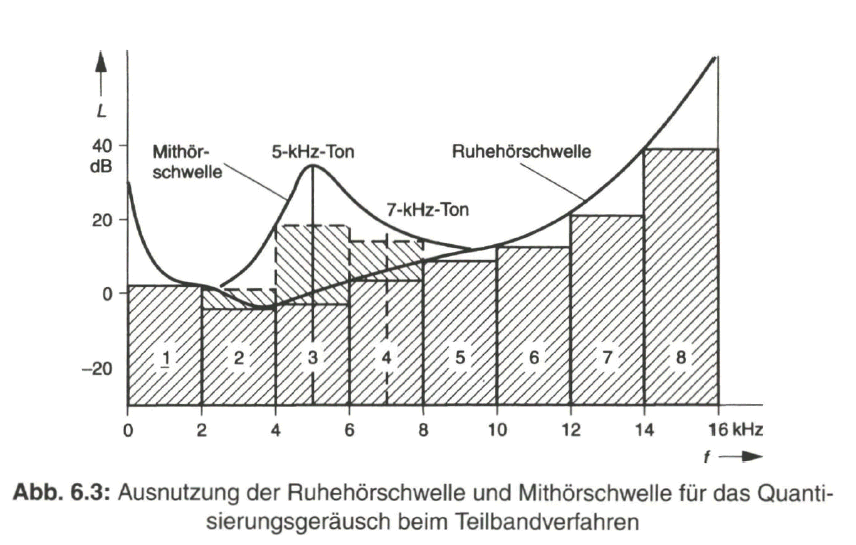
Ähnlich wie bereits bei der Wahrnehmung von Farbreizen durch das menschliche Auge im Abschnitt 2.3 beschrieben, lässt sich auch beim menschlichen Hörorgan über eine eingeschränkte Wahrnehmbarkeit von Schallereignissen eine Irrelevanzreduktion einbringen. Auf Grund der Frequenzabhängigkeit des menschlichen Hörorgans bietet es sich an, zur Verarbeitung der Tonsignale den gesamten Audiofrequenzbereich von 20 Hz bis 20 kHz in Teilbänder mit fester Bandbreite zu separieren. Bei dem MUSICAM-Verfahren, das die Teilbandcodierung mit einbezieht, sind es 32 Teilbänder mit je 750 Hz Bandbreite. Diese grobe Aufteilung des Audio-Frequenzbereiches in die Teilbänder wird über eine so genannte „Filterbank“ vorgenommen, mit digitaler Signalverarbeitung des PCM-Eingangssignals. In Bild 6.3 ist diese Unterteilung schematisch durch 8 Teilbänder (1 ... 8) angedeutet.
Die Codierung des Audiosignals in den Teilbändern erfolgt so, dass das damit verbundene Quantisierungsgeräusch den Pegel bis zur Ruhehörschwelle ausnutzt. Bei tiefen und bei höheren Frequenzen kann mit einer gröberen Quantisierung gearbeitet werden und es braucht nicht der gesamte Frequenzbereich mit der vollen Codewortlänge von z.B. 16 bit aufbereitet werden. Wird ein Signal (7 kHz-Ton in Bild 6.3) in einem Teilband durch Signale in benachbarten Teilbändern (5 kHz-Ton) vollkommen maskiert, so kann das entsprechende Teilband (4) bei der Übertragung wegfallen. Damit erschließt sich aber auch die Möglichkeit, den Bereich unterhalb der Mithörschwelle (Bild 6.3, Teilband 3) zusätzlich für das Quantisierungsgeräusch auszunutzen.
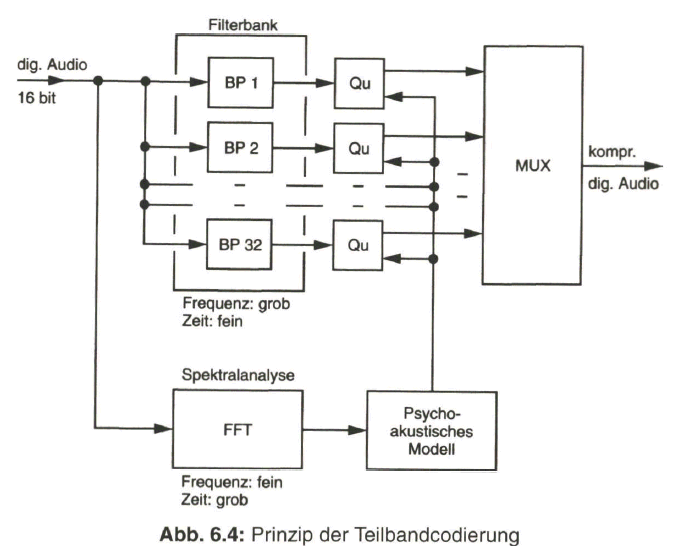
Neben der groben Frequenzbandunterteilung mit Bandpässen (BP) und nachfolgender, der Ruhehörschwelle angepasster Quantisierung, wird eine spektrale Analyse des anliegenden Signalgemisches mittels schneller FOURIER-Transformation (FFT) über einen Block von Abtastwerten vorgenommen. Mit einer zeitlichen Auflösung von z.B. 24 ms, über die das Signal mit 1024 Abtastwerten als unverändert betrachtet wird, erfolgt eine Transformation in den Frequenzbereich mit einer feinen spektralen Auflösung. Daraus wird unter Einbeziehung des psychoakustischen Modells des menschlichen Hörorgans über die Mithörschwelle eine dynamische Steuerung der Quantisierung vorgenommen. Bild 6.4 zeigt schematisch die Teilbandcodierung mit variabler Quantisierung in den Teilbändern.
Das psychoakustische Modell des menschlichen Ohres ist als zentrale Funktionseinheit im MUSICAM-Encoderenthalten. Neben der bereits beschriebenen spektralen Analyse, mit grober Unterteilung über die „Filterbank“ und feiner Analyse mittels FFT, wird auch im Spannungs- bzw. Pegelbereich eine Unterteilung vorgenommen. Der gesamte Dynamikbereich von 128 dB wird in 64 Stufen von je 2 dB aufgeteilt, markiert durch einen Skalenfaktor in 6-bit-Codeworten.
Der Skalenfaktor wird jeweils aus einem Block von 12 Abtastwerten ermittelt, indem man aus dem höchsten Abtastwert einen Skalierungsfaktor bestimmt, mit dem diese Signalproben bewertet übertragen werden [2, 8, 24, 27]. Mit zusätzlichen Maßnahmen, wie Lauflängencodierung (RLC) sowie variabler Längen-Codierung (VLC), erfolgt eine Redundanzreduktion bei den gewonnenen Daten. Bild 6.5 zeigt nun das Funktionsschaltbild des MUSICAM-Encoders. Die erreichbare Datenreduktion erfolgt je nach der Komplexität des Encoders ausgedrückt durch die Layers (siehe Abschnitt 6.3) bis zu einem Faktor zehn. Den Layers I und II liegt die Teilbandcodierung zu Grunde.
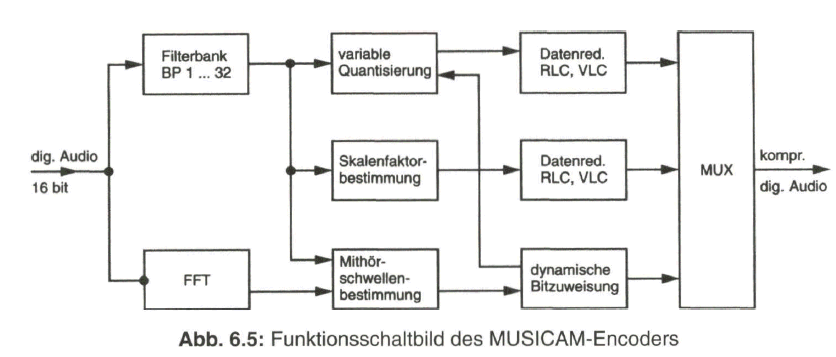
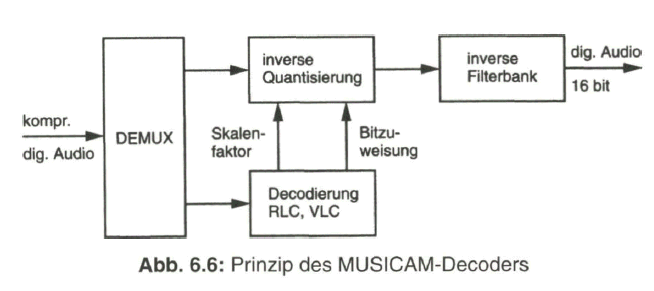
Das psychoakustische Modell ist nur beim Encoder erforderlich. Beim Decoder werden nach Demultiplexen des Datenstroms und Decodieren der Steuerungsanweisungen die übertragenen Teilbandsignale in einer inversen Filterbank wieder zum Summensignal zusammengesetzt. Siehe dazu das vereinfachte Funktionsschaltbild in Bild 6.6
Neben der Teilbandcodierung gibt es die Transformationscodierung, eingebracht in Layer III der MPEG-Zuordnung. Bei der Transformationscodierung kommt an Stelle der Filterbank eine modifizierte Diskrete Cosinus-Transformation (MDCT) zum Einsatz. Diese ermöglicht eine feinere Unterteilung des Audio-Frequenzbereiches und damit eine höhere Irrelevanzreduktion.
6.3 Layers bei den Codierverfahren
Bei der Audiocodierung werden verschiedene Layers, je nach dem Grad der Datenreduktion und dem notwendigen technischen Aufwand, unterschieden. Diese Festlegung ist eigentlich in dem MPEG-Standard enthalten, der im folgenden Abschnitt 7 erläutert wird. Ziel ist in jedem Fall eine hohe Qualität des wiedergegebenen Audiosignals.
Layer I, auch als „Pre-MUSICAM“ bezeichnet, basiert auf dem PASC-Algorithmus (Precision Adaptive Subband Coding), der von Philips für die digitale Audio-Cassette DCC entwickelt wurde. Die Ausgangsbitrate kann mit 14 Werten im Bereich von 32 bis 442 kbit/s pro Audiokanal liegen. Subjektive HiFi-Qualität erfordert 192 kbit/s pro Kanal und damit 384 kbit/s für ein codiertes Stereo-Audiosignal. Der Vorteil des Verfahrens, das mit dem bereits in Abschnitt 6.1 beschriebenen psychoakustischen Modell und fester Codierung der Teilband-Koeffizienten arbeitet, ist die relative Einfachheit von Encoder und Decoder.
Layer II, basiert auf dem MUSICAM-Verfahren, das wie schon erwähnt, für das europäische Digital Audio Broadcasting DAB entwickelt wurde. Für eine vergleichbare Audio-Qualität kommt Layer II mit nur etwa 30 ... 50 % der übertragenen Bitrate von Layer I aus. Die Bitrate kann Werte zwischen 32 ... 192 kbit/s pro Audiokanal annehmen. Subjektive HiFi-Qualität wird erreicht mit 96 kbit/s bzw. 192 kbit/s für das Stereosignal. Die Komplexität von Encoder und Decoder ist nur unwesentlich höher als bei Layer I. Es wird das gleiche psychoakustische Modell mit variabler Codewortlänge in den Teilbändern verwendet.
Layer III, arbeitet mit einem gegenüber Layer I und II geänderten psychoakustischen Modell und einer auf DCT (Diskreter Cosinus-Transformation) basierten Signalanalyse an Stelle der Teilbandcodierung. Die Bitrate kann im Vergleich zu Layer II nochmals um den Faktor 2 abgesenkt werden, aber es steigt auch die Komplexität von Encoder und Decoder. Dieses Verfahren wird auch bei Dolby Digital (AC-3) für den Begleitton beim Kinofilm, bei der DVD und verschiedentlich auch schon beim Digitalen Fernsehen angewendet. AC-3 besagt „Audio Coding Layer 3“.
Layer III ist vor allem für niedrige Bitraten, z. B. für ISDN-Übertragung oder Audio- Files nach dem Internet-Standard MP3, ausgelegt. Der Begriff „MP3“ steht für „MPEG-1 Layer III“ als Datenformat. Ein verbesserter Nachfolger dieses Standards wurde vom FRAUNHOFER-Institut für Integrierte Schaltungen entwickelt und mit AAC (Advanced Audio Coding) benannt.
6.4 Mehrkanal-Codierung
Bei der Verarbeitung von Tonsignalen unterscheidet man zwischen Einzelkanal-Codierung mit
• Single Channel Coding (Monosignale),
• Dual Channel Coding (zweisprachige Monosignale),
• Stereo Coding (Rechts- und Unks-Signale) und
• Joint Stereo Coding,
bei dem die Redundanz zwischen Links- und Rechts-Kanal ausgenutzt wird. Aufgrund der Tatsache, dass die räumliche Ortung bei höheren Frequenzen mehr auf dem Lautstärkeverhältnis beruht als auf der Phasenbeziehung zwischen Links- und Rechts-Signal, genügt es, bei höheren Frequenzen praktisch nur ein Mono-Signal zu übertragen (Irrelevanzreduktion)
und
• Multi Channel Audio Coding (Mehrkanalton) bei Layer II mc und Layer III me, mit fünf bzw. sechs Tonkanälen für Surround Sound. Dabei kann aus der Korrelation von nicht für den räumlichen Höreindruck notwendigen Signalanteilen aus den einzelnen Kanälen eine Irrelevanzreduktion abgeleitet werden, wie dies bei Dolby Digital 5.1 Surround angewendet wird.
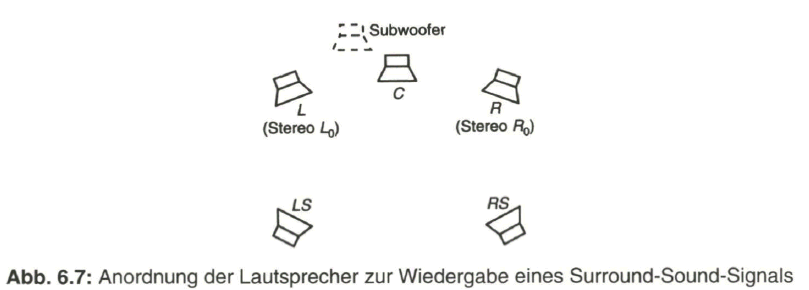
Die Anordnung der Lautsprecher zur Wiedergabe eines Stereosignals bzw. eines Surround-Sound-Signals gibt Bild 6.7 wieder. Im Gegensatz zu Dolby Surround (auch bekannt als Pro Logic), das eigentlich nur vier Kanäle aufweist (L, C, R mit voller Bandbreite und Effekt-Kanal mit begrenztem Frequenzbereich von 100 ... 7000 Hz), verfügt bei Dolby Digital 5.1 jeder der fünf Kanäle (L, C, R, LS, RS) über den vollen Frequenzbereich von 20 ... 20000 Hz. Die Bezeichnung „5.1“ weist mit „1“ auf den getrennten Subwoofer-Kanal (Tiefton-Kanal) hin. Durch Datenkompression wird die Datenrate insgesamt auf 384 kbit/s begrenzt.
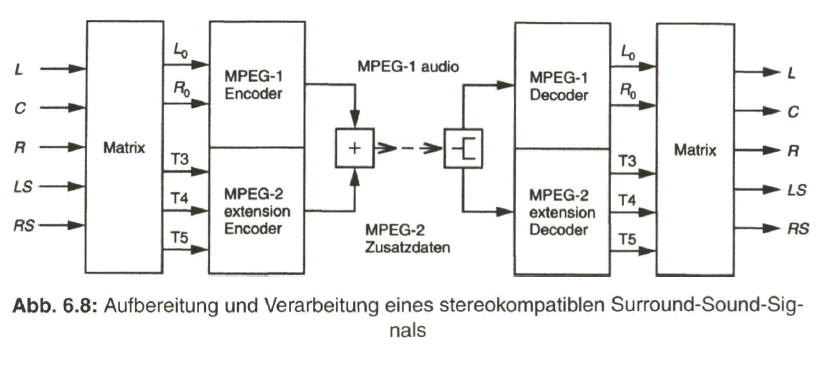
Für eine Kompatibilität mit den beiden Stereokanälen, z. B. auch in Layer I, wird der Mehrkanalton mit den Hauptkanälen L, C, Front (Left, Center, Right),
mit Anordnung der Lautsprecher vor dem Zuhörer, und LS, RS (Left Surround, Right Surround), mit Anordnung der Lautsprecher hinter dem Zuhörer in einem Coder mit spezieller Matrizierung in fünf Transportkanäle
![]()
aufbereitet, aus denen ein empfangsseitiger Decoder entweder die beiden Stereosignale L oder die fünf Surround-Signale L, C, R und LS, RS rekonstruiert.
Die eigentliche Bedeutung dieser Aufspaltung liegt in der Kompatibilität des MPEG-1-Audiosignals mit dem MPEG-2-Audiosignal, wie aus Bild 6.8 hervorgeht.
6.5 Datenraten bei digitalen Audiosignalen
Nicht komprimierte digitale PCM-Audiosignale (Linearcodierung)

Mit Datenreduktion nach MPEG-1 Audio, mögliche Abtastfrequenz neben 48 kHz auch 44,1 kHz und 32 kHz, mögliche Bitrate 192 kbit/s,... 128 kbit/s, ... 96 kbit/s,... 64 kbit/s,... 32 kbit/s, verbunden mit den Codier-Algorithmen Layer I (typ. 192 kbit/s), Layer II (typ. 128 kbit/s), Layer III (typ. 64 kbit/s, 32 kbit/s) MPEG-2 Audio, kompatible Erweiterung zu MPEG-1 Audio, mit Layer II MC und Layer III MC (Multichannel), wobei MPEG-2 Layer III mit Advanced Audio Coding (AAC) nicht kompatibel mit MPEG-1 ist, mögliche Abtastfrequenzen außer 48, 44,1 und 32 kHz auch 24, 22,05 und 16 kHz, typische Bitraten zwischen 64 kbit/s und 128 kbit/s für einen Tonkanal und 384 kbit/s (möglich, mit n x 8 kbit/s, von 320 bis 896 kbit/s) für Mehrkanalton bei Kinofilmen (Dolby Digital 5.1).
Das MP3-Format erlaubt Datenraten von 8 kbit/s bis zu 320 kbit/s. Ein Stereo-Tonsignal behält subjektiv die CD-Qualität bei einer Bitrate im Bereich von 112 bis 128 kbit/s und ist damit von den meisten Menschen nicht mehr vom Original zu unterscheiden. Annähernd CD-Qualität wird erreicht mit einer Bitrate von 96 kbit/s. Ein Mono-Tonsignal bringt mit einer Bitrate von 32 kbit/s noch ausreichende Hörqualität. Für ein Sprachsignal reichen 8 kbit/s.